 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronoGraph: A Real-World Graph-Based Multivariate Time Series Dataset
Sep 04, 2025We present ChronoGraph, a graph-structured multivariate time series forecasting dataset built from real-world production microservices. Each node is a service that emits a multivariate stream of system-level performance metrics, capturing CPU, memory, and network usage patterns, while directed edges encode dependencies between services. The primary task is forecasting future values of these signals at the service level. In addition, ChronoGraph provides expert-annotated incident windows as anomaly labels, enabling evaluation of anomaly detection methods and assessment of forecast robustness during operational disruptions. Compared to existing benchmarks from industrial control systems or traffic and air-quality domains, ChronoGraph uniquely combines (i) multivariate time series, (ii) an explicit, machine-readable dependency graph, and (iii) anomaly labels aligned with real incidents. We report baseline results spanning forecasting models, pretrained time-series foundation models, and standard anomaly detectors. ChronoGraph offers a realistic benchmark for studying structure-aware forecasting and incident-aware evaluation in microservice systems.
ConceptDrift: Uncovering Biases through the Lens of Foundational Models
Oct 24, 2024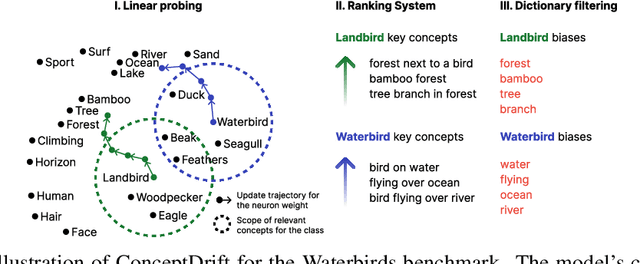


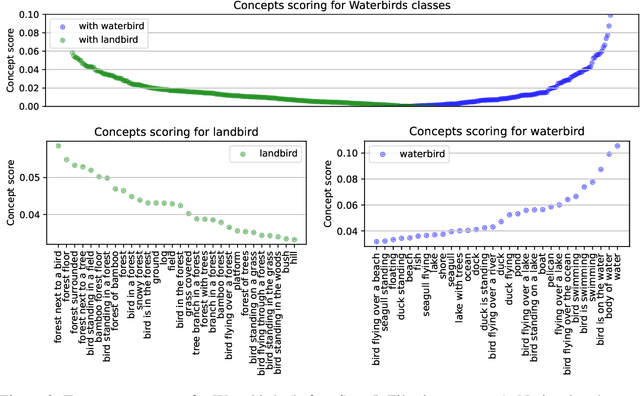
Datasets and pre-trained models come with intrinsic biases. Most methods rely on spotting them by analysing misclassified samples, in a semi-automated human-computer validation. In contrast, we propose ConceptDrift, a method which analyzes the weights of a linear probe, learned on top a foundational model. We capitalize on the weight update trajectory, which starts from the embedding of the textual representation of the class, and proceeds to drift towards embeddings that disclose hidden biases. Different from prior work, with this approach we can pin-point unwanted correlations from a dataset, providing more than just possible explanations for the wrong predictions. We empirically prove the efficacy of our method, by significantly improving zero-shot performance with biased-augmented prompting. Our method is not bounded to a single modality, and we experiment in this work with both image (Waterbirds, CelebA, Nico++) and text datasets (CivilComments).
Stylist: Style-Driven Feature Ranking for Robust Novelty Detection
Oct 05, 2023Novelty detection aims at finding samples that differ in some form from the distribution of seen samples. But not all changes are created equal. Data can suffer a multitude of distribution shifts, and we might want to detect only some types of relevant changes. Similar to works in out-of-distribution generalization, we propose to use the formalization of separating into semantic or content changes, that are relevant to our task, and style changes, that are irrelevant. Within this formalization, we define the robust novelty detection as the task of finding semantic changes while being robust to style distributional shifts. Leveraging pretrained, large-scale model representations, we introduce Stylist, a novel method that focuses on dropping environment-biased features. First, we compute a per-feature score based on the feature distribution distances between environments. Next, we show that our selection manages to remove features responsible for spurious correlations and improve novelty detection performance. For evaluation, we adapt domain generalization datasets to our task and analyze the methods behaviors. We additionally built a large synthetic dataset where we have control over the spurious correlations degree. We prove that our selection mechanism improves novelty detection algorithms across multiple datasets, containing both stylistic and content shifts.
Environment-biased Feature Ranking for Novelty Detection Robustness
Sep 21, 2023



