 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Evaluation of Deep Semi-Supervised Learning Algorithms
Oct 26, 2018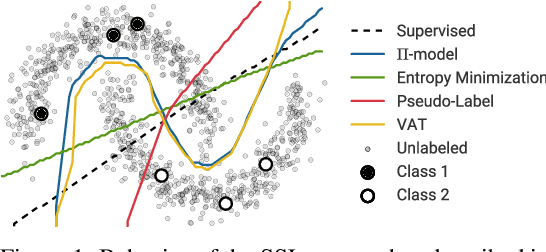

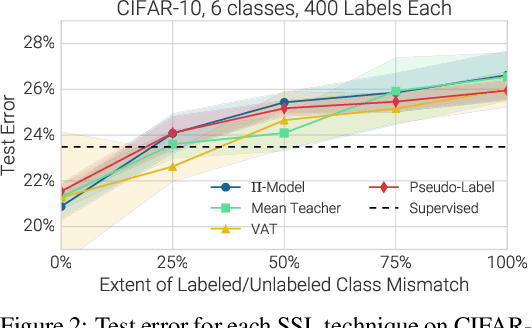

Semi-supervised learning (SSL) provides a powerful framework for leveraging unlabeled data when labels are limited or expensive to obtain. SSL algorithms based on deep neural networks have recently proven successful on standard benchmark tasks. However, we argue that these benchmarks fail to address many issues that these algorithms would face in real-world applications. After creating a unified reimplementation of various widely-used SSL techniques, we test them in a suite of experiments designed to address these issues. We find that the performance of simple baselines which do not use unlabeled data is often underreported, that SSL methods differ in sensitivity to the amount of labeled and unlabeled data, and that performance can degrade substantially when the unlabeled dataset contains out-of-class examples. To help guide SSL research towards real-world applicability, we make our unified reimplemention and evaluation platform publicly available.
Qualitatively characterizing neural network optimization problems
May 21, 2015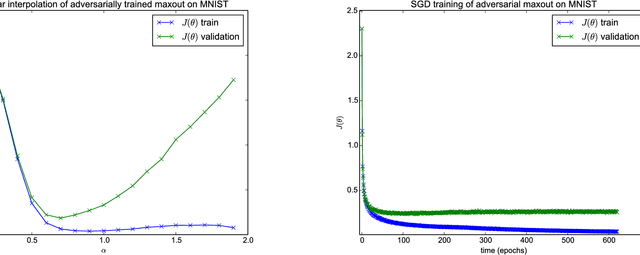
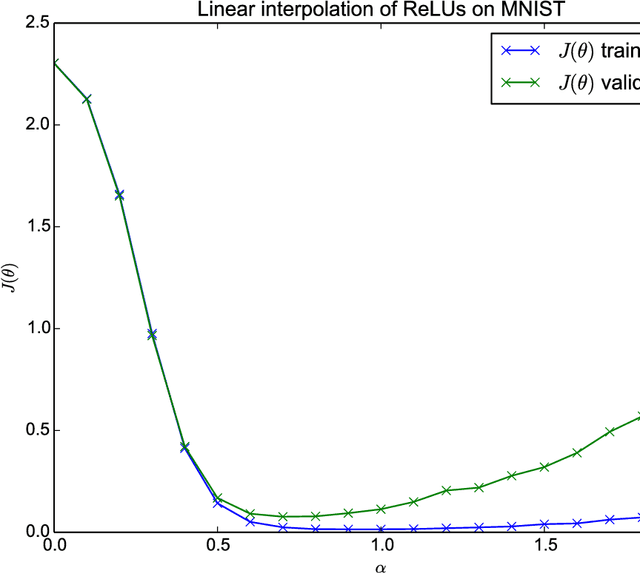
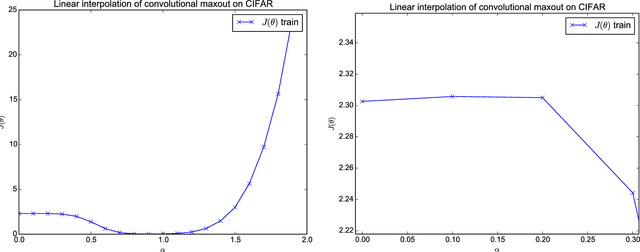
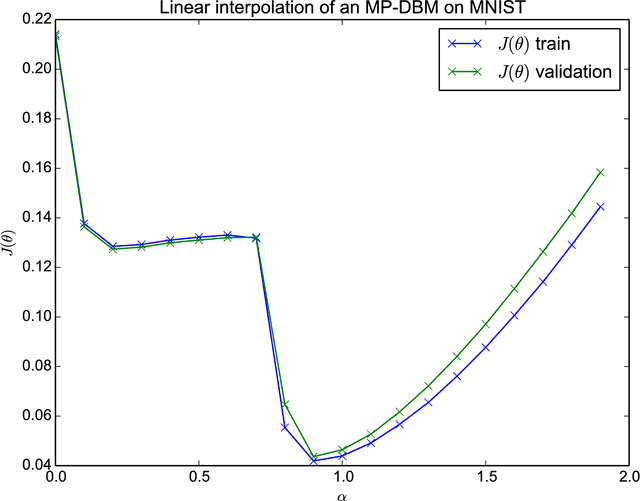
Training neural networks involves solving large-scale non-convex optimization problems. This task has long been believed to be extremely difficult, with fear of local minima and other obstacles motivating a variety of schemes to improve optimization, such as unsupervised pretraining. However, modern neural networks are able to achieve negligible training error on complex tasks, using only direct training with stochastic gradient descent. We introduce a simple analysis technique to look for evidence that such networks are overcoming local optima. We find that, in fact, on a straight path from initialization to solution, a variety of state of the art neural networks never encounter any significant obstacles.
