 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Endedness is Essential for Artificial Superhuman Intelligence
Jun 06, 2024


In recent years there has been a tremendous surge in the general capabilities of AI systems, mainly fuelled by training foundation models on internetscale data. Nevertheless, the creation of openended, ever self-improving AI remains elusive. In this position paper, we argue that the ingredients are now in place to achieve openendedness in AI systems with respect to a human observer. Furthermore, we claim that such open-endedness is an essential property of any artificial superhuman intelligence (ASI). We begin by providing a concrete formal definition of open-endedness through the lens of novelty and learnability. We then illustrate a path towards ASI via open-ended systems built on top of foundation models, capable of making novel, humanrelevant discoveries. We conclude by examining the safety implications of generally-capable openended AI. We expect that open-ended foundation models will prove to be an increasingly fertile and safety-critical area of research in the near future.
Genie: Generative Interactive Environments
Feb 23, 2024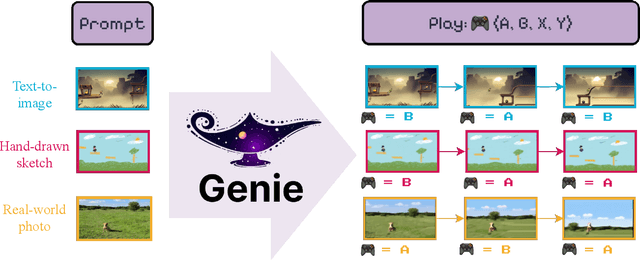
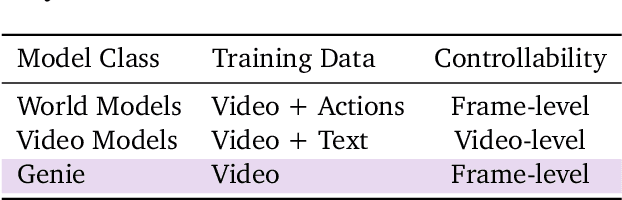
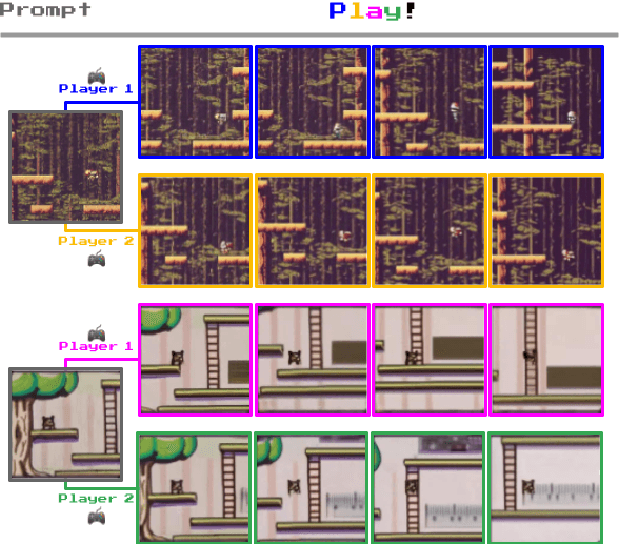
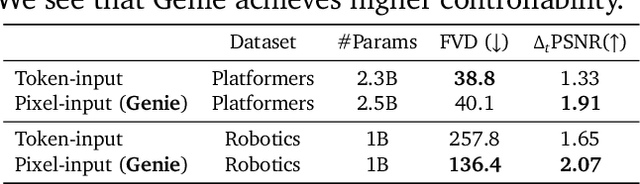
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
Memory Consolidation Enables Long-Context Video Understanding
Feb 08, 2024



Most transformer-based video encoders are limited to short temporal contexts due to their quadratic complexity. While various attempts have been made to extend this context, this has often come at the cost of both conceptual and computational complexity. We propose to instead re-purpose existing pre-trained video transformers by simply fine-tuning them to attend to memories derived non-parametrically from past activations. By leveraging redundancy reduction, our memory-consolidated vision transformer (MC-ViT) effortlessly extends its context far into the past and exhibits excellent scaling behavior when learning from longer videos. In doing so, MC-ViT sets a new state-of-the-art in long-context video understanding on EgoSchema, Perception Test, and Diving48, outperforming methods that benefit from orders of magnitude more parameters.
Tuning computer vision models with task rewards
Feb 16, 2023
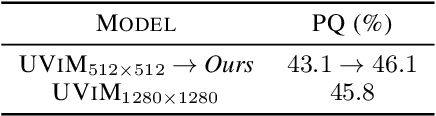
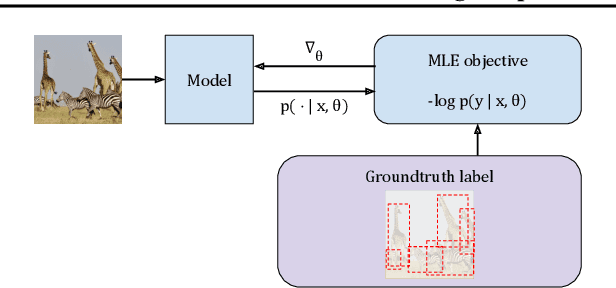

