 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurity-by-Design for LLM-Based Code Generation: Leveraging Internal Representations for Concept-Driven Steering Mechanisms
Mar 11, 2026Large Language Models (LLMs) show remarkable capabilities in understanding natural language and generating complex code. However, as practitioners adopt CodeLLMs for increasingly critical development tasks, research reveals that these models frequently generate functionally correct yet insecure code, posing significant security risks. While multiple approaches have been proposed to improve security in AI-based code generation, combined benchmarks show these methods remain insufficient for practical use, achieving only limited improvements in both functional correctness and security. This stems from a fundamental gap in understanding the internal mechanisms of code generation and the root causes of security vulnerabilities, forcing researchers to rely on heuristics and empirical observations. In this work, we investigate the internal representation of security concepts in CodeLLMs, revealing that models are often aware of vulnerabilities as they generate insecure code. Through systematic evaluation, we demonstrate that CodeLLMs can distinguish between security subconcepts, enabling a more fine-grained analysis than prior black-box approaches. Leveraging these insights, we propose Secure Concept Steering for CodeLLMs (SCS-Code). During token generation, SCS-Code steers LLMs' internal representations toward secure and functional code output, enabling a lightweight and modular mechanism that can be integrated into existing code models. Our approach achieves superior performance compared to state-of-the-art methods across multiple secure coding benchmarks.
DeePen: Penetration Testing for Audio Deepfake Detection
Feb 27, 2025Deepfakes - manipulated or forged audio and video media - pose significant security risks to individuals, organizations, and society at large. To address these challenges, machine learning-based classifiers are commonly employed to detect deepfake content. In this paper, we assess the robustness of such classifiers through a systematic penetration testing methodology, which we introduce as DeePen. Our approach operates without prior knowledge of or access to the target deepfake detection models. Instead, it leverages a set of carefully selected signal processing modifications - referred to as attacks - to evaluate model vulnerabilities. Using DeePen, we analyze both real-world production systems and publicly available academic model checkpoints, demonstrating that all tested systems exhibit weaknesses and can be reliably deceived by simple manipulations such as time-stretching or echo addition. Furthermore, our findings reveal that while some attacks can be mitigated by retraining detection systems with knowledge of the specific attack, others remain persistently effective. We release all associated code.
Harder or Different? Understanding Generalization of Audio Deepfake Detection
Jun 07, 2024Recent research has highlighted a key issue in speech deepfake detection: models trained on one set of deepfakes perform poorly on others. The question arises: is this due to the continuously improving quality of Text-to-Speech (TTS) models, i.e., are newer DeepFakes just 'harder' to detect? Or, is it because deepfakes generated with one model are fundamentally different to those generated using another model? We answer this question by decomposing the performance gap between in-domain and out-of-domain test data into 'hardness' and 'difference' components. Experiments performed using ASVspoof databases indicate that the hardness component is practically negligible, with the performance gap being attributed primarily to the difference component. This has direct implications for real-world deepfake detection, highlighting that merely increasing model capacity, the currently-dominant research trend, may not effectively address the generalization challenge.
A New Approach to Voice Authenticity
Feb 09, 2024

Voice faking, driven primarily by recent advances in text-to-speech (TTS) synthesis technology, poses significant societal challenges. Currently, the prevailing assumption is that unaltered human speech can be considered genuine, while fake speech comes from TTS synthesis. We argue that this binary distinction is oversimplified. For instance, altered playback speeds can be used for malicious purposes, like in the 'Drunken Nancy Pelosi' incident. Similarly, editing of audio clips can be done ethically, e.g., for brevity or summarization in news reporting or podcasts, but editing can also create misleading narratives. In this paper, we propose a conceptual shift away from the binary paradigm of audio being either 'fake' or 'real'. Instead, our focus is on pinpointing 'voice edits', which encompass traditional modifications like filters and cuts, as well as TTS synthesis and VC systems. We delineate 6 categories and curate a new challenge dataset rooted in the M-AILABS corpus, for which we present baseline detection systems. And most importantly, we argue that merely categorizing audio as fake or real is a dangerous over-simplification that will fail to move the field of speech technology forward.