We tackle the problem of robust novelty detection, where we aim to detect novelties in terms of semantic content while being invariant to changes in other, irrelevant factors. Specifically, we operate in a setup with multiple environments, where we determine the set of features that are associated more with the environments, rather than to the content relevant for the task. Thus, we propose a method that starts with a pretrained embedding and a multi-env setup and manages to rank the features based on their environment-focus. First, we compute a per-feature score based on the feature distribution variance between envs. Next, we show that by dropping the highly scored ones, we manage to remove spurious correlations and improve the overall performance by up to 6%, both in covariance and sub-population shift cases, both for a real and a synthetic benchmark, that we introduce for this task.
Learning a Fast 3D Spectral Approach to Object Segmentation and Tracking over Space and Time
Dec 15, 2022

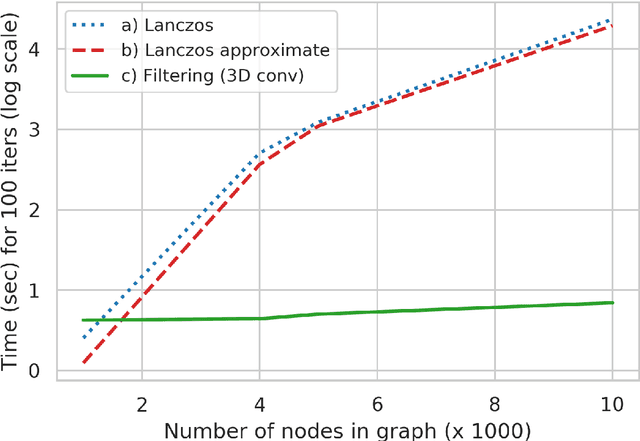

We pose video object segmentation as spectral graph clustering in space and time, with one graph node for each pixel and edges forming local space-time neighborhoods. We claim that the strongest cluster in this video graph represents the salient object. We start by introducing a novel and efficient method based on 3D filtering for approximating the spectral solution, as the principal eigenvector of the graph's adjacency matrix, without explicitly building the matrix. This key property allows us to have a fast parallel implementation on GPU, orders of magnitude faster than classical approaches