 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenie: Generative Interactive Environments
Feb 23, 2024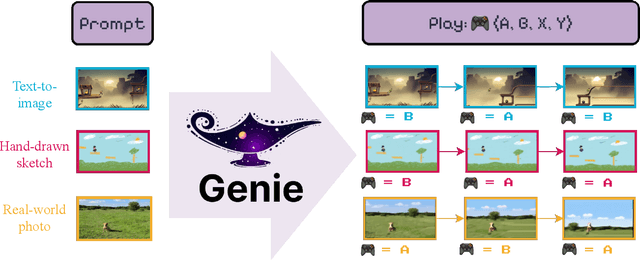
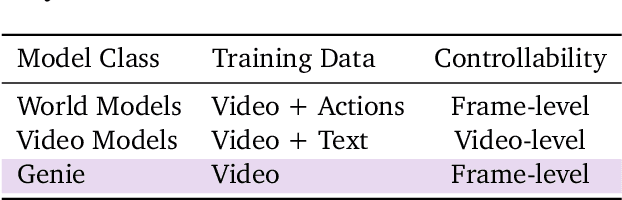
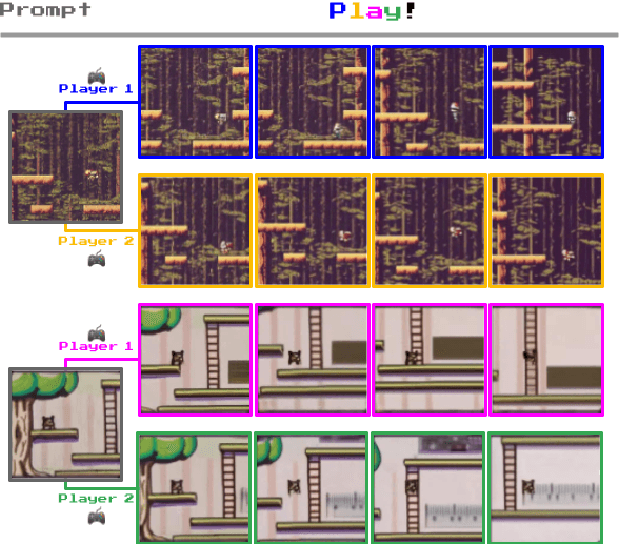
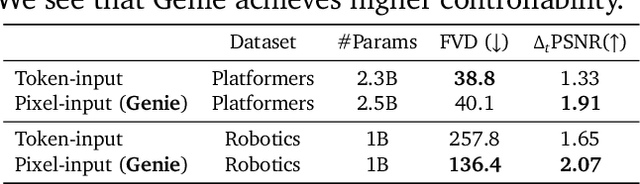
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
AlphaStar Unplugged: Large-Scale Offline Reinforcement Learning
Aug 07, 2023



StarCraft II is one of the most challenging simulated reinforcement learning environments; it is partially observable, stochastic, multi-agent, and mastering StarCraft II requires strategic planning over long time horizons with real-time low-level execution. It also has an active professional competitive scene. StarCraft II is uniquely suited for advancing offline RL algorithms, both because of its challenging nature and because Blizzard has released a massive dataset of millions of StarCraft II games played by human players. This paper leverages that and establishes a benchmark, called AlphaStar Unplugged, introducing unprecedented challenges for offline reinforcement learning. We define a dataset (a subset of Blizzard's release), tools standardizing an API for machine learning methods, and an evaluation protocol. We also present baseline agents, including behavior cloning, offline variants of actor-critic and MuZero. We improve the state of the art of agents using only offline data, and we achieve 90% win rate against previously published AlphaStar behavior cloning agent.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022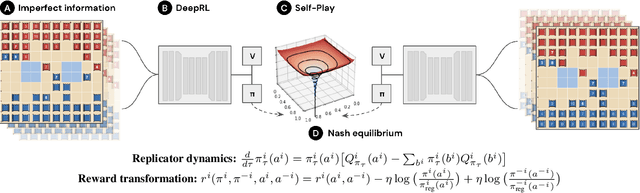
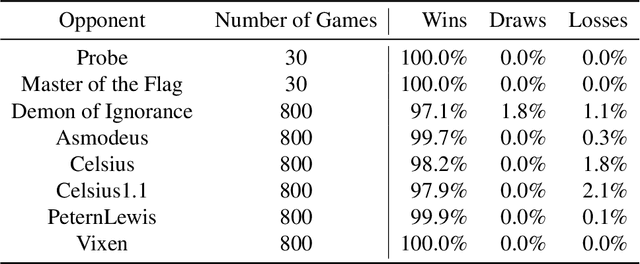
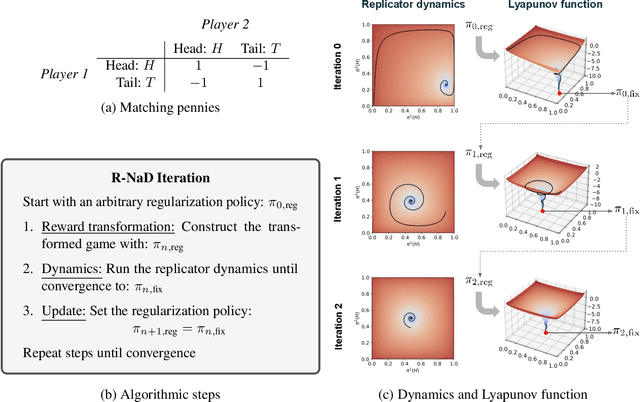