MLAAD: The Multi-Language Audio Anti-Spoofing Dataset
Jan 17, 2024



Text-to-Speech (TTS) technology brings significant advantages, such as giving a voice to those with speech impairments, but also enables audio deepfakes and spoofs. The former mislead individuals and may propagate misinformation, while the latter undermine voice biometric security systems. AI-based detection can help to address these challenges by automatically differentiating between genuine and fabricated voice recordings. However, these models are only as good as their training data, which currently is severely limited due to an overwhelming concentration on English and Chinese audio in anti-spoofing databases, thus restricting its worldwide effectiveness. In response, this paper presents the Multi-Language Audio Anti-Spoof Dataset (MLAAD), created using 52 TTS models, comprising 19 different architectures, to generate 160.1 hours of synthetic voice in 23 different languages. We train and evaluate three state-of-the-art deepfake detection models with MLAAD, and observe that MLAAD demonstrates superior performance over comparable datasets like InTheWild or FakeOrReal when used as a training resource. Furthermore, in comparison with the renowned ASVspoof 2019 dataset, MLAAD proves to be a complementary resource. In tests across eight datasets, MLAAD and ASVspoof 2019 alternately outperformed each other, both excelling on four datasets. By publishing MLAAD and making trained models accessible via an interactive webserver , we aim to democratize antispoofing technology, making it accessible beyond the realm of specialists, thus contributing to global efforts against audio spoofing and deepfakes.
Physical Adversarial Examples for Multi-Camera Systems
Nov 14, 2023Neural networks build the foundation of several intelligent systems, which, however, are known to be easily fooled by adversarial examples. Recent advances made these attacks possible even in air-gapped scenarios, where the autonomous system observes its surroundings by, e.g., a camera. We extend these ideas in our research and evaluate the robustness of multi-camera setups against such physical adversarial examples. This scenario becomes ever more important with the rise in popularity of autonomous vehicles, which fuse the information of several cameras for their driving decision. While we find that multi-camera setups provide some robustness towards past attack methods, we see that this advantage reduces when optimizing on multiple perspectives at once. We propose a novel attack method that we call Transcender-MC, where we incorporate online 3D renderings and perspective projections in the training process. Moreover, we motivate that certain data augmentation techniques can facilitate the generation of successful adversarial examples even further. Transcender-MC is 11% more effective in successfully attacking multi-camera setups than state-of-the-art methods. Our findings offer valuable insights regarding the resilience of object detection in a setup with multiple cameras and motivate the need of developing adequate defense mechanisms against them.
Protecting Publicly Available Data With Machine Learning Shortcuts
Oct 30, 2023Machine-learning (ML) shortcuts or spurious correlations are artifacts in datasets that lead to very good training and test performance but severely limit the model's generalization capability. Such shortcuts are insidious because they go unnoticed due to good in-domain test performance. In this paper, we explore the influence of different shortcuts and show that even simple shortcuts are difficult to detect by explainable AI methods. We then exploit this fact and design an approach to defend online databases against crawlers: providers such as dating platforms, clothing manufacturers, or used car dealers have to deal with a professionalized crawling industry that grabs and resells data points on a large scale. We show that a deterrent can be created by deliberately adding ML shortcuts. Such augmented datasets are then unusable for ML use cases, which deters crawlers and the unauthorized use of data from the internet. Using real-world data from three use cases, we show that the proposed approach renders such collected data unusable, while the shortcut is at the same time difficult to notice in human perception. Thus, our proposed approach can serve as a proactive protection against illegitimate data crawling.