for computing the eigenvector. Our motivation for a spectral space-time clustering approach, unique in video semantic segmentation literature, is that such clustering is dedicated to preserving object consistency over time, which we evaluate using our novel segmentation consistency measure. Further on, we show how to efficiently learn the solution over multiple input feature channels. Finally, we extend the formulation of our approach beyond the segmentation task, into the realm of object tracking. In extensive experiments we show significant improvements over top methods, as well as over powerful ensembles that combine them, achieving state-of-the-art on multiple benchmarks, both for tracking and segmentation.
Env-Aware Anomaly Detection: Ignore Style Changes, Stay True to Content!
Oct 06, 2022
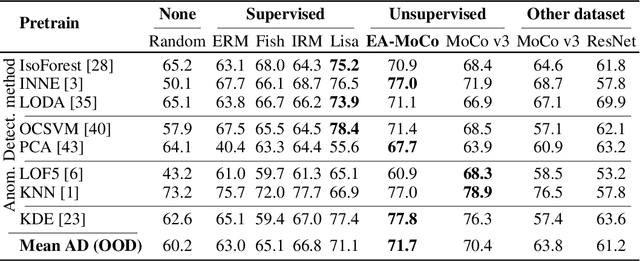
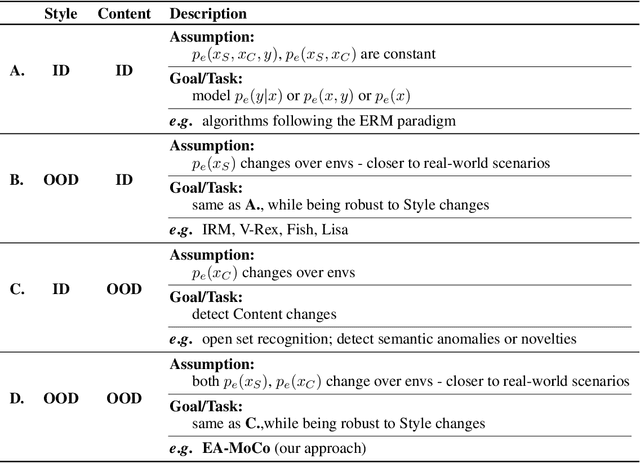
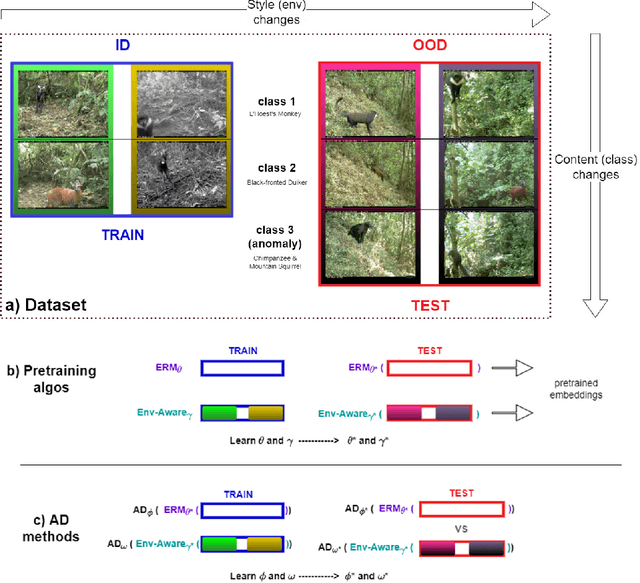
We introduce a formalization and benchmark for the unsupervised anomaly detection task in the distribution-shift scenario. Our work builds upon the iWildCam dataset, and, to the best of our knowledge, we are the first to propose such an approach for visual data. We empirically validate that environment-aware methods perform better in such cases when compared with the basic Empirical Risk Minimization (ERM). We next propose an extension for generating positive samples for contrastive methods that considers the environment labels when training, improving the ERM baseline score by 8.7%.
AnoShift: A Distribution Shift Benchmark for Unsupervised Anomaly Detection
Jun 30, 2022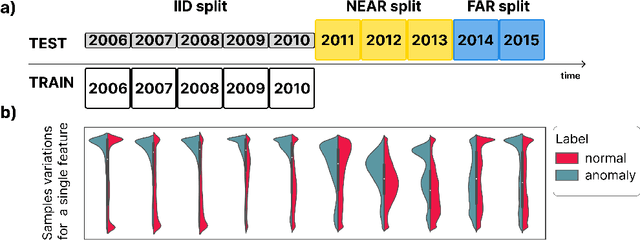

