 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Multimodal In-Context Learning: Modality Asymmetries and Circuit Dynamics in modern Transformers
Jan 28, 2026Transformer-based multimodal large language models often exhibit in-context learning (ICL) abilities. Motivated by this phenomenon, we ask: how do transformers learn to associate information across modalities from in-context examples? We investigate this question through controlled experiments on small transformers trained on synthetic classification tasks, enabling precise manipulation of data statistics and model architecture. We begin by revisiting core principles of unimodal ICL in modern transformers. While several prior findings replicate, we find that Rotary Position Embeddings (RoPE) increases the data complexity threshold for ICL. Extending to the multimodal setting reveals a fundamental learning asymmetry: when pretrained on high-diversity data from a primary modality, surprisingly low data complexity in the secondary modality suffices for multimodal ICL to emerge. Mechanistic analysis shows that both settings rely on an induction-style mechanism that copies labels from matching in-context exemplars; multimodal training refines and extends these circuits across modalities. Our findings provide a mechanistic foundation for understanding multimodal ICL in modern transformers and introduce a controlled testbed for future investigation.
Understanding the Limits of Lifelong Knowledge Editing in LLMs
Mar 07, 2025Keeping large language models factually up-to-date is crucial for deployment, yet costly retraining remains a challenge. Knowledge editing offers a promising alternative, but methods are only tested on small-scale or synthetic edit benchmarks. In this work, we aim to bridge research into lifelong knowledge editing to real-world edits at practically relevant scale. We first introduce WikiBigEdit; a large-scale benchmark of real-world Wikidata edits, built to automatically extend lifelong for future-proof benchmarking. In its first instance, it includes over 500K question-answer pairs for knowledge editing alongside a comprehensive evaluation pipeline. Finally, we use WikiBigEdit to study existing knowledge editing techniques' ability to incorporate large volumes of real-world facts and contrast their capabilities to generic modification techniques such as retrieval augmentation and continual finetuning to acquire a complete picture of the practical extent of current lifelong knowledge editing.
How to Merge Your Multimodal Models Over Time?
Dec 09, 2024



Model merging combines multiple expert models - finetuned from a base foundation model on diverse tasks and domains - into a single, more capable model. However, most existing model merging approaches assume that all experts are available simultaneously. In reality, new tasks and domains emerge progressively over time, requiring strategies to integrate the knowledge of expert models as they become available: a process we call temporal model merging. The temporal dimension introduces unique challenges not addressed in prior work, raising new questions such as: when training for a new task, should the expert model start from the merged past experts or from the original base model? Should we merge all models at each time step? Which merging techniques are best suited for temporal merging? Should different strategies be used to initialize the training and deploy the model? To answer these questions, we propose a unified framework called TIME - Temporal Integration of Model Expertise - which defines temporal model merging across three axes: (1) Initialization Phase, (2) Deployment Phase, and (3) Merging Technique. Using TIME, we study temporal model merging across model sizes, compute budgets, and learning horizons on the FoMo-in-Flux benchmark. Our comprehensive suite of experiments across TIME allows us to uncover key insights for temporal model merging, offering a better understanding of current challenges and best practices for effective temporal model merging.
Context-Aware Multimodal Pretraining
Nov 22, 2024



Large-scale multimodal representation learning successfully optimizes for zero-shot transfer at test time. Yet the standard pretraining paradigm (contrastive learning on large amounts of image-text data) does not explicitly encourage representations to support few-shot adaptation. In this work, we propose a simple, but carefully designed extension to multimodal pretraining which enables representations to accommodate additional context. Using this objective, we show that vision-language models can be trained to exhibit significantly increased few-shot adaptation: across 21 downstream tasks, we find up to four-fold improvements in test-time sample efficiency, and average few-shot adaptation gains of over 5%, while retaining zero-shot generalization performance across model scales and training durations. In particular, equipped with simple, training-free, metric-based adaptation mechanisms, our representations easily surpass more complex and expensive optimization-based schemes, vastly simplifying generalization to new domains.
A Practitioner's Guide to Continual Multimodal Pretraining
Aug 26, 2024Multimodal foundation models serve numerous applications at the intersection of vision and language. Still, despite being pretrained on extensive data, they become outdated over time. To keep models updated, research into continual pretraining mainly explores scenarios with either (1) infrequent, indiscriminate updates on large-scale new data, or (2) frequent, sample-level updates. However, practical model deployment often operates in the gap between these two limit cases, as real-world applications often demand adaptation to specific subdomains, tasks or concepts -- spread over the entire, varying life cycle of a model. In this work, we complement current perspectives on continual pretraining through a research test bed as well as provide comprehensive guidance for effective continual model updates in such scenarios. We first introduce FoMo-in-Flux, a continual multimodal pretraining benchmark with realistic compute constraints and practical deployment requirements, constructed over 63 datasets with diverse visual and semantic coverage. Using FoMo-in-Flux, we explore the complex landscape of practical continual pretraining through multiple perspectives: (1) A data-centric investigation of data mixtures and stream orderings that emulate real-world deployment situations, (2) a method-centric investigation ranging from simple fine-tuning and traditional continual learning strategies to parameter-efficient updates and model merging, (3) meta learning rate schedules and mechanistic design choices, and (4) the influence of model and compute scaling. Together, our insights provide a practitioner's guide to continual multimodal pretraining for real-world deployment. Our benchmark and code is here: https://github.com/ExplainableML/fomo_in_flux.
Disentangled Representation Learning through Geometry Preservation with the Gromov-Monge Gap
Jul 10, 2024



