 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Open is Open TTS? A Practical Evaluation of Open Source TTS Tools for Romanian
Mar 25, 2026Open-source text-to-speech (TTS) frameworks have emerged as highly adaptable platforms for developing speech synthesis systems across a wide range of languages. However, their applicability is not uniform -- particularly when the target language is under-resourced or when computational resources are constrained. In this study, we systematically assess the feasibility of building novel TTS models using four widely adopted open-source architectures: FastPitch, VITS, Grad-TTS, and Matcha-TTS. Our evaluation spans multiple dimensions, including qualitative aspects such as ease of installation, dataset preparation, and hardware requirements, as well as quantitative assessments of synthesis quality for Romanian. We employ both objective metrics and subjective listening tests to evaluate intelligibility, speaker similarity, and naturalness of the generated speech. The results reveal significant challenges in tool chain setup, data preprocessing, and computational efficiency, which can hinder adoption in low-resource contexts. By grounding the analysis in reproducible protocols and accessible evaluation criteria, this work aims to inform best practices and promote more inclusive, language-diverse TTS development. All information needed to reproduce this study (i.e. code and data) are available in our git repository: https://gitlab.com/opentts_ragman/OpenTTS
Understanding the strengths and weaknesses of SSL models for audio deepfake model attribution
Mar 13, 2026Audio deepfake model attribution aims to mitigate the misuse of synthetic speech by identifying the source model responsible for generating a given audio sample, enabling accountability and informing vendors. The task is challenging, but self-supervised learning (SSL)-derived acoustic features have demonstrated state-of-the-art attribution capabilities, yet the underlying factors driving their success and the limits of their discriminative power remain unclear. In this paper, we systematically investigate how SSL-derived features capture architectural signatures in audio deepfakes. By controlling multiple dimensions of the audio generation process we reveal how subtle perturbations in model checkpoints, text prompts, vocoders, or speaker identity influence attribution. Our results provide new insights into the robustness, biases, and limitations of SSL-based deepfake attribution, highlighting both its strengths and vulnerabilities in realistic scenarios.
Unmasking real-world audio deepfakes: A data-centric approach
Jun 11, 2025

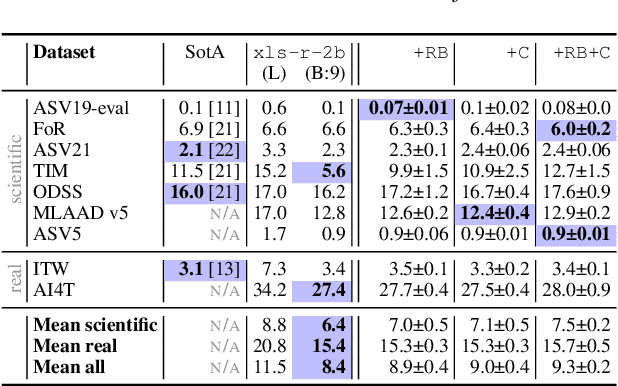
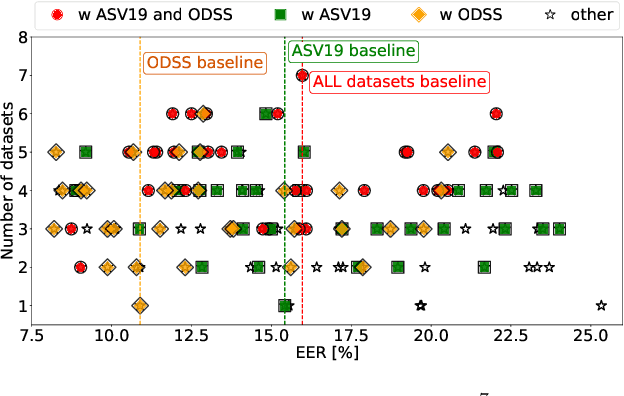
The growing prevalence of real-world deepfakes presents a critical challenge for existing detection systems, which are often evaluated on datasets collected just for scientific purposes. To address this gap, we introduce a novel dataset of real-world audio deepfakes. Our analysis reveals that these real-world examples pose significant challenges, even for the most performant detection models. Rather than increasing model complexity or exhaustively search for a better alternative, in this work we focus on a data-centric paradigm, employing strategies like dataset curation, pruning, and augmentation to improve model robustness and generalization. Through these methods, we achieve a 55% relative reduction in EER on the In-the-Wild dataset, reaching an absolute EER of 1.7%, and a 63% reduction on our newly proposed real-world deepfakes dataset, AI4T. These results highlight the transformative potential of data-centric approaches in enhancing deepfake detection for real-world applications. Code and data available at: https://github.com/davidcombei/AI4T.
TADA: Training-free Attribution and Out-of-Domain Detection of Audio Deepfakes
Jun 06, 2025Deepfake detection has gained significant attention across audio, text, and image modalities, with high accuracy in distinguishing real from fake. However, identifying the exact source--such as the system or model behind a deepfake--remains a less studied problem. In this paper, we take a significant step forward in audio deepfake model attribution or source tracing by proposing a training-free, green AI approach based entirely on k-Nearest Neighbors (kNN). Leveraging a pre-trained self-supervised learning (SSL) model, we show that grouping samples from the same generator is straightforward--we obtain an 0.93 F1-score across five deepfake datasets. The method also demonstrates strong out-of-domain (OOD) detection, effectively identifying samples from unseen models at an F1-score of 0.84. We further analyse these results in a multi-dimensional approach and provide additional insights. All code and data protocols used in this work are available in our open repository: https://github.com/adrianastan/tada/.
Replay Attacks Against Audio Deepfake Detection
May 20, 2025