Complex-valued neural networks for voice anti-spoofing
Aug 22, 2023Current anti-spoofing and audio deepfake detection systems use either magnitude spectrogram-based features (such as CQT or Melspectrograms) or raw audio processed through convolution or sinc-layers. Both methods have drawbacks: magnitude spectrograms discard phase information, which affects audio naturalness, and raw-feature-based models cannot use traditional explainable AI methods. This paper proposes a new approach that combines the benefits of both methods by using complex-valued neural networks to process the complex-valued, CQT frequency-domain representation of the input audio. This method retains phase information and allows for explainable AI methods. Results show that this approach outperforms previous methods on the "In-the-Wild" anti-spoofing dataset and enables interpretation of the results through explainable AI. Ablation studies confirm that the model has learned to use phase information to detect voice spoofing.
Shortcut Detection with Variational Autoencoders
Feb 08, 2023For real-world applications of machine learning (ML), it is essential that models make predictions based on well-generalizing features rather than spurious correlations in the data. The identification of such spurious correlations, also known as shortcuts, is a challenging problem and has so far been scarcely addressed. In this work, we present a novel approach to detect shortcuts in image and audio datasets by leveraging variational autoencoders (VAEs). The disentanglement of features in the latent space of VAEs allows us to discover correlations in datasets and semi-automatically evaluate them for ML shortcuts. We demonstrate the applicability of our method on several real-world datasets and identify shortcuts that have not been discovered before. Based on these findings, we also investigate the construction of shortcut adversarial examples.
Introducing Model Inversion Attacks on Automatic Speaker Recognition
Jan 09, 2023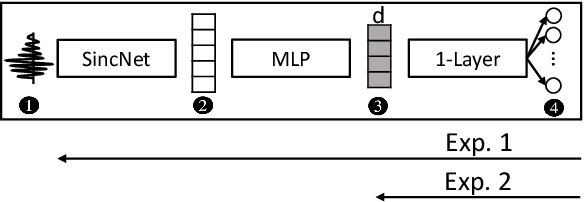
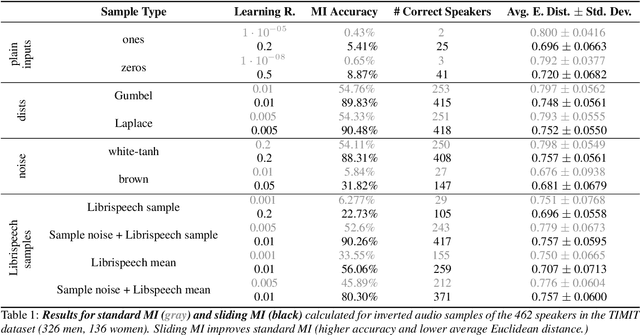
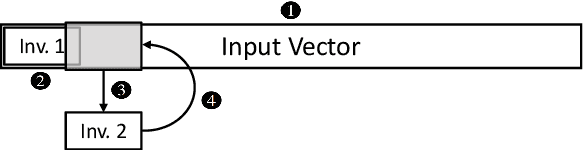
Model inversion (MI) attacks allow to reconstruct average per-class representations of a machine learning (ML) model's training data. It has been shown that in scenarios where each class corresponds to a different individual, such as face classifiers, this represents a severe privacy risk. In this work, we explore a new application for MI: the extraction of speakers' voices from a speaker recognition system. We present an approach to (1) reconstruct audio samples from a trained ML model and (2) extract intermediate voice feature representations which provide valuable insights into the speakers' biometrics. Therefore, we propose an extension of MI attacks which we call sliding model inversion. Our sliding MI extends standard MI by iteratively inverting overlapping chunks of the audio samples and thereby leveraging the sequential properties of audio data for enhanced inversion performance. We show that one can use the inverted audio data to generate spoofed audio samples to impersonate a speaker, and execute voice-protected commands for highly secured systems on their behalf. To the best of our knowledge, our work is the first one extending MI attacks to audio data, and our results highlight the security risks resulting from the extraction of the biometric data in that setup.
* for associated pdf, see https://www.isca-speech.org/archive/pdfs/spsc_2022/pizzi22_spsc.pdf