 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Multimodal Pretraining
Nov 22, 2024



Large-scale multimodal representation learning successfully optimizes for zero-shot transfer at test time. Yet the standard pretraining paradigm (contrastive learning on large amounts of image-text data) does not explicitly encourage representations to support few-shot adaptation. In this work, we propose a simple, but carefully designed extension to multimodal pretraining which enables representations to accommodate additional context. Using this objective, we show that vision-language models can be trained to exhibit significantly increased few-shot adaptation: across 21 downstream tasks, we find up to four-fold improvements in test-time sample efficiency, and average few-shot adaptation gains of over 5%, while retaining zero-shot generalization performance across model scales and training durations. In particular, equipped with simple, training-free, metric-based adaptation mechanisms, our representations easily surpass more complex and expensive optimization-based schemes, vastly simplifying generalization to new domains.
Memory Consolidation Enables Long-Context Video Understanding
Feb 08, 2024



Most transformer-based video encoders are limited to short temporal contexts due to their quadratic complexity. While various attempts have been made to extend this context, this has often come at the cost of both conceptual and computational complexity. We propose to instead re-purpose existing pre-trained video transformers by simply fine-tuning them to attend to memories derived non-parametrically from past activations. By leveraging redundancy reduction, our memory-consolidated vision transformer (MC-ViT) effortlessly extends its context far into the past and exhibits excellent scaling behavior when learning from longer videos. In doing so, MC-ViT sets a new state-of-the-art in long-context video understanding on EgoSchema, Perception Test, and Diving48, outperforming methods that benefit from orders of magnitude more parameters.
Towards In-context Scene Understanding
Jun 02, 2023In-context learning$\unicode{x2013}$the ability to configure a model's behavior with different prompts$\unicode{x2013}$has revolutionized the field of natural language processing, alleviating the need for task-specific models and paving the way for generalist models capable of assisting with any query. Computer vision, in contrast, has largely stayed in the former regime: specialized decoders and finetuning protocols are generally required to perform dense tasks such as semantic segmentation and depth estimation. In this work we explore a simple mechanism for in-context learning of such scene understanding tasks: nearest neighbor retrieval from a prompt of annotated features. We propose a new pretraining protocol$\unicode{x2013}$leveraging attention within and across images$\unicode{x2013}$which yields representations particularly useful in this regime. The resulting Hummingbird model, suitably prompted, performs various scene understanding tasks without modification while approaching the performance of specialists that have been finetuned for each task. Moreover, Hummingbird can be configured to perform new tasks much more efficiently than finetuned models, raising the possibility of scene understanding in the interactive assistant regime.
Learning Representations of Entities and Relations
Jan 31, 2022
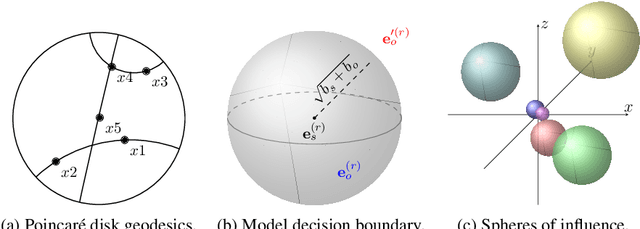
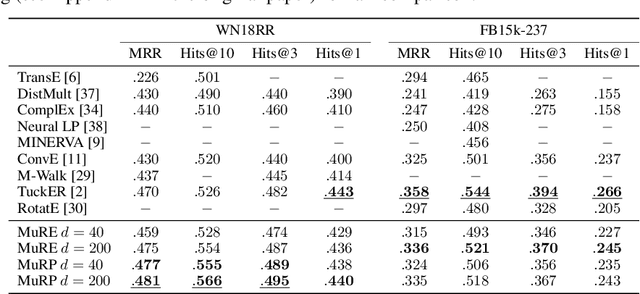
Encoding facts as representations of entities and binary relationships between them, as learned by knowledge graph representation models, is useful for various tasks, including predicting new facts, question answering, fact checking and information retrieval. The focus of this thesis is on (i) improving knowledge graph representation with the aim of tackling the link prediction task; and (ii) devising a theory on how semantics can be captured in the geometry of relation representations. Most knowledge graphs are very incomplete and manually adding new information is costly, which drives the development of methods which can automatically infer missing facts. The first contribution of this thesis is HypER, a convolutional model which simplifies and improves upon the link prediction performance of the existing convolutional state-of-the-art model ConvE and can be mathematically explained in terms of constrained tensor factorisation. The second contribution is TuckER, a relatively straightforward linear model, which, at the time of its introduction, obtained state-of-the-art link prediction performance across standard datasets. The third contribution is MuRP, first multi-relational graph representation model embedded in hyperbolic space. MuRP outperforms all existing models and its Euclidean counterpart MuRE in link prediction on hierarchical knowledge graph relations whilst requiring far fewer dimensions. Despite the development of a large number of knowledge graph representation models with gradually increasing predictive performance, relatively little is known of the latent structure they learn. We generalise recent theoretical understanding of how semantic relations of similarity, paraphrase and analogy are encoded in the geometric interactions of word embeddings to how more general relations, as found in knowledge graphs, can be encoded in their representations.