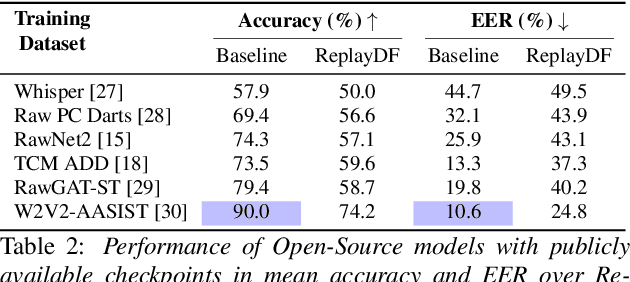
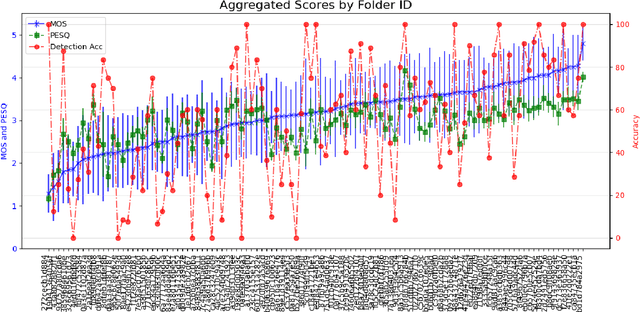
We show how replay attacks undermine audio deepfake detection: By playing and re-recording deepfake audio through various speakers and microphones, we make spoofed samples appear authentic to the detection model. To study this phenomenon in more detail, we introduce ReplayDF, a dataset of recordings derived from M-AILABS and MLAAD, featuring 109 speaker-microphone combinations across six languages and four TTS models. It includes diverse acoustic conditions, some highly challenging for detection. Our analysis of six open-source detection models across five datasets reveals significant vulnerability, with the top-performing W2V2-AASIST model's Equal Error Rate (EER) surging from 4.7% to 18.2%. Even with adaptive Room Impulse Response (RIR) retraining, performance remains compromised with an 11.0% EER. We release ReplayDF for non-commercial research use.
DeePen: Penetration Testing for Audio Deepfake Detection
Feb 27, 2025Deepfakes - manipulated or forged audio and video media - pose significant security risks to individuals, organizations, and society at large. To address these challenges, machine learning-based classifiers are commonly employed to detect deepfake content. In this paper, we assess the robustness of such classifiers through a systematic penetration testing methodology, which we introduce as DeePen. Our approach operates without prior knowledge of or access to the target deepfake detection models. Instead, it leverages a set of carefully selected signal processing modifications - referred to as attacks - to evaluate model vulnerabilities. Using DeePen, we analyze both real-world production systems and publicly available academic model checkpoints, demonstrating that all tested systems exhibit weaknesses and can be reliably deceived by simple manipulations such as time-stretching or echo addition. Furthermore, our findings reveal that while some attacks can be mitigated by retraining detection systems with knowledge of the specific attack, others remain persistently effective. We release all associated code.
Efficient training strategies for natural sounding speech synthesis and speaker adaptation based on FastPitch
Oct 09, 2024



