 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircumventing shortcuts in audio-visual deepfake detection datasets with unsupervised learning
Nov 29, 2024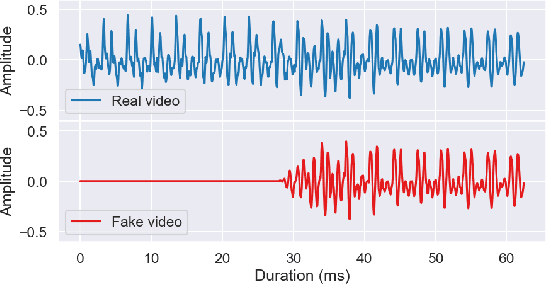
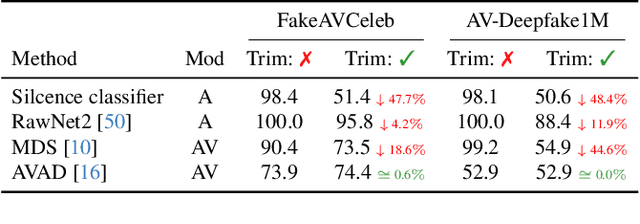
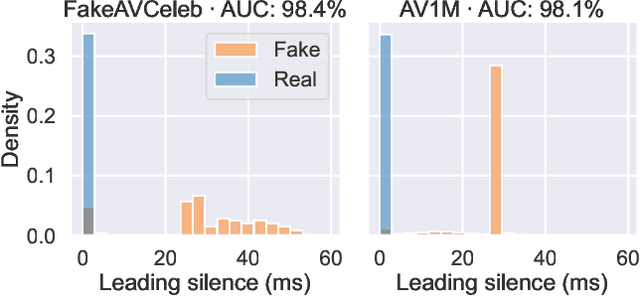

Good datasets are essential for developing and benchmarking any machine learning system. Their importance is even more extreme for safety critical applications such as deepfake detection - the focus of this paper. Here we reveal that two of the most widely used audio-video deepfake datasets suffer from a previously unidentified spurious feature: the leading silence. Fake videos start with a very brief moment of silence and based on this feature alone, we can separate the real and fake samples almost perfectly. As such, previous audio-only and audio-video models exploit the presence of silence in the fake videos and consequently perform worse when the leading silence is removed. To circumvent latching on such unwanted artifact and possibly other unrevealed ones we propose a shift from supervised to unsupervised learning by training models exclusively on real data. We show that by aligning self-supervised audio-video representations we remove the risk of relying on dataset-specific biases and improve robustness in deepfake detection.
DeCLIP: Decoding CLIP representations for deepfake localization
Sep 12, 2024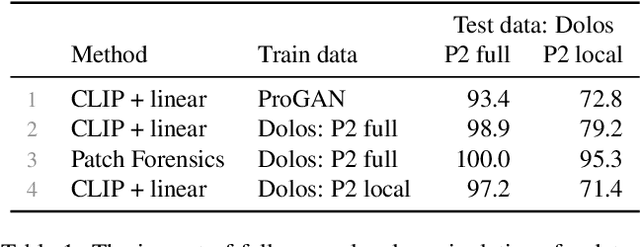
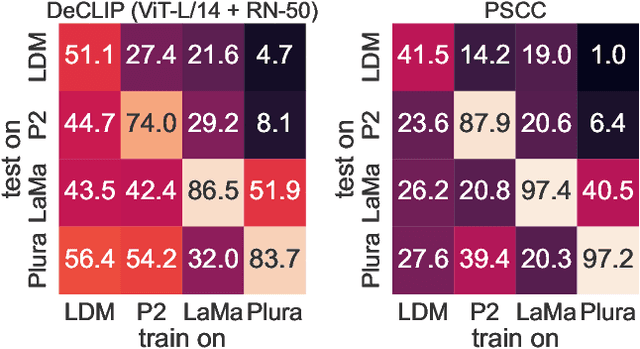
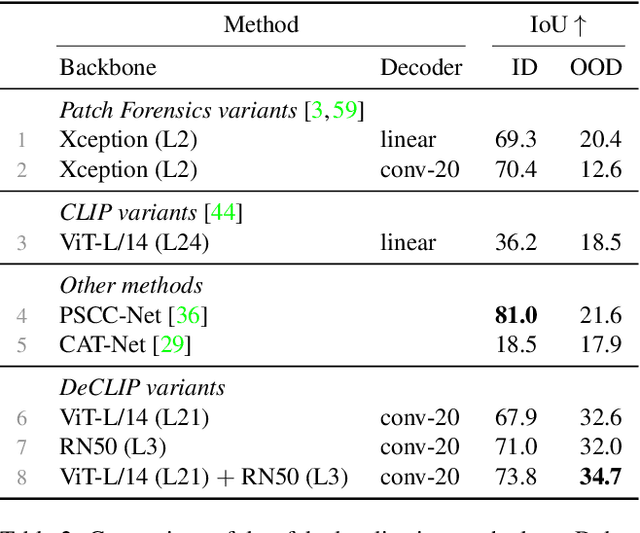

Generative models can create entirely new images, but they can also partially modify real images in ways that are undetectable to the human eye. In this paper, we address the challenge of automatically detecting such local manipulations. One of the most pressing problems in deepfake detection remains the ability of models to generalize to different classes of generators. In the case of fully manipulated images, representations extracted from large self-supervised models (such as CLIP) provide a promising direction towards more robust detectors. Here, we introduce DeCLIP, a first attempt to leverage such large pretrained features for detecting local manipulations. We show that, when combined with a reasonably large convolutional decoder, pretrained self-supervised representations are able to perform localization and improve generalization capabilities over existing methods. Unlike previous work, our approach is able to perform localization on the challenging case of latent diffusion models, where the entire image is affected by the fingerprint of the generator. Moreover, we observe that this type of data, which combines local semantic information with a global fingerprint, provides more stable generalization than other categories of generative methods.