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Procedural Generalization by Planning with Self-Supervised World Models
Nov 02, 2021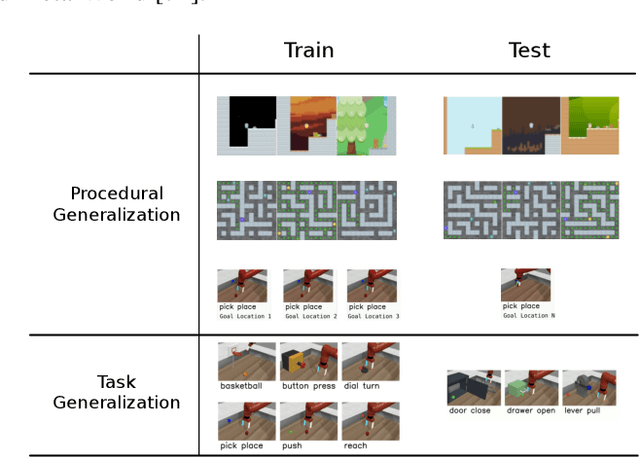
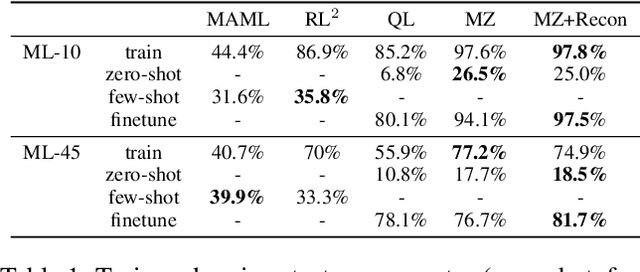
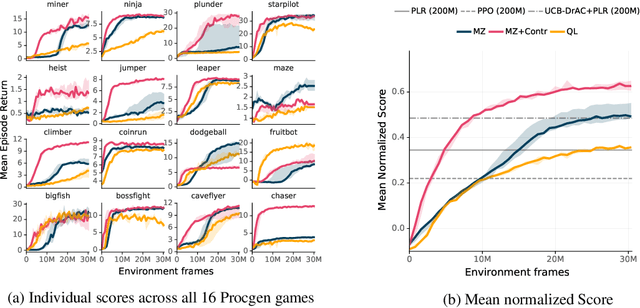
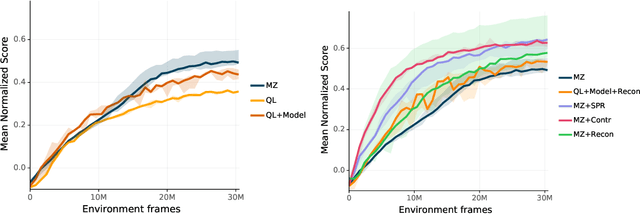
One of the key promises of model-based reinforcement learning is the ability to generalize using an internal model of the world to make predictions in novel environments and tasks. However, the generalization ability of model-based agents is not well understood because existing work has focused on model-free agents when benchmarking generalization. Here, we explicitly measure the generalization ability of model-based agents in comparison to their model-free counterparts. We focus our analysis on MuZero (Schrittwieser et al., 2020), a powerful model-based agent, and evaluate its performance on both procedural and task generalization. We identify three factors of procedural generalization -- planning, self-supervised representation learning, and procedural data diversity -- and show that by combining these techniques, we achieve state-of-the art generalization performance and data efficiency on Procgen (Cobbe et al., 2019). However, we find that these factors do not always provide the same benefits for the task generalization benchmarks in Meta-World (Yu et al., 2019), indicating that transfer remains a challenge and may require different approaches than procedural generalization. Overall, we suggest that building generalizable agents requires moving beyond the single-task, model-free paradigm and towards self-supervised model-based agents that are trained in rich, procedural, multi-task environments.