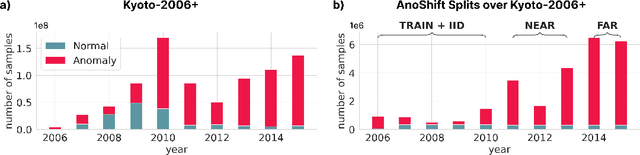
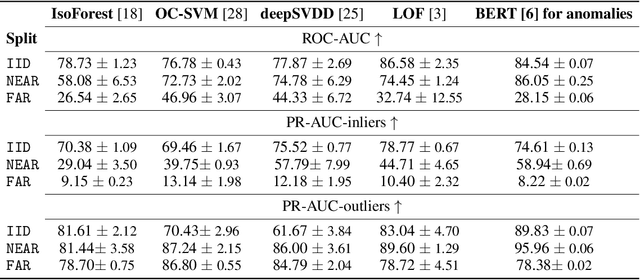
Analyzing the distribution shift of data is a growing research direction in nowadays Machine Learning, leading to emerging new benchmarks that focus on providing a suitable scenario for studying the generalization properties of ML models. The existing benchmarks are focused on supervised learning, and to the best of our knowledge, there is none for unsupervised learning. Therefore, we introduce an unsupervised anomaly detection benchmark with data that shifts over time, built over Kyoto-2006+, a traffic dataset for network intrusion detection. This kind of data meets the premise of shifting the input distribution: it covers a large time span ($10$ years), with naturally occurring changes over time (\eg users modifying their behavior patterns, and software updates). We first highlight the non-stationary nature of the data, using a basic per-feature analysis, t-SNE, and an Optimal Transport approach for measuring the overall distribution distances between years. Next, we propose AnoShift, a protocol splitting the data in IID, NEAR, and FAR testing splits. We validate the performance degradation over time with diverse models (MLM to classical Isolation Forest). Finally, we show that by acknowledging the distribution shift problem and properly addressing it, the performance can be improved compared to the classical IID training (by up to $3\%$, on average). Dataset and code are available at https://github.com/bit-ml/AnoShift/.
Transferring BERT-like Transformers' Knowledge for Authorship Verification
Dec 09, 2021

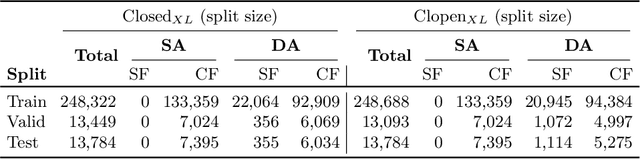

The task of identifying the author of a text spans several decades and was tackled using linguistics, statistics, and, more recently, machine learning. Inspired by the impressive performance gains across a broad range of natural language processing tasks and by the recent availability of the PAN large-scale authorship dataset, we first study the effectiveness of several BERT-like transformers for the task of authorship verification. Such models prove to achieve very high scores consistently. Next, we empirically show that they focus on topical clues rather than on author writing style characteristics, taking advantage of existing biases in the dataset. To address this problem, we provide new splits for PAN-2020, where training and test data are sampled from disjoint topics or authors. Finally, we introduce DarkReddit, a dataset with a different input data distribution. We further use it to analyze the domain generalization performance of models in a low-data regime and how performance varies when using the proposed PAN-2020 splits for fine-tuning. We show that those splits can enhance the models' capability to transfer knowledge over a new, significantly different dataset.
DATE: Detecting Anomalies in Text via Self-Supervision of Transformers
Apr 12, 2021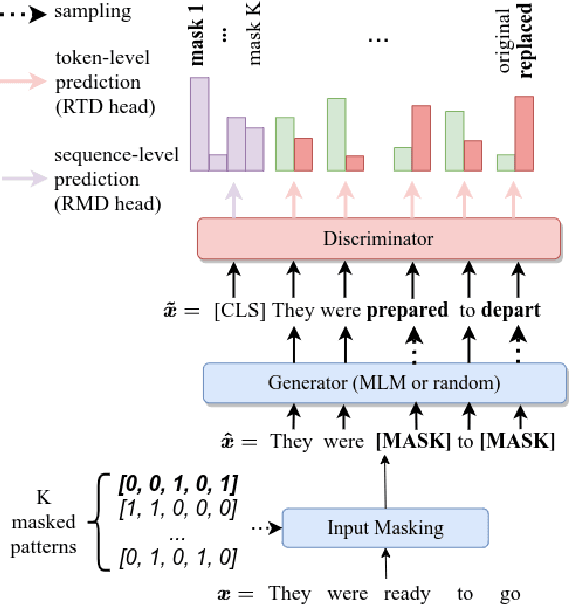