Cutting Down on Prompts and Parameters: Simple Few-Shot Learning with Language Models
Jul 01, 2021
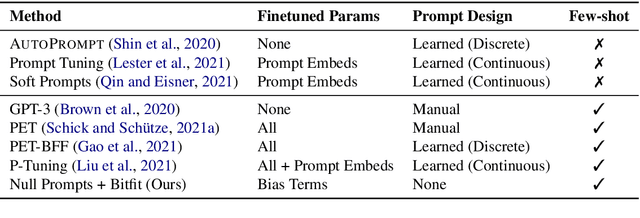

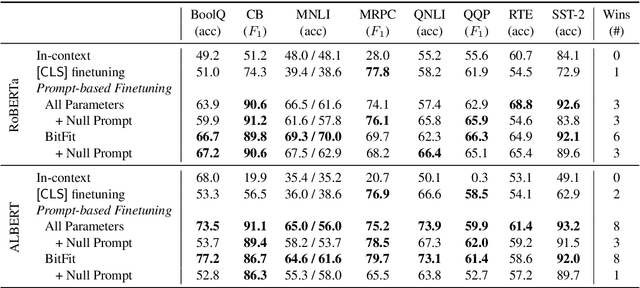
Prompting language models (LMs) with training examples and task descriptions has been seen as critical to recent successes in few-shot learning. In this work, we show that finetuning LMs in the few-shot setting can considerably reduce the need for prompt engineering. In fact, one can use null prompts, prompts that contain neither task-specific templates nor training examples, and achieve competitive accuracy to manually-tuned prompts across a wide range of tasks. While finetuning LMs does introduce new parameters for each downstream task, we show that this memory overhead can be substantially reduced: finetuning only the bias terms can achieve comparable or better accuracy than standard finetuning while only updating 0.1% of the parameters. All in all, we recommend finetuning LMs for few-shot learning as it is more accurate, robust to different prompts, and can be made nearly as efficient as using frozen LMs.
Learning the Prediction Distribution for Semi-Supervised Learning with Normalising Flows
Jul 06, 2020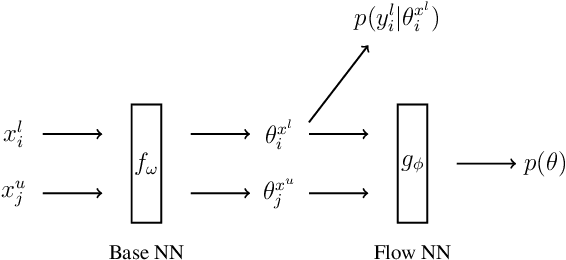
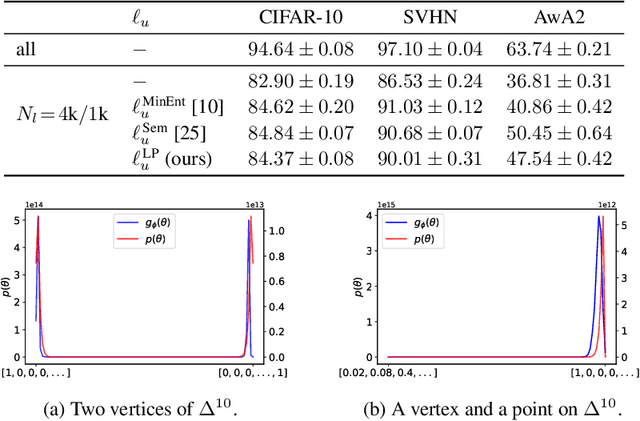

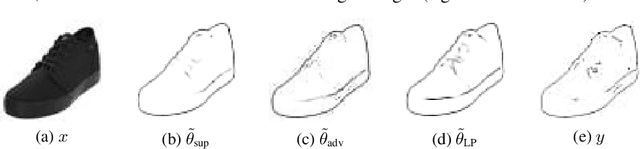
As data volumes continue to grow, the labelling process increasingly becomes a bottleneck, creating demand for methods that leverage information from unlabelled data. Impressive results have been achieved in semi-supervised learning (SSL) for image classification, nearing fully supervised performance, with only a fraction of the data labelled. In this work, we propose a probabilistically principled general approach to SSL that considers the distribution over label predictions, for labels of different complexity, from "one-hot" vectors to binary vectors and images. Our method regularises an underlying supervised model, using a normalising flow that learns the posterior distribution over predictions for labelled data, to serve as a prior over the predictions on unlabelled data. We demonstrate the general applicability of this approach on a range of computer vision tasks with varying output complexity: classification, attribute prediction and image-to-image translation.