On distinguishability criteria for estimating generative models
May 21, 2015Two recently introduced criteria for estimation of generative models are both based on a reduction to binary classification. Noise-contrastive estimation (NCE) is an estimation procedure in which a generative model is trained to be able to distinguish data samples from noise samples. Generative adversarial networks (GANs) are pairs of generator and discriminator networks, with the generator network learning to generate samples by attempting to fool the discriminator network into believing its samples are real data. Both estimation procedures use the same function to drive learning, which naturally raises questions about how they are related to each other, as well as whether this function is related to maximum likelihood estimation (MLE). NCE corresponds to training an internal data model belonging to the {\em discriminator} network but using a fixed generator network. We show that a variant of NCE, with a dynamic generator network, is equivalent to maximum likelihood estimation. Since pairing a learned discriminator with an appropriate dynamically selected generator recovers MLE, one might expect the reverse to hold for pairing a learned generator with a certain discriminator. However, we show that recovering MLE for a learned generator requires departing from the distinguishability game. Specifically: (i) The expected gradient of the NCE discriminator can be made to match the expected gradient of MLE, if one is allowed to use a non-stationary noise distribution for NCE, (ii) No choice of discriminator network can make the expected gradient for the GAN generator match that of MLE, and (iii) The existing theory does not guarantee that GANs will converge in the non-convex case. This suggests that the key next step in GAN research is to determine whether GANs converge, and if not, to modify their training algorithm to force convergence.