Vector Quantized Models for Planning
Jun 10, 2021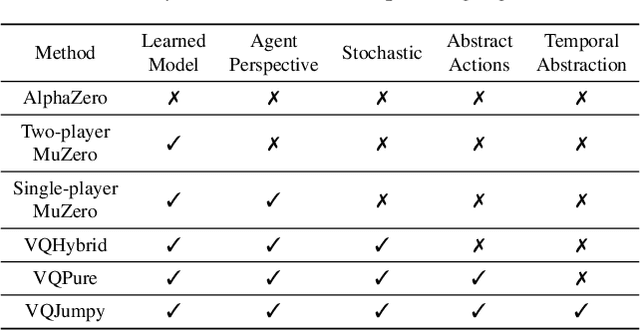
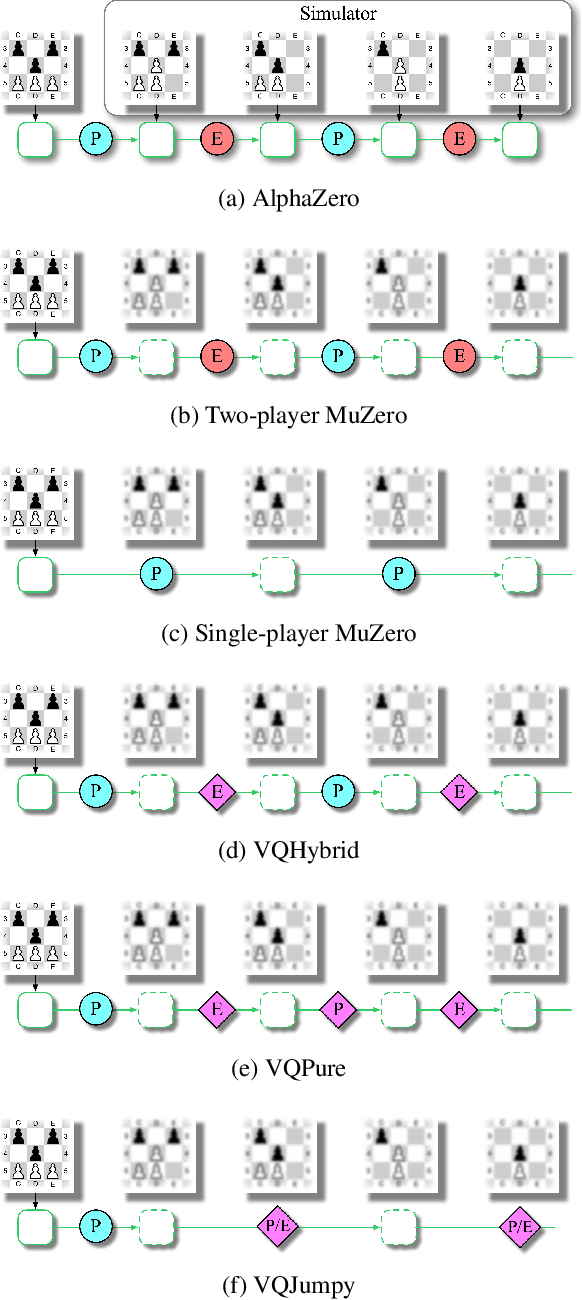
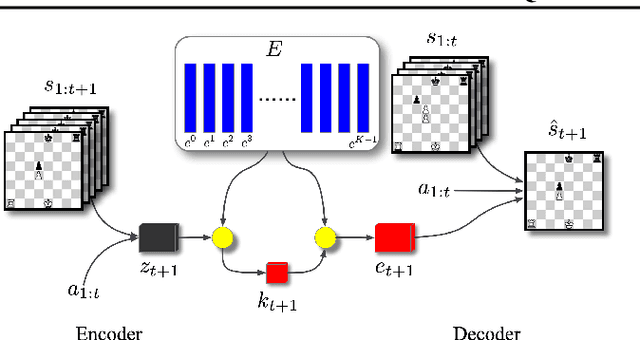
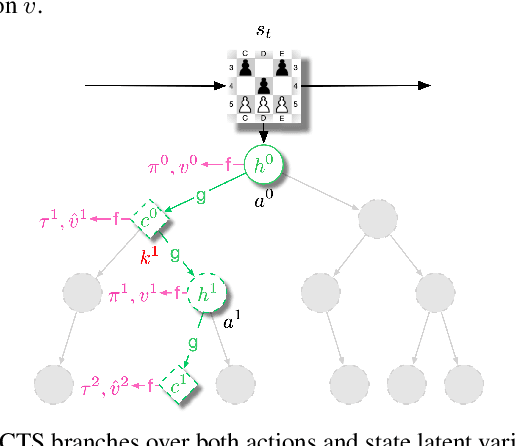
Recent developments in the field of model-based RL have proven successful in a range of environments, especially ones where planning is essential. However, such successes have been limited to deterministic fully-observed environments. We present a new approach that handles stochastic and partially-observable environments. Our key insight is to use discrete autoencoders to capture the multiple possible effects of an action in a stochastic environment. We use a stochastic variant of Monte Carlo tree search to plan over both the agent's actions and the discrete latent variables representing the environment's response. Our approach significantly outperforms an offline version of MuZero on a stochastic interpretation of chess where the opponent is considered part of the environment. We also show that our approach scales to DeepMind Lab, a first-person 3D environment with large visual observations and partial observability.
Pretrained Encoders are All You Need
Jun 09, 2021