Weakly-supervised deepfake localization in diffusion-generated images
Nov 13, 2023
The remarkable generative capabilities of denoising diffusion models have raised new concerns regarding the authenticity of the images we see every day on the Internet. However, the vast majority of existing deepfake detection models are tested against previous generative approaches (e.g. GAN) and usually provide only a "fake" or "real" label per image. We believe a more informative output would be to augment the per-image label with a localization map indicating which regions of the input have been manipulated. To this end, we frame this task as a weakly-supervised localization problem and identify three main categories of methods (based on either explanations, local scores or attention), which we compare on an equal footing by using the Xception network as the common backbone architecture. We provide a careful analysis of all the main factors that parameterize the design space: choice of method, type of supervision, dataset and generator used in the creation of manipulated images; our study is enabled by constructing datasets in which only one of the components is varied. Our results show that weakly-supervised localization is attainable, with the best performing detection method (based on local scores) being less sensitive to the looser supervision than to the mismatch in terms of dataset or generator.
Towards generalisable and calibrated synthetic speech detection with self-supervised representations
Sep 11, 2023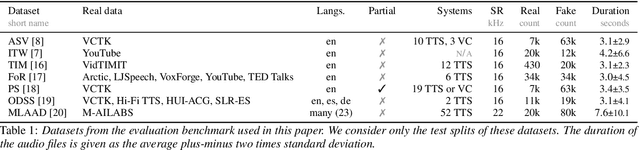



Generalisation -- the ability of a model to perform well on unseen data -- is crucial for building reliable deep fake detectors. However, recent studies have shown that the current audio deep fake models fall short of this desideratum. In this paper we show that pretrained self-supervised representations followed by a simple logistic regression classifier achieve strong generalisation capabilities, reducing the equal error rate from 30% to 8% on the newly introduced In-the-Wild dataset. Importantly, this approach also produces considerably better calibrated models when compared to previous approaches. This means that we can trust our model's predictions more and use these for downstream tasks, such as uncertainty estimation. In particular, we show that the entropy of the estimated probabilities provides a reliable way of rejecting uncertain samples and further improving the accuracy.