Explaining and Harnessing Adversarial Examples
Mar 20, 2015

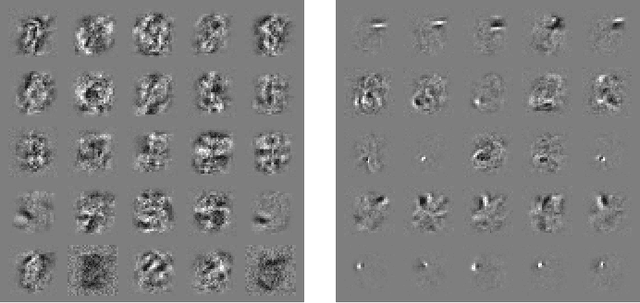
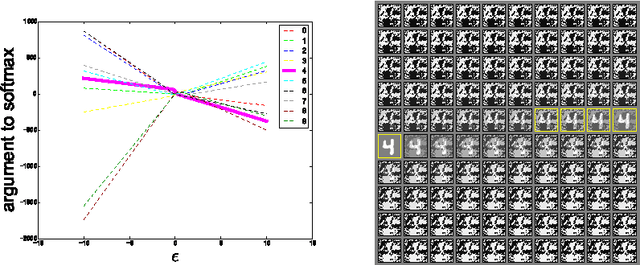
Several machine learning models, including neural networks, consistently misclassify adversarial examples---inputs formed by applying small but intentionally worst-case perturbations to examples from the dataset, such that the perturbed input results in the model outputting an incorrect answer with high confidence. Early attempts at explaining this phenomenon focused on nonlinearity and overfitting. We argue instead that the primary cause of neural networks' vulnerability to adversarial perturbation is their linear nature. This explanation is supported by new quantitative results while giving the first explanation of the most intriguing fact about them: their generalization across architectures and training sets. Moreover, this view yields a simple and fast method of generating adversarial examples. Using this approach to provide examples for adversarial training, we reduce the test set error of a maxout network on the MNIST dataset.
An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
Mar 04, 2015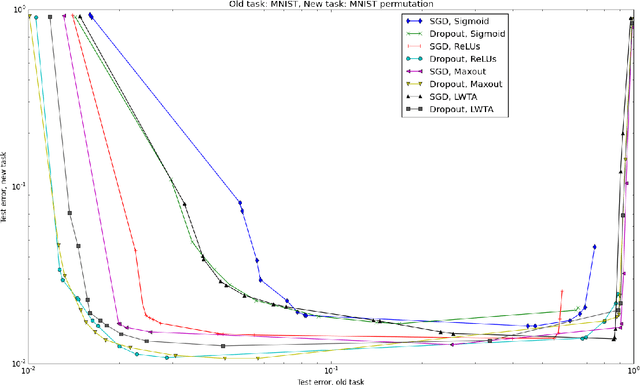
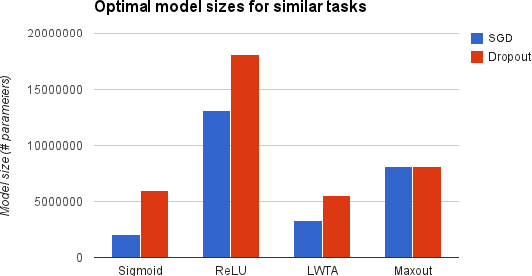
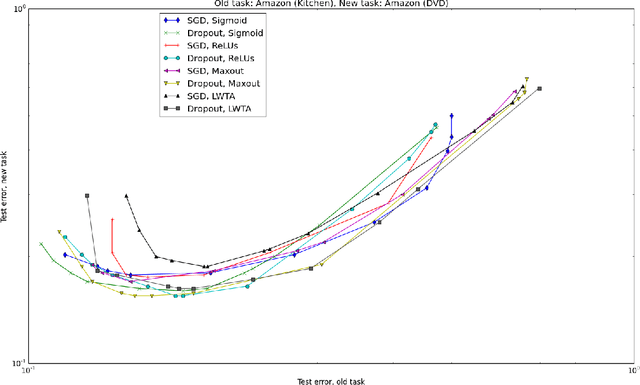
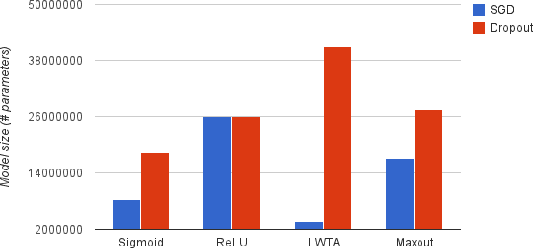
Catastrophic forgetting is a problem faced by many machine learning models and algorithms. When trained on one task, then trained on a second task, many machine learning models "forget" how to perform the first task. This is widely believed to be a serious problem for neural networks. Here, we investigate the extent to which the catastrophic forgetting problem occurs for modern neural networks, comparing both established and recent gradient-based training algorithms and activation functions. We also examine the effect of the relationship between the first task and the second task on catastrophic forgetting. We find that it is always best to train using the dropout algorithm--the dropout algorithm is consistently best at adapting to the new task, remembering the old task, and has the best tradeoff curve between these two extremes. We find that different tasks and relationships between tasks result in very different rankings of activation function performance. This suggests the choice of activation function should always be cross-validated.