Data-efficiency and generalization are key challenges in deep learning and deep reinforcement learning as many models are trained on large-scale, domain-specific, and expensive-to-label datasets. Self-supervised models trained on large-scale uncurated datasets have shown successful transfer to diverse settings. We investigate using pretrained image representations and spatio-temporal attention for state representation learning in Atari. We also explore fine-tuning pretrained representations with self-supervised techniques, i.e., contrastive predictive coding, spatio-temporal contrastive learning, and augmentations. Our results show that pretrained representations are at par with state-of-the-art self-supervised methods trained on domain-specific data. Pretrained representations, thus, yield data and compute-efficient state representations. https://github.com/PAL-ML/PEARL_v1
SketchTransfer: A Challenging New Task for Exploring Detail-Invariance and the Abstractions Learned by Deep Networks
Dec 25, 2019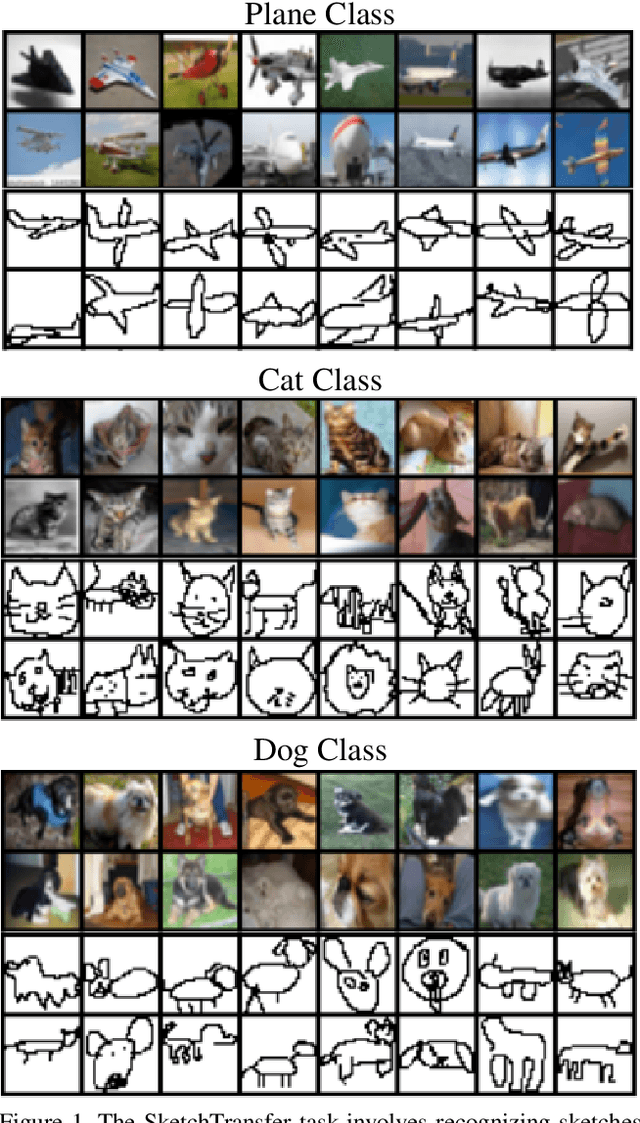

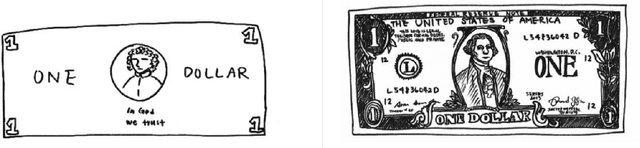
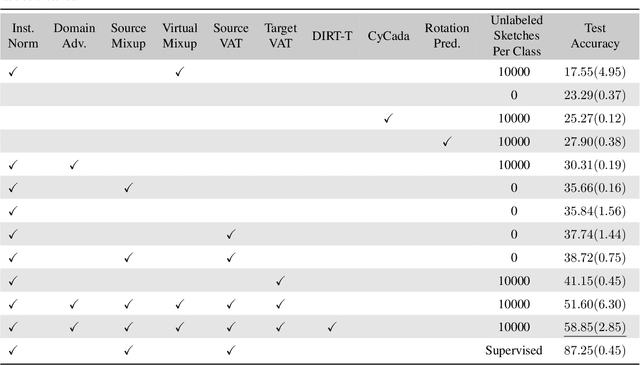
Deep networks have achieved excellent results in perceptual tasks, yet their ability to generalize to variations not seen during training has come under increasing scrutiny. In this work we focus on their ability to have invariance towards the presence or absence of details. For example, humans are able to watch cartoons, which are missing many visual details, without being explicitly trained to do so. As another example, 3D rendering software is a relatively recent development, yet people are able to understand such rendered scenes even though they are missing details (consider a film like Toy Story). The failure of machine learning algorithms to do this indicates a significant gap in generalization between human abilities and the abilities of deep networks. We propose a dataset that will make it easier to study the detail-invariance problem concretely. We produce a concrete task for this: SketchTransfer, and we show that state-of-the-art domain transfer algorithms still struggle with this task. The state-of-the-art technique which achieves over 95\% on MNIST $\xrightarrow{}$ SVHN transfer only achieves 59\% accuracy on the SketchTransfer task, which is much better than random (11\% accuracy) but falls short of the 87\% accuracy of a classifier trained directly on labeled sketches. This indicates that this task is approachable with today's best methods but has substantial room for improvement.