A Probabilistic Framework for Discriminative and Neuro-Symbolic Semi-Supervised Learning
Jun 10, 2020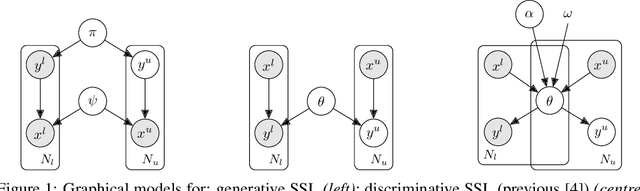

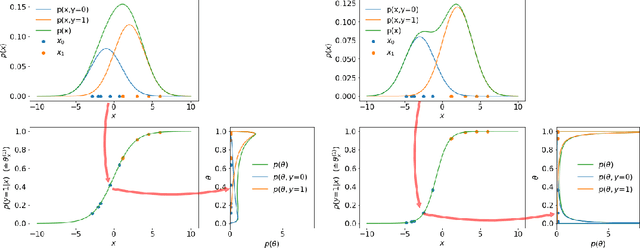
In semi-supervised learning (SSL), a rule to predict labels $y$ for data $x$ is learned from labelled data $(x^l,y^l)$ and unlabelled samples $x^u$. Strong progress has been made by combining a variety of methods, some of which pertain to $p(x)$, e.g. data augmentation that generates artificial samples from true $x$; whilst others relate to model outputs $p(y|x)$, e.g. regularising predictions on unlabelled data to minimise entropy or induce mutual exclusivity. Focusing on the latter, we fill a gap in the standard text by introducing a unifying probabilistic model for discriminative semi-supervised learning, mirroring that for classical generative methods. We show that several SSL methods can be theoretically justified under our model as inducing approximate priors over predicted parameters of $p(y|x)$. For tasks where labels represent binary attributes, our model leads to a principled approach to neuro-symbolic SSL, bridging the divide between statistical learning and logical rules.
Multi-relational Poincaré Graph Embeddings
May 25, 2019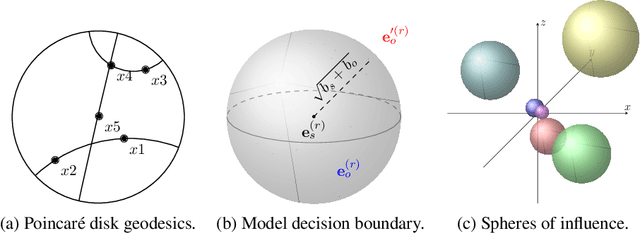
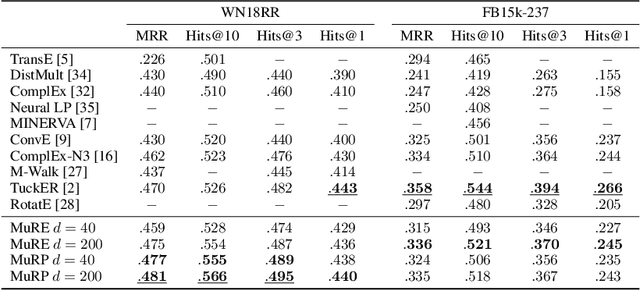
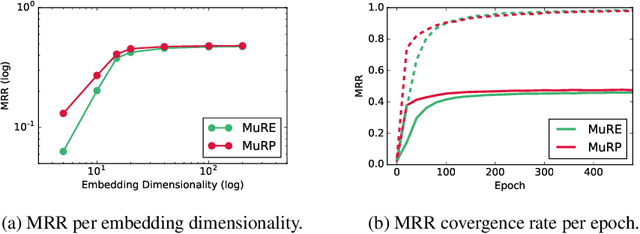
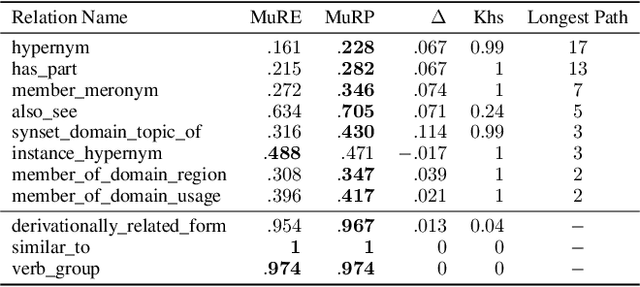
Hyperbolic embeddings have recently gained attention in machine learning due to their ability to represent hierarchical data more accurately and succinctly than their Euclidean analogues. However, multi-relational knowledge graphs often exhibit multiple simultaneous hierarchies, which current hyperbolic models do not capture. To address this, we propose a model that embeds multi-relational graph data in the Poincar\'e ball model of hyperbolic space. Our Multi-Relational Poincar\'e model (MuRP) learns relation-specific parameters to transform entity embeddings by M\"obius matrix-vector multiplication and M\"obius addition. Experiments on the hierarchical WN18RR knowledge graph show that our multi-relational Poincar\'e embeddings outperform their Euclidean counterpart and existing embedding methods on the link prediction task, particularly at lower dimensionality.