On the Challenges of Physical Implementations of RBMs
Oct 24, 2014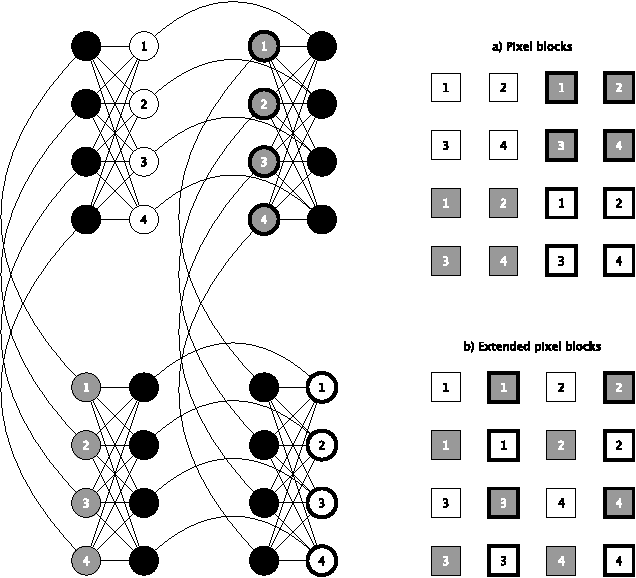
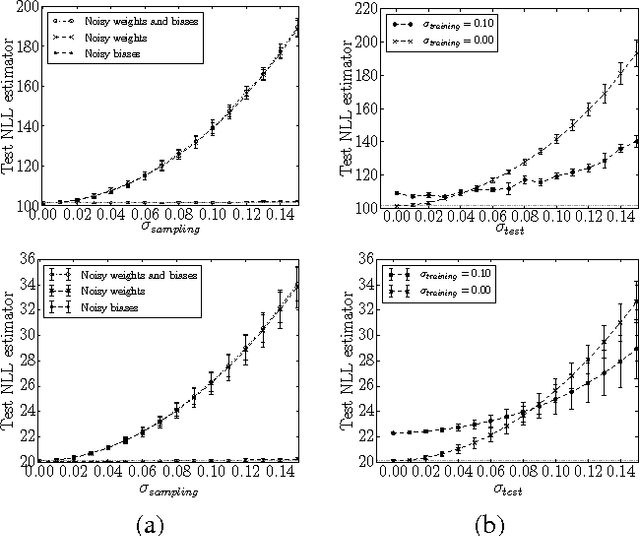
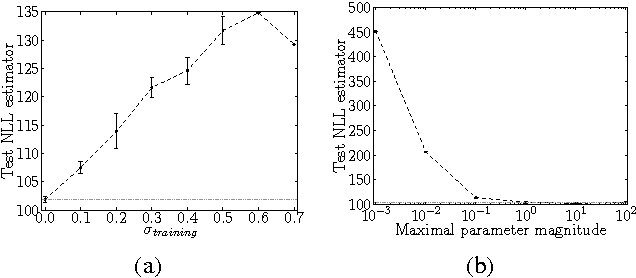
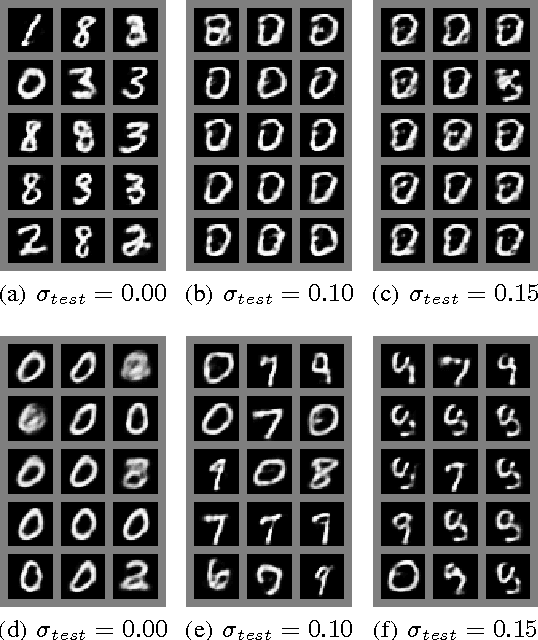
Restricted Boltzmann machines (RBMs) are powerful machine learning models, but learning and some kinds of inference in the model require sampling-based approximations, which, in classical digital computers, are implemented using expensive MCMC. Physical computation offers the opportunity to reduce the cost of sampling by building physical systems whose natural dynamics correspond to drawing samples from the desired RBM distribution. Such a system avoids the burn-in and mixing cost of a Markov chain. However, hardware implementations of this variety usually entail limitations such as low-precision and limited range of the parameters and restrictions on the size and topology of the RBM. We conduct software simulations to determine how harmful each of these restrictions is. Our simulations are designed to reproduce aspects of the D-Wave quantum computer, but the issues we investigate arise in most forms of physical computation.