Unsupervised State Representation Learning in Atari
Jun 26, 2019
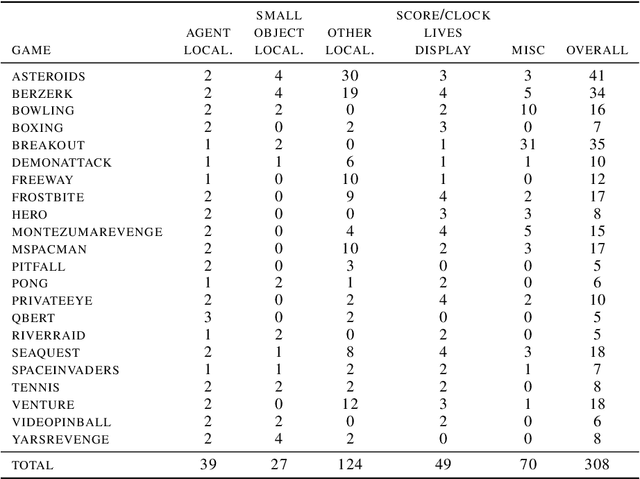
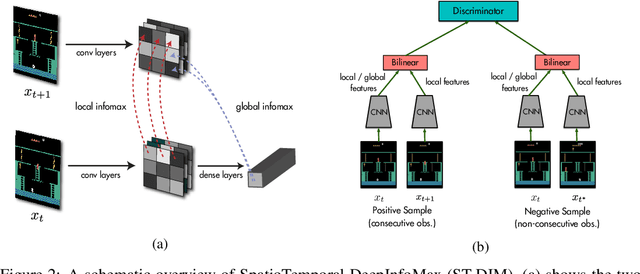
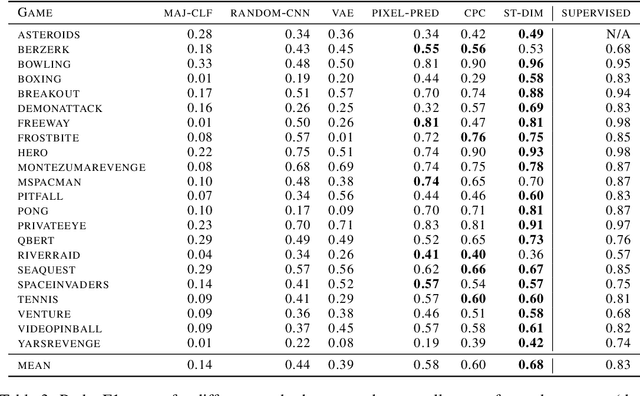
State representation learning, or the ability to capture latent generative factors of an environment, is crucial for building intelligent agents that can perform a wide variety of tasks. Learning such representations without supervision from rewards is a challenging open problem. We introduce a method that learns state representations by maximizing mutual information across spatially and temporally distinct features of a neural encoder of the observations. We also introduce a new benchmark based on Atari 2600 games where we evaluate representations based on how well they capture the ground truth state variables. We believe this new framework for evaluating representation learning models will be crucial for future representation learning research. Finally, we compare our technique with other state-of-the-art generative and contrastive representation learning methods.
The Journey is the Reward: Unsupervised Learning of Influential Trajectories
May 22, 2019
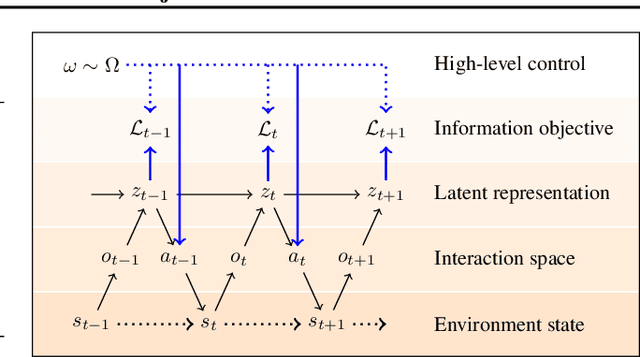
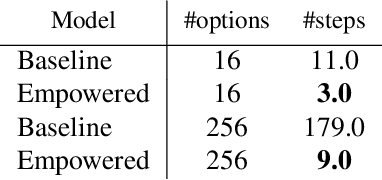
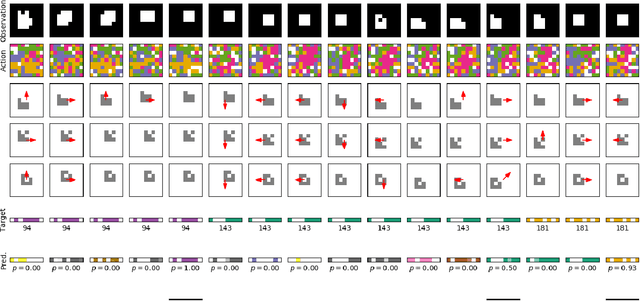
Unsupervised exploration and representation learning become increasingly important when learning in diverse and sparse environments. The information-theoretic principle of empowerment formalizes an unsupervised exploration objective through an agent trying to maximize its influence on the future states of its environment. Previous approaches carry certain limitations in that they either do not employ closed-loop feedback or do not have an internal state. As a consequence, a privileged final state is taken as an influence measure, rather than the full trajectory. We provide a model-free method which takes into account the whole trajectory while still offering the benefits of option-based approaches. We successfully apply our approach to settings with large action spaces, where discovery of meaningful action sequences is particularly difficult.