Misalignment between model predictions and intended usage can be detrimental for the deployment of computer vision models. The issue is exacerbated when the task involves complex structured outputs, as it becomes harder to design procedures which address this misalignment. In natural language processing, this is often addressed using reinforcement learning techniques that align models with a task reward. We adopt this approach and show its surprising effectiveness across multiple computer vision tasks, such as object detection, panoptic segmentation, colorization and image captioning. We believe this approach has the potential to be widely useful for better aligning models with a diverse range of computer vision tasks.
How robust are pre-trained models to distribution shift?
Jun 17, 2022

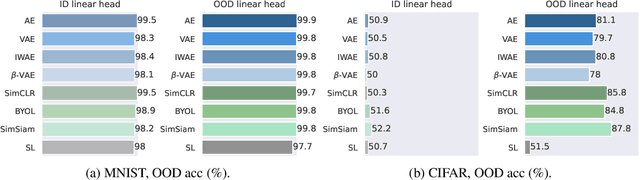

The vulnerability of machine learning models to spurious correlations has mostly been discussed in the context of supervised learning (SL). However, there is a lack of insight on how spurious correlations affect the performance of popular self-supervised learning (SSL) and auto-encoder based models (AE). In this work, we shed light on this by evaluating the performance of these models on both real world and synthetic distribution shift datasets. Following observations that the linear head itself can be susceptible to spurious correlations, we develop a novel evaluation scheme with the linear head trained on out-of-distribution (OOD) data, to isolate the performance of the pre-trained models from a potential bias of the linear head used for evaluation. With this new methodology, we show that SSL models are consistently more robust to distribution shifts and thus better at OOD generalisation than AE and SL models.
Adversarial Masking for Self-Supervised Learning
Jan 31, 2022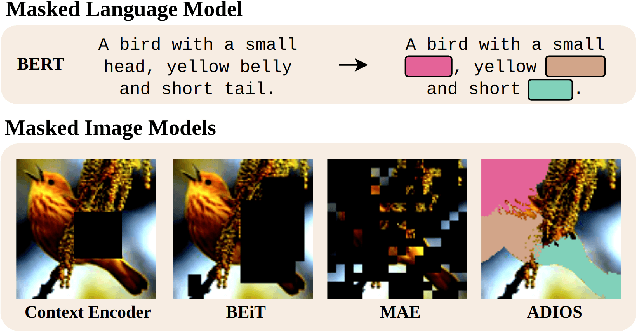
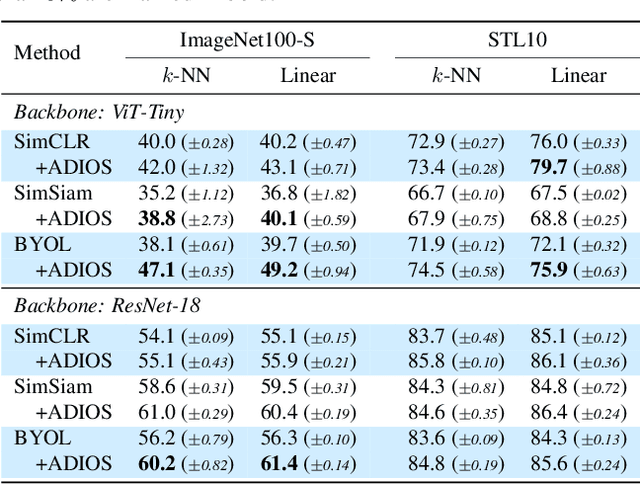

