Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualitatively characterizing neural network optimization problems
Paper and Code
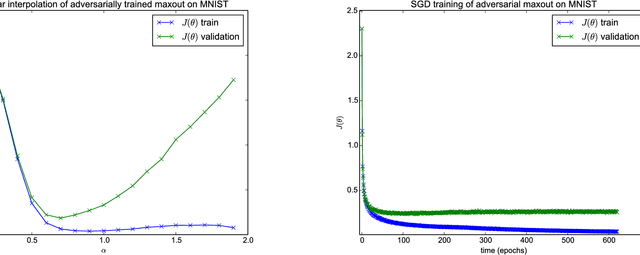
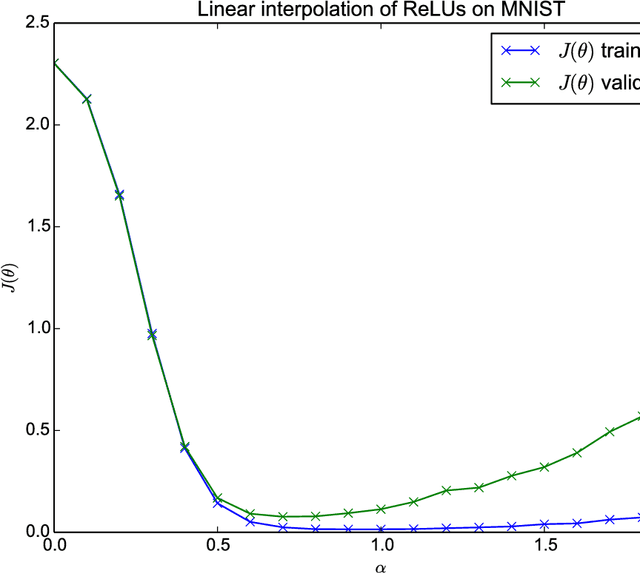
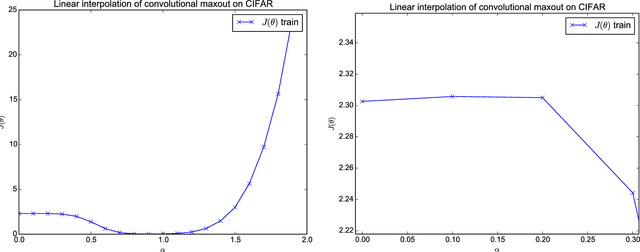
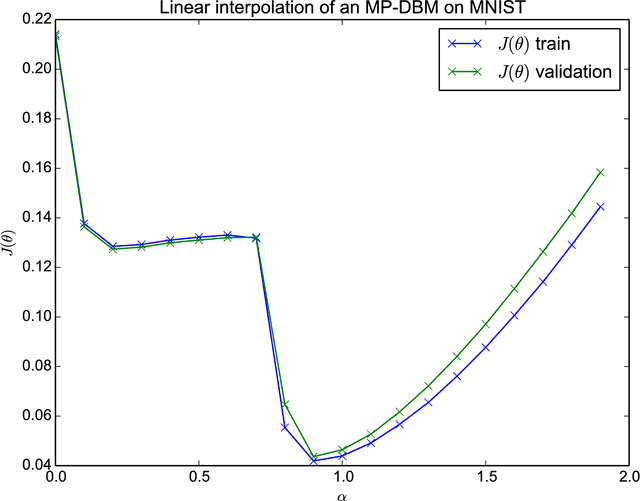
Training neural networks involves solving large-scale non-convex optimization problems. This task has long been believed to be extremely difficult, with fear of local minima and other obstacles motivating a variety of schemes to improve optimization, such as unsupervised pretraining. However, modern neural networks are able to achieve negligible training error on complex tasks, using only direct training with stochastic gradient descent. We introduce a simple analysis technique to look for evidence that such networks are overcoming local optima. We find that, in fact, on a straight path from initialization to solution, a variety of state of the art neural networks never encounter any significant obstacles.
View paper on