Generative Adversarial Networks
Jun 10, 2014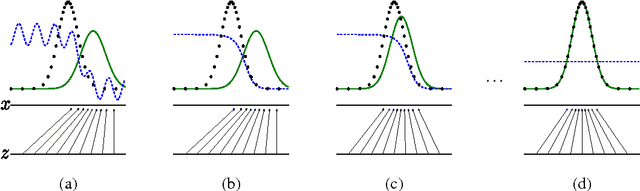
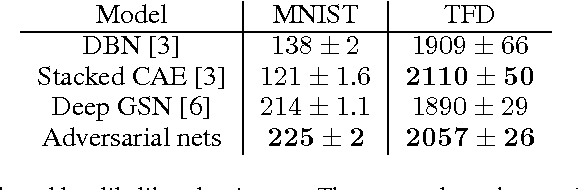

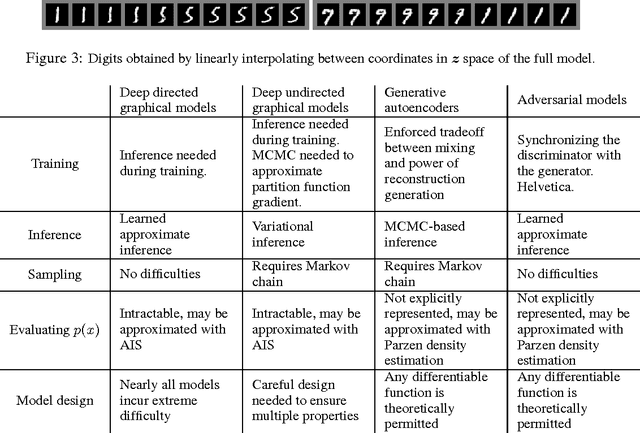
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks
Apr 14, 2014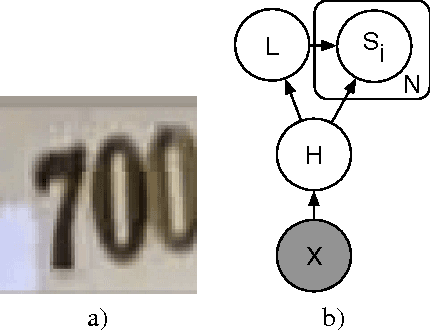


Recognizing arbitrary multi-character text in unconstrained natural photographs is a hard problem. In this paper, we address an equally hard sub-problem in this domain viz. recognizing arbitrary multi-digit numbers from Street View imagery. Traditional approaches to solve this problem typically separate out the localization, segmentation, and recognition steps. In this paper we propose a unified approach that integrates these three steps via the use of a deep convolutional neural network that operates directly on the image pixels. We employ the DistBelief implementation of deep neural networks in order to train large, distributed neural networks on high quality images. We find that the performance of this approach increases with the depth of the convolutional network, with the best performance occurring in the deepest architecture we trained, with eleven hidden layers. We evaluate this approach on the publicly available SVHN dataset and achieve over $96\%$ accuracy in recognizing complete street numbers. We show that on a per-digit recognition task, we improve upon the state-of-the-art, achieving $97.84\%$ accuracy. We also evaluate this approach on an even more challenging dataset generated from Street View imagery containing several tens of millions of street number annotations and achieve over $90\%$ accuracy. To further explore the applicability of the proposed system to broader text recognition tasks, we apply it to synthetic distorted text from reCAPTCHA. reCAPTCHA is one of the most secure reverse turing tests that uses distorted text to distinguish humans from bots. We report a $99.8\%$ accuracy on the hardest category of reCAPTCHA. Our evaluations on both tasks indicate that at specific operating thresholds, the performance of the proposed system is comparable to, and in some cases exceeds, that of human operators.