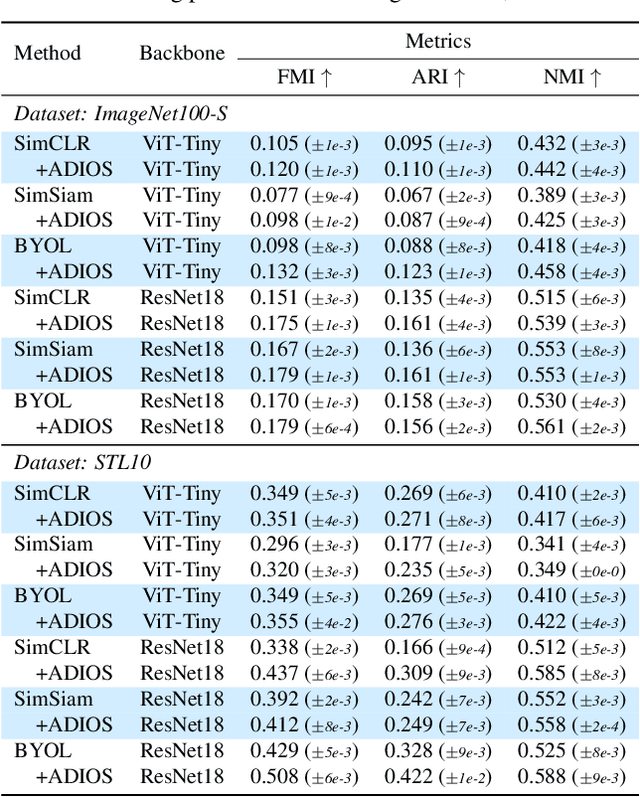
We propose ADIOS, a masked image model (MIM) framework for self-supervised learning, which simultaneously learns a masking function and an image encoder using an adversarial objective. The image encoder is trained to minimise the distance between representations of the original and that of a masked image. The masking function, conversely, aims at maximising this distance. ADIOS consistently improves on state-of-the-art self-supervised learning (SSL) methods on a variety of tasks and datasets -- including classification on ImageNet100 and STL10, transfer learning on CIFAR10/100, Flowers102 and iNaturalist, as well as robustness evaluated on the backgrounds challenge (Xiao et al., 2021) -- while generating semantically meaningful masks. Unlike modern MIM models such as MAE, BEiT and iBOT, ADIOS does not rely on the image-patch tokenisation construction of Vision Transformers, and can be implemented with convolutional backbones. We further demonstrate that the masks learned by ADIOS are more effective in improving representation learning of SSL methods than masking schemes used in popular MIM models.
Learning Multimodal VAEs through Mutual Supervision
Jul 01, 2021

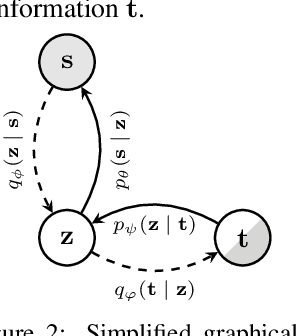

Multimodal VAEs seek to model the joint distribution over heterogeneous data (e.g.\ vision, language), whilst also capturing a shared representation across such modalities. Prior work has typically combined information from the modalities by reconciling idiosyncratic representations directly in the recognition model through explicit products, mixtures, or other such factorisations. Here we introduce a novel alternative, the MEME, that avoids such explicit combinations by repurposing semi-supervised VAEs to combine information between modalities implicitly through mutual supervision. This formulation naturally allows learning from partially-observed data where some modalities can be entirely missing -- something that most existing approaches either cannot handle, or do so to a limited extent. We demonstrate that MEME outperforms baselines on standard metrics across both partial and complete observation schemes on the MNIST-SVHN (image-image) and CUB (image-text) datasets. We also contrast the quality of the representations learnt by mutual supervision against standard approaches and observe interesting trends in its ability to capture relatedness between data.
Gradient Matching for Domain Generalization
Apr 20, 2021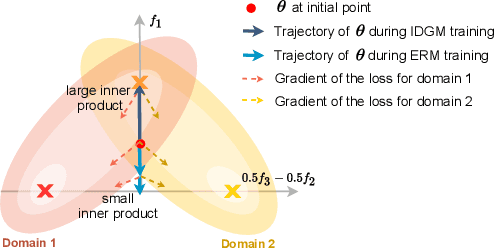