This paper focuses on adapting the functionalities of the FastPitch model to the Romanian language; extending the set of speakers from one to eighteen; synthesising speech using an anonymous identity; and replicating the identities of new, unseen speakers. During this work, the effects of various configurations and training strategies were tested and discussed, along with their advantages and weaknesses. Finally, we settled on a new configuration, built on top of the FastPitch architecture, capable of producing natural speech synthesis, for both known (identities from the training dataset) and unknown (identities learnt through short reference samples) speakers. The anonymous speaker can be used for text-to-speech synthesis, if one wants to cancel out the identity information while keeping the semantic content whole and clear. At last, we discussed possible limitations of our work, which will form the basis for future investigations and advancements.
TBDM-Net: Bidirectional Dense Networks with Gender Information for Speech Emotion Recognition
Sep 16, 2024



This paper presents a novel deep neural network-based architecture tailored for Speech Emotion Recognition (SER). The architecture capitalises on dense interconnections among multiple layers of bidirectional dilated convolutions. A linear kernel dynamically fuses the outputs of these layers to yield the final emotion class prediction. This innovative architecture is denoted as TBDM-Net: Temporally-Aware Bi-directional Dense Multi-Scale Network. We conduct a comprehensive performance evaluation of TBDM-Net, including an ablation study, across six widely-acknowledged SER datasets for unimodal speech emotion recognition. Additionally, we explore the influence of gender-informed emotion prediction by appending either golden or predicted gender labels to the architecture's inputs or predictions. The implementation of TBDM-Net is accessible at: https://github.com/adrianastan/tbdm-net
WavLM model ensemble for audio deepfake detection
Aug 14, 2024



Audio deepfake detection has become a pivotal task over the last couple of years, as many recent speech synthesis and voice cloning systems generate highly realistic speech samples, thus enabling their use in malicious activities. In this paper we address the issue of audio deepfake detection as it was set in the ASVspoof5 challenge. First, we benchmark ten types of pretrained representations and show that the self-supervised representations stemming from the wav2vec2 and wavLM families perform best. Of the two, wavLM is better when restricting the pretraining data to LibriSpeech, as required by the challenge rules. To further improve performance, we finetune the wavLM model for the deepfake detection task. We extend the ASVspoof5 dataset with samples from other deepfake detection datasets and apply data augmentation. Our final challenge submission consists of a late fusion combination of four models and achieves an equal error rate of 6.56% and 17.08% on the two evaluation sets.
An analysis of large speech models-based representations for speech emotion recognition
Nov 01, 2023

Large speech models-derived features have recently shown increased performance over signal-based features across multiple downstream tasks, even when the networks are not finetuned towards the target task. In this paper we show the results of an analysis of several signal- and neural models-derived features for speech emotion recognition. We use pretrained models and explore their inherent potential abstractions of emotions. Simple classification methods are used so as to not interfere or add knowledge to the task. We show that, even without finetuning, some of these large neural speech models' representations can enclose information that enables performances close to, and even beyond state-of-the-art results across six standard speech emotion recognition datasets.