An empirical analysis of dropout in piecewise linear networks
Jan 02, 2014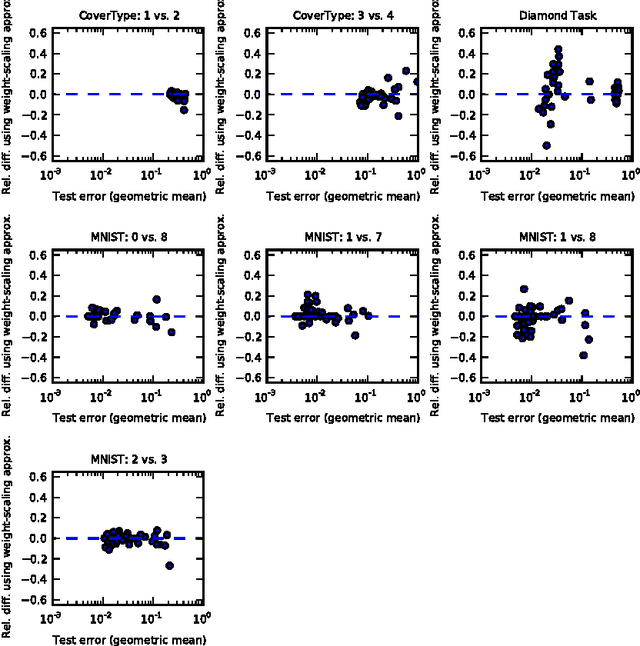
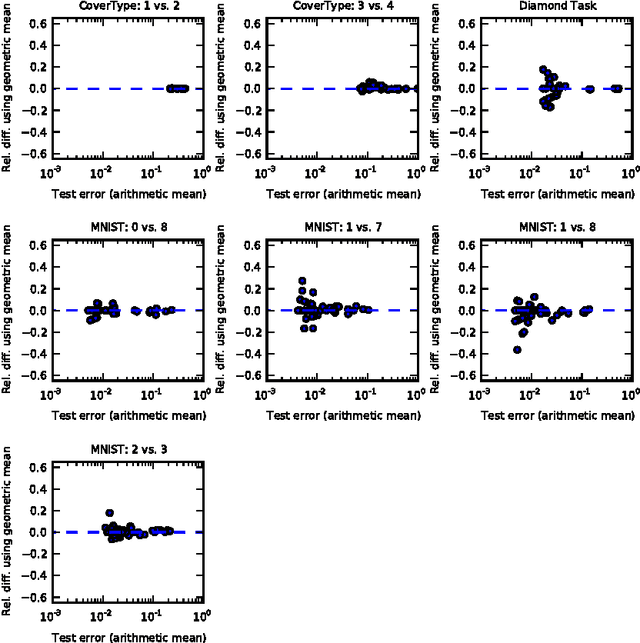
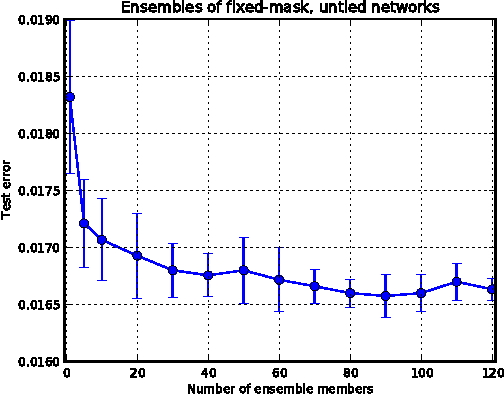
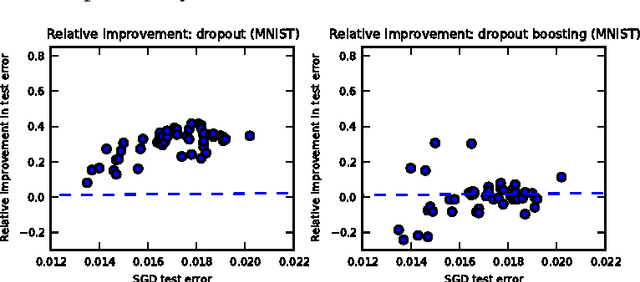
The recently introduced dropout training criterion for neural networks has been the subject of much attention due to its simplicity and remarkable effectiveness as a regularizer, as well as its interpretation as a training procedure for an exponentially large ensemble of networks that share parameters. In this work we empirically investigate several questions related to the efficacy of dropout, specifically as it concerns networks employing the popular rectified linear activation function. We investigate the quality of the test time weight-scaling inference procedure by evaluating the geometric average exactly in small models, as well as compare the performance of the geometric mean to the arithmetic mean more commonly employed by ensemble techniques. We explore the effect of tied weights on the ensemble