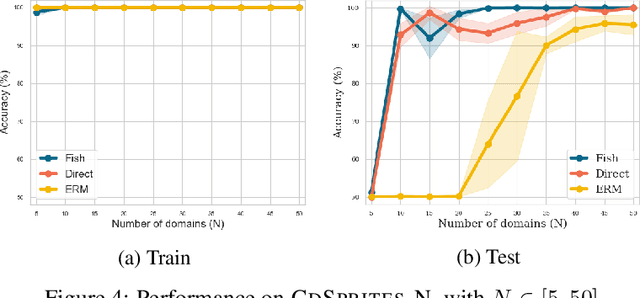
Machine learning systems typically assume that the distributions of training and test sets match closely. However, a critical requirement of such systems in the real world is their ability to generalize to unseen domains. Here, we propose an inter-domain gradient matching objective that targets domain generalization by maximizing the inner product between gradients from different domains. Since direct optimization of the gradient inner product can be computationally prohibitive -- requires computation of second-order derivatives -- we derive a simpler first-order algorithm named Fish that approximates its optimization. We demonstrate the efficacy of Fish on 6 datasets from the Wilds benchmark, which captures distribution shift across a diverse range of modalities. Our method produces competitive results on these datasets and surpasses all baselines on 4 of them. We perform experiments on both the Wilds benchmark, which captures distribution shift in the real world, as well as datasets in DomainBed benchmark that focuses more on synthetic-to-real transfer. Our method produces competitive results on both benchmarks, demonstrating its effectiveness across a wide range of domain generalization tasks.
Relating by Contrasting: A Data-efficient Framework for Multimodal Generative Models
Jul 02, 2020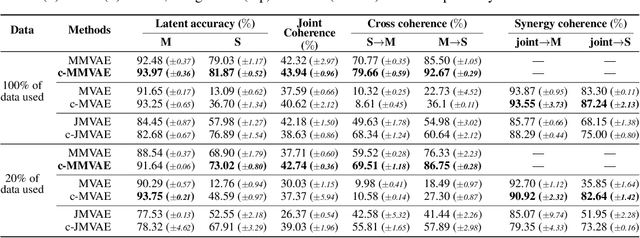
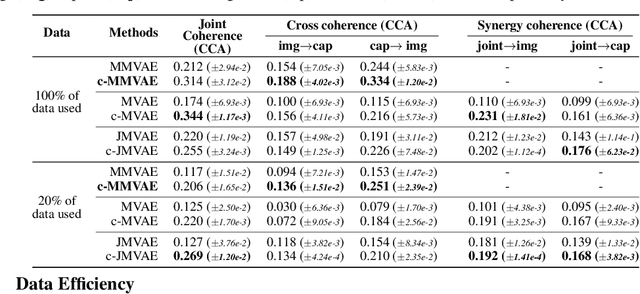


Multimodal learning for generative models often refers to the learning of abstract concepts from the commonality of information in multiple modalities, such as vision and language. While it has proven effective for learning generalisable representations, the training of such models often requires a large amount of "related" multimodal data that shares commonality, which can be expensive to come by. To mitigate this, we develop a novel contrastive framework for generative model learning, allowing us to train the model not just by the commonality between modalities, but by the distinction between "related" and "unrelated" multimodal data. We show in experiments that our method enables data-efficient multimodal learning on challenging datasets for various multimodal VAE models. We also show that under our proposed framework, the generative model can accurately identify related samples from unrelated ones, making it possible to make use of the plentiful unlabeled, unpaired multimodal data.
Action Anticipation with RBF Kernelized Feature Mapping RNN
Nov 19, 2019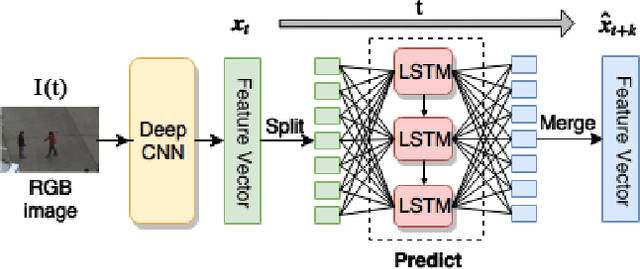
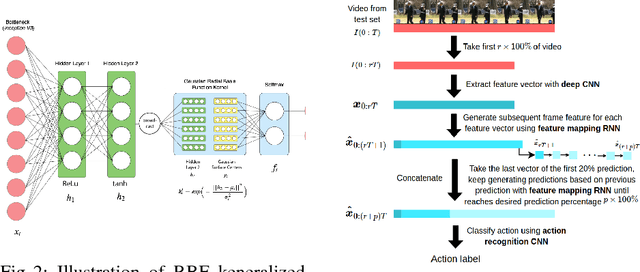
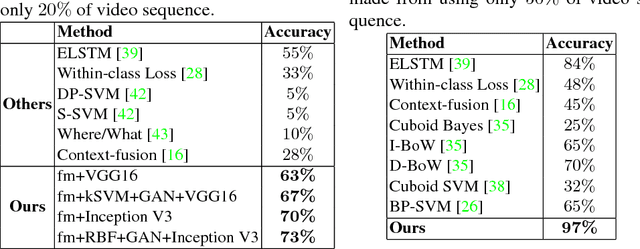

We introduce a novel Recurrent Neural Network-based algorithm for future video feature generation and action anticipation called feature mapping RNN. Our novel RNN architecture builds upon three effective principles of machine learning, namely parameter sharing, Radial Basis Function kernels and adversarial training. Using only some of the earliest frames of a video, the feature mapping RNN is able to generate future features with a fraction of the parameters needed in traditional RNN. By feeding these future features into a simple multi-layer perceptron facilitated with an RBF kernel layer, we are able to accurately predict the action in the video. In our experiments, we obtain 18% improvement on JHMDB-21 dataset, 6% on UCF101-24 and 13% improvement on UT-Interaction datasets over prior state-of-the-art for action anticipation.