 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring BERT-like Transformers' Knowledge for Authorship Verification
Dec 09, 2021

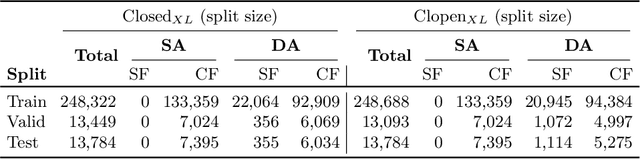

The task of identifying the author of a text spans several decades and was tackled using linguistics, statistics, and, more recently, machine learning. Inspired by the impressive performance gains across a broad range of natural language processing tasks and by the recent availability of the PAN large-scale authorship dataset, we first study the effectiveness of several BERT-like transformers for the task of authorship verification. Such models prove to achieve very high scores consistently. Next, we empirically show that they focus on topical clues rather than on author writing style characteristics, taking advantage of existing biases in the dataset. To address this problem, we provide new splits for PAN-2020, where training and test data are sampled from disjoint topics or authors. Finally, we introduce DarkReddit, a dataset with a different input data distribution. We further use it to analyze the domain generalization performance of models in a low-data regime and how performance varies when using the proposed PAN-2020 splits for fine-tuning. We show that those splits can enhance the models' capability to transfer knowledge over a new, significantly different dataset.
Challenges in Representation Learning: A report on three machine learning contests
Jul 01, 2013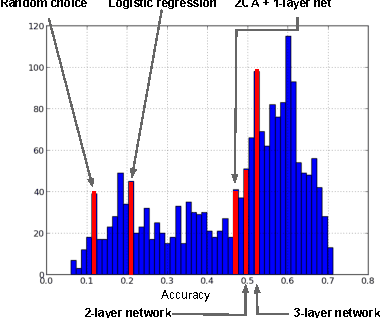

The ICML 2013 Workshop on Challenges in Representation Learning focused on three challenges: the black box learning challenge, the facial expression recognition challenge, and the multimodal learning challenge. We describe the datasets created for these challenges and summarize the results of the competitions. We provide suggestions for organizers of future challenges and some comments on what kind of knowledge can be gained from machine learning competitions.