TuckER: Tensor Factorization for Knowledge Graph Completion
Jan 28, 2019
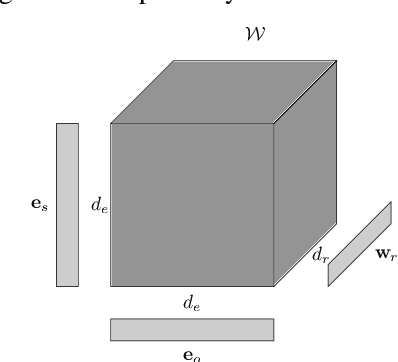

Knowledge graphs are structured representations of real world facts. However, they typically contain only a small subset of all possible facts. Link prediction is a task of inferring missing facts based on existing ones. We propose TuckER, a relatively simple but powerful linear model based on Tucker decomposition of the binary tensor representation of knowledge graph triples. TuckER outperforms all previous state-of-the-art models across standard link prediction datasets. We prove that TuckER is a fully expressive model, deriving the bound on its entity and relation embedding dimensionality for full expressiveness which is several orders of magnitude smaller than the bound of previous state-of-the-art models ComplEx and SimplE. We further show that several previously introduced linear models can be viewed as special cases of TuckER.
What the Vec? Towards Probabilistically Grounded Embeddings
May 30, 2018
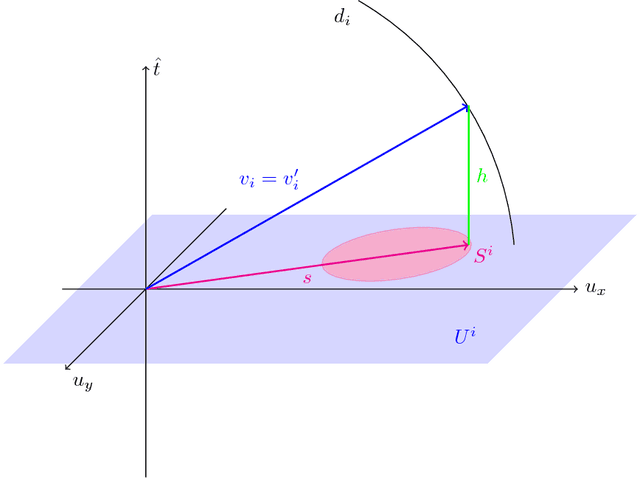
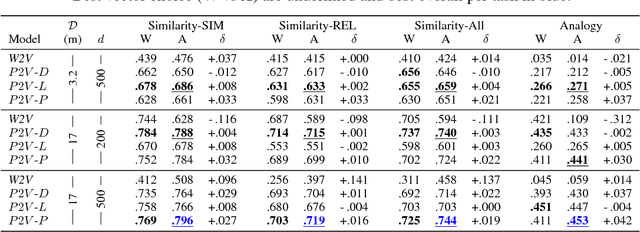
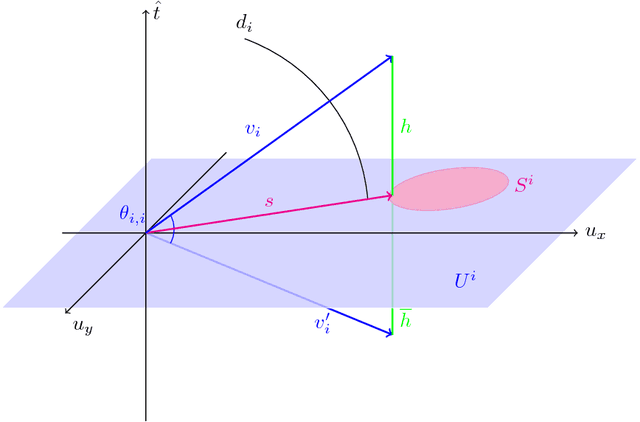
Vector representation, or embedding, of words is commonly achieved with neural network methods, in particular word2vec (W2V). It has been shown that certain statistics of word co-occurrences are implicitly captured by properties of W2V vectors, but much remains unknown of them, e.g. any meaning of length, or more generally how it is that statistics can be reliably framed as vectors at all. By deriving a mathematical link between probabilities and vectors, we justify why W2V works and are able to create embeddings with probabilistically interpretable properties.