 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircumventing shortcuts in audio-visual deepfake detection datasets with unsupervised learning
Nov 29, 2024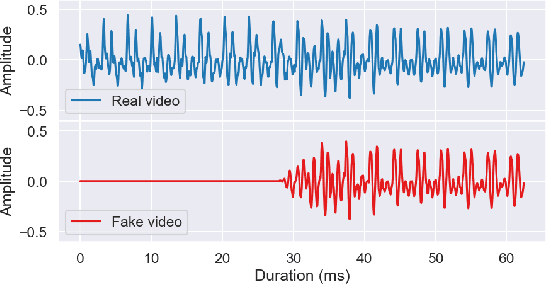
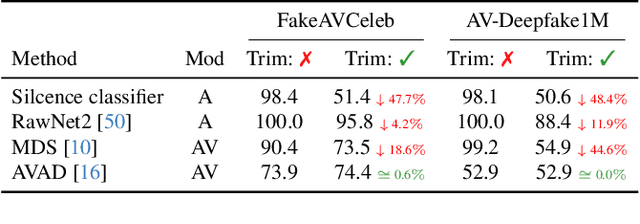
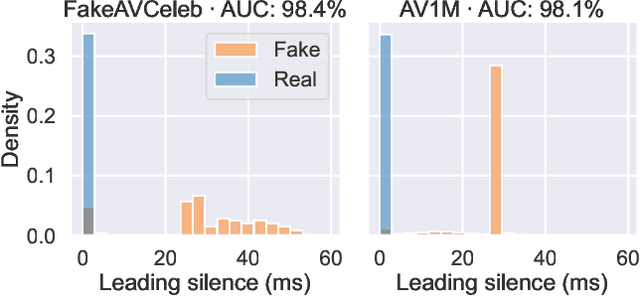

Good datasets are essential for developing and benchmarking any machine learning system. Their importance is even more extreme for safety critical applications such as deepfake detection - the focus of this paper. Here we reveal that two of the most widely used audio-video deepfake datasets suffer from a previously unidentified spurious feature: the leading silence. Fake videos start with a very brief moment of silence and based on this feature alone, we can separate the real and fake samples almost perfectly. As such, previous audio-only and audio-video models exploit the presence of silence in the fake videos and consequently perform worse when the leading silence is removed. To circumvent latching on such unwanted artifact and possibly other unrevealed ones we propose a shift from supervised to unsupervised learning by training models exclusively on real data. We show that by aligning self-supervised audio-video representations we remove the risk of relying on dataset-specific biases and improve robustness in deepfake detection.
DeCLIP: Decoding CLIP representations for deepfake localization
Sep 12, 2024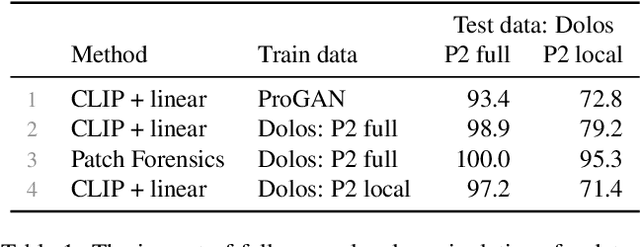
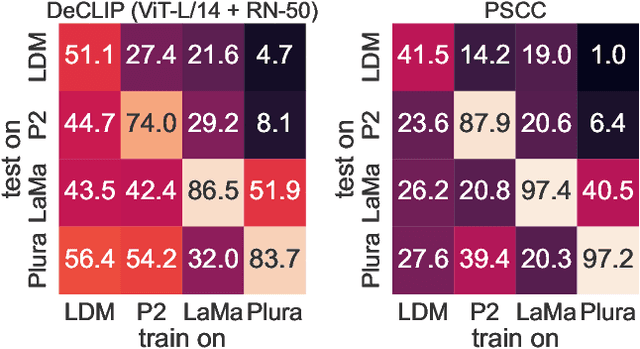
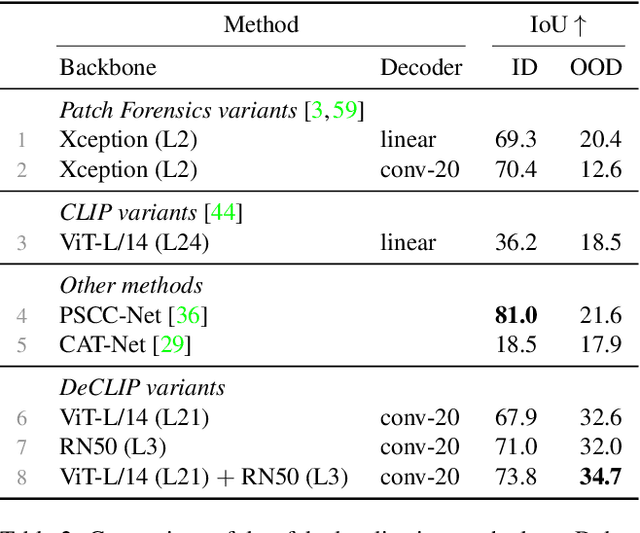