interpretation by training ensembles of masked networks without tied weights. Finally, we investigate an alternative criterion based on a biased estimator of the maximum likelihood ensemble gradient.
Maxout Networks
Sep 20, 2013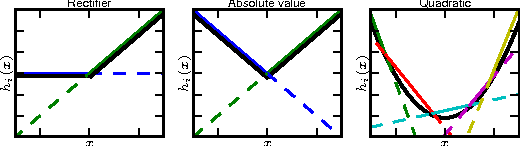
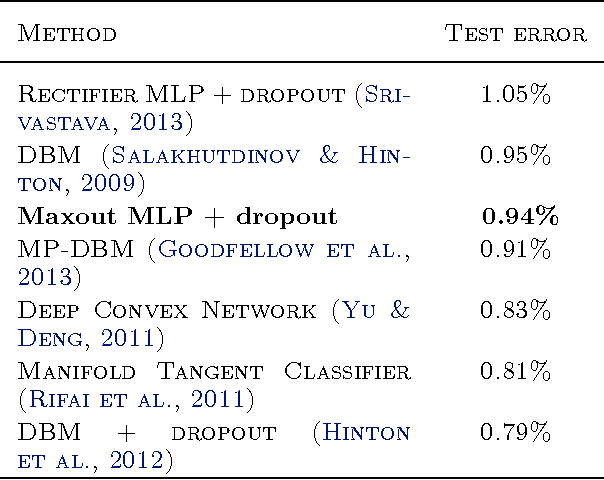
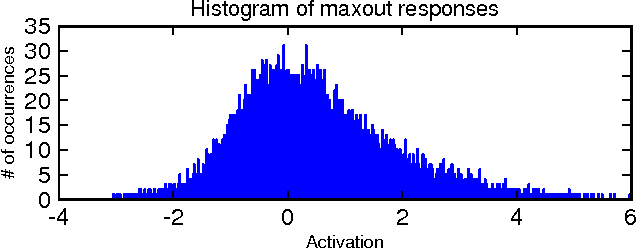

We consider the problem of designing models to leverage a recently introduced approximate model averaging technique called dropout. We define a simple new model called maxout (so named because its output is the max of a set of inputs, and because it is a natural companion to dropout) designed to both facilitate optimization by dropout and improve the accuracy of dropout's fast approximate model averaging technique. We empirically verify that the model successfully accomplishes both of these tasks. We use maxout and dropout to demonstrate state of the art classification performance on four benchmark datasets: MNIST, CIFAR-10, CIFAR-100, and SVHN.
* This is the version of the paper that appears in ICML 2013