Reconstructing Three-Dimensional Models of Interacting Humans
Aug 04, 2023



Understanding 3d human interactions is fundamental for fine-grained scene analysis and behavioural modeling. However, most of the existing models predict incorrect, lifeless 3d estimates, that miss the subtle human contact aspects--the essence of the event--and are of little use for detailed behavioral understanding. This paper addresses such issues with several contributions: (1) we introduce models for interaction signature estimation (ISP) encompassing contact detection, segmentation, and 3d contact signature prediction; (2) we show how such components can be leveraged to ensure contact consistency during 3d reconstruction; (3) we construct several large datasets for learning and evaluating 3d contact prediction and reconstruction methods; specifically, we introduce CHI3D, a lab-based accurate 3d motion capture dataset with 631 sequences containing $2,525$ contact events, $728,664$ ground truth 3d poses, as well as FlickrCI3D, a dataset of $11,216$ images, with $14,081$ processed pairs of people, and $81,233$ facet-level surface correspondences. Finally, (4) we propose methodology for recovering the ground-truth pose and shape of interacting people in a controlled setup and (5) annotate all 3d interaction motions in CHI3D with textual descriptions. Motion data in multiple formats (GHUM and SMPLX parameters, Human3.6m 3d joints) is made available for research purposes at \url{https://ci3d.imar.ro}, together with an evaluation server and a public benchmark.
Learning Complex 3D Human Self-Contact
Dec 18, 2020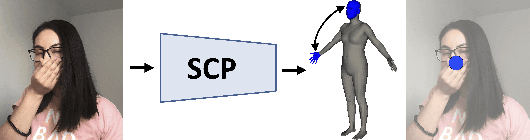

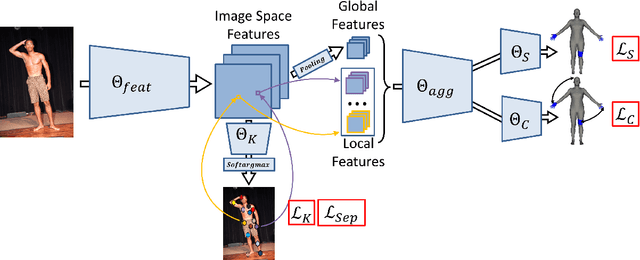

Monocular estimation of three dimensional human self-contact is fundamental for detailed scene analysis including body language understanding and behaviour modeling. Existing 3d reconstruction methods do not focus on body regions in self-contact and consequently recover configurations that are either far from each other or self-intersecting, when they should just touch. This leads to perceptually incorrect estimates and limits impact in those very fine-grained analysis domains where detailed 3d models are expected to play an important role. To address such challenges we detect self-contact and design 3d losses to explicitly enforce it. Specifically, we develop a model for Self-Contact Prediction (SCP), that estimates the body surface signature of self-contact, leveraging the localization of self-contact in the image, during both training and inference. We collect two large datasets to support learning and evaluation: (1) HumanSC3D, an accurate 3d motion capture repository containing $1,032$ sequences with $5,058$ contact events and $1,246,487$ ground truth 3d poses synchronized with images collected from multiple views, and (2) FlickrSC3D, a repository of $3,969$ images, containing $25,297$ surface-to-surface correspondences with annotated image spatial support. We also illustrate how more expressive 3d reconstructions can be recovered under self-contact signature constraints and present monocular detection of face-touch as one of the multiple applications made possible by more accurate self-contact models.