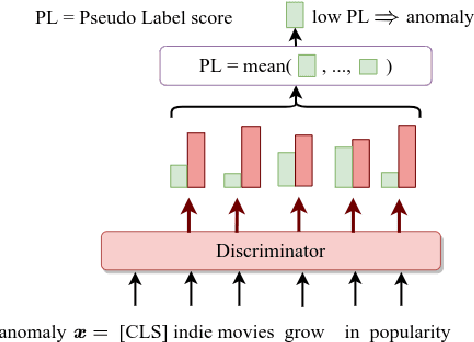

Leveraging deep learning models for Anomaly Detection (AD) has seen widespread use in recent years due to superior performances over traditional methods. Recent deep methods for anomalies in images learn better features of normality in an end-to-end self-supervised setting. These methods train a model to discriminate between different transformations applied to visual data and then use the output to compute an anomaly score. We use this approach for AD in text, by introducing a novel pretext task on text sequences. We learn our DATE model end-to-end, enforcing two independent and complementary self-supervision signals, one at the token-level and one at the sequence-level. Under this new task formulation, we show strong quantitative and qualitative results on the 20Newsgroups and AG News datasets. In the semi-supervised setting, we outperform state-of-the-art results by +13.5% and +6.9%, respectively (AUROC). In the unsupervised configuration, DATE surpasses all other methods even when 10% of its training data is contaminated with outliers (compared with 0% for the others).
Unsupervised Domain Adaptation through Iterative Consensus Shift in a Multi-Task Graph
Mar 26, 2021
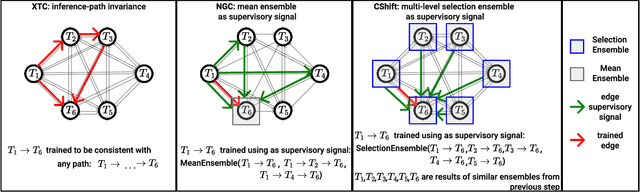
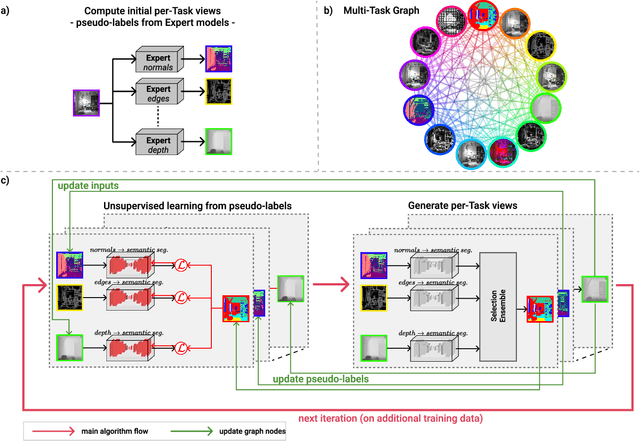
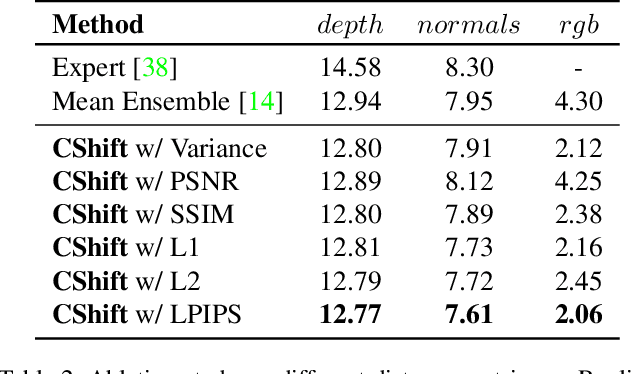
Babies learn with very little supervision by observing the surrounding world. They synchronize the feedback from all their senses and learn to maintain consistency and stability among their internal states. Such observations inspired recent works in multi-task and multi-modal learning, but existing methods rely on expensive manual supervision. In contrast, our proposed multi-task graph, with consensus shift learning, relies only on pseudo-labels provided by expert models. In our graph, every node represents a task, and every edge learns to transform one input node into another. Once initialized, the graph learns by itself on virtually any novel target domain. An adaptive selection mechanism finds consensus among multiple paths reaching a given node and establishes the pseudo-ground truth at that node. Such pseudo-labels, given by ensemble pathways in the graph, are used during the next learning iteration when single edges distill this distributed knowledge. We validate our key contributions experimentally and demonstrate strong performance on the Replica dataset, superior to the very few published methods on multi-task learning with minimal supervision.