Generative models can create entirely new images, but they can also partially modify real images in ways that are undetectable to the human eye. In this paper, we address the challenge of automatically detecting such local manipulations. One of the most pressing problems in deepfake detection remains the ability of models to generalize to different classes of generators. In the case of fully manipulated images, representations extracted from large self-supervised models (such as CLIP) provide a promising direction towards more robust detectors. Here, we introduce DeCLIP, a first attempt to leverage such large pretrained features for detecting local manipulations. We show that, when combined with a reasonably large convolutional decoder, pretrained self-supervised representations are able to perform localization and improve generalization capabilities over existing methods. Unlike previous work, our approach is able to perform localization on the challenging case of latent diffusion models, where the entire image is affected by the fingerprint of the generator. Moreover, we observe that this type of data, which combines local semantic information with a global fingerprint, provides more stable generalization than other categories of generative methods.
Stylist: Style-Driven Feature Ranking for Robust Novelty Detection
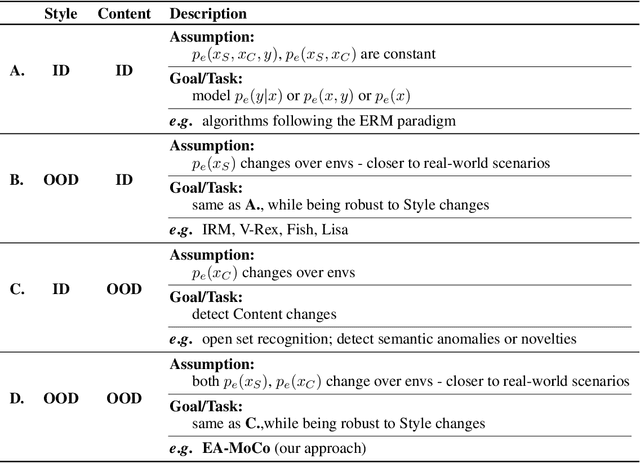
Oct 05, 2023Novelty detection aims at finding samples that differ in some form from the distribution of seen samples. But not all changes are created equal. Data can suffer a multitude of distribution shifts, and we might want to detect only some types of relevant changes. Similar to works in out-of-distribution generalization, we propose to use the formalization of separating into semantic or content changes, that are relevant to our task, and style changes, that are irrelevant. Within this formalization, we define the robust novelty detection as the task of finding semantic changes while being robust to style distributional shifts. Leveraging pretrained, large-scale model representations, we introduce Stylist, a novel method that focuses on dropping environment-biased features. First, we compute a per-feature score based on the feature distribution distances between environments. Next, we show that our selection manages to remove features responsible for spurious correlations and improve novelty detection performance. For evaluation, we adapt domain generalization datasets to our task and analyze the methods behaviors. We additionally built a large synthetic dataset where we have control over the spurious correlations degree. We prove that our selection mechanism improves novelty detection algorithms across multiple datasets, containing both stylistic and content shifts.
Environment-biased Feature Ranking for Novelty Detection Robustness
Sep 21, 2023



We tackle the problem of robust novelty detection, where we aim to detect novelties in terms of semantic content while being invariant to changes in other, irrelevant factors. Specifically, we operate in a setup with multiple environments, where we determine the set of features that are associated more with the environments, rather than to the content relevant for the task. Thus, we propose a method that starts with a pretrained embedding and a multi-env setup and manages to rank the features based on their environment-focus. First, we compute a per-feature score based on the feature distribution variance between envs. Next, we show that by dropping the highly scored ones, we manage to remove spurious correlations and improve the overall performance by up to 6%, both in covariance and sub-population shift cases, both for a real and a synthetic benchmark, that we introduce for this task.
Env-Aware Anomaly Detection: Ignore Style Changes, Stay True to Content!
Oct 06, 2022
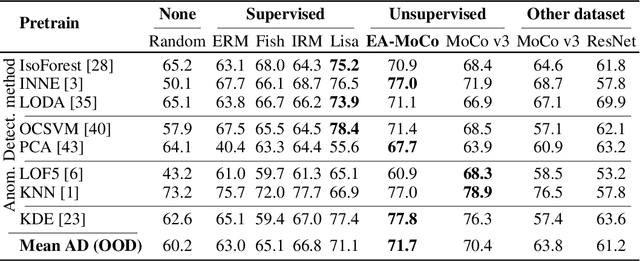
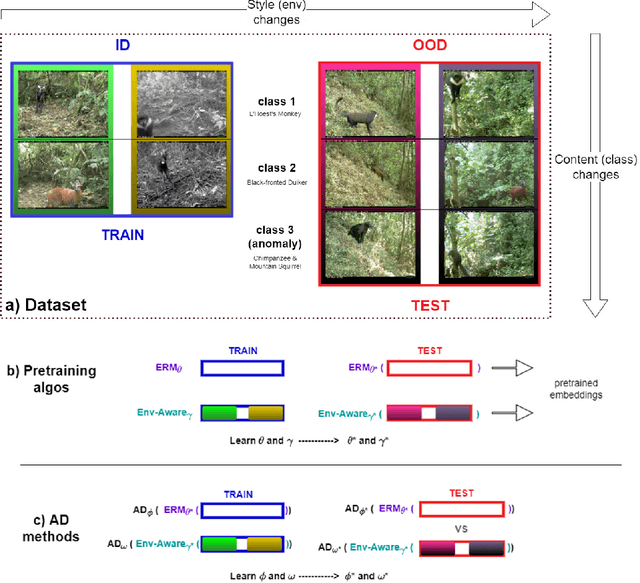
We introduce a formalization and benchmark for the unsupervised anomaly detection task in the distribution-shift scenario. Our work builds upon the iWildCam dataset, and, to the best of our knowledge, we are the first to propose such an approach for visual data. We empirically validate that environment-aware methods perform better in such cases when compared with the basic Empirical Risk Minimization (ERM). We next propose an extension for generating positive samples for contrastive methods that considers the environment labels when training, improving the ERM baseline score by 8.7%.