Human Synthesis and Scene Compositing
Oct 18, 2019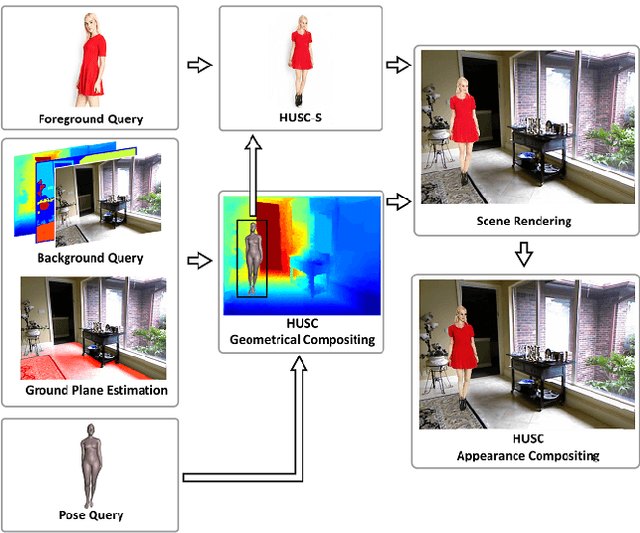
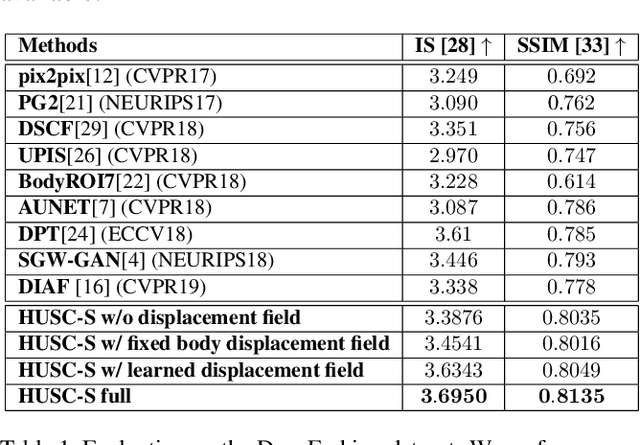
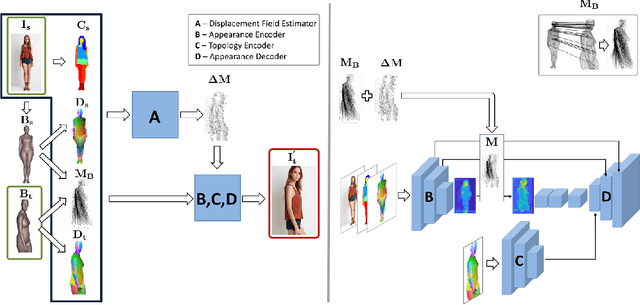
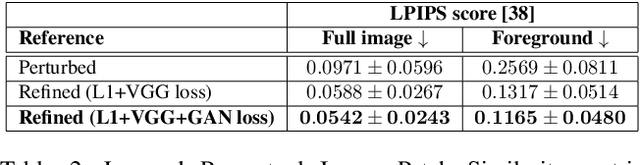
Generating good quality and geometrically plausible synthetic images of humans with the ability to control appearance, pose and shape parameters, has become increasingly important for a variety of tasks ranging from photo editing, fashion virtual try-on, to special effects and image compression. In this paper, we propose HUSC, a HUman Synthesis and Scene Compositing framework for the realistic synthesis of humans with different appearance, in novel poses and scenes. Central to our formulation is 3d reasoning for both people and scenes, in order to produce realistic collages, by correctly modeling perspective effects and occlusion, by taking into account scene semantics and by adequately handling relative scales. Conceptually our framework consists of three components: (1) a human image synthesis model with controllable pose and appearance, based on a parametric representation, (2) a person insertion procedure that leverages the geometry and semantics of the 3d scene, and (3) an appearance compositing process to create a seamless blending between the colors of the scene and the generated human image, and avoid visual artifacts. The performance of our framework is supported by both qualitative and quantitative results, in particular state-of-the art synthesis scores for the DeepFashion dataset.