Learning disentangled representations in an unsupervised manner is a fundamental challenge in machine learning. Solving it may unlock other problems, such as generalization, interpretability, or fairness. While remarkably difficult to solve in general, recent works have shown that disentanglement is provably achievable under additional assumptions that can leverage geometrical constraints, such as local isometry. To use these insights, we propose a novel perspective on disentangled representation learning built on quadratic optimal transport. Specifically, we formulate the problem in the Gromov-Monge setting, which seeks isometric mappings between distributions supported on different spaces. We propose the Gromov-Monge-Gap (GMG), a regularizer that quantifies the geometry-preservation of an arbitrary push-forward map between two distributions supported on different spaces. We demonstrate the effectiveness of GMG regularization for disentanglement on four standard benchmarks. Moreover, we show that geometry preservation can even encourage unsupervised disentanglement without the standard reconstruction objective - making the underlying model decoder-free, and promising a more practically viable and scalable perspective on unsupervised disentanglement.
Reflecting on the State of Rehearsal-free Continual Learning with Pretrained Models
Jun 13, 2024With the advent and recent ubiquity of foundation models, continual learning (CL) has recently shifted from continual training from scratch to the continual adaptation of pretrained models, seeing particular success on rehearsal-free CL benchmarks (RFCL). To achieve this, most proposed methods adapt and restructure parameter-efficient finetuning techniques (PEFT) to suit the continual nature of the problem. Based most often on input-conditional query-mechanisms or regularizations on top of prompt- or adapter-based PEFT, these PEFT-style RFCL (P-RFCL) approaches report peak performances; often convincingly outperforming existing CL techniques. However, on the other end, critical studies have recently highlighted competitive results by training on just the first task or via simple non-parametric baselines. Consequently, questions arise about the relationship between methodological choices in P-RFCL and their reported high benchmark scores. In this work, we tackle these questions to better understand the true drivers behind strong P-RFCL performances, their placement w.r.t. recent first-task adaptation studies, and their relation to preceding CL standards such as EWC or SI. In particular, we show: (1) P-RFCL techniques relying on input-conditional query mechanisms work not because, but rather despite them by collapsing towards standard PEFT shortcut solutions. (2) Indeed, we show how most often, P-RFCL techniques can be matched by a simple and lightweight PEFT baseline. (3) Using this baseline, we identify the implicit bound on tunable parameters when deriving RFCL approaches from PEFT methods as a potential denominator behind P-RFCL efficacy. Finally, we (4) better disentangle continual versus first-task adaptation, and (5) motivate standard RFCL techniques s.a. EWC or SI in light of recent P-RFCL methods.
ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization
Jun 06, 2024
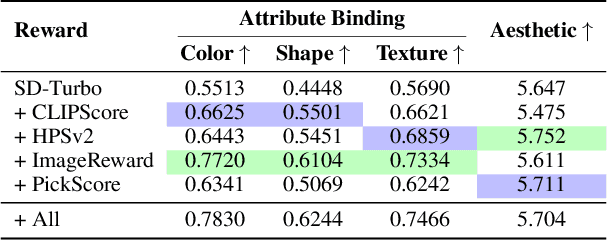

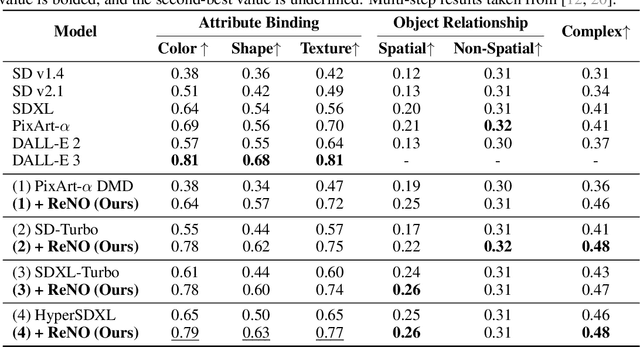
Text-to-Image (T2I) models have made significant advancements in recent years, but they still struggle to accurately capture intricate details specified in complex compositional prompts. While fine-tuning T2I models with reward objectives has shown promise, it suffers from "reward hacking" and may not generalize well to unseen prompt distributions. In this work, we propose Reward-based Noise Optimization (ReNO), a novel approach that enhances T2I models at inference by optimizing the initial noise based on the signal from one or multiple human preference reward models. Remarkably, solving this optimization problem with gradient ascent for 50 iterations yields impressive results on four different one-step models across two competitive benchmarks, T2I-CompBench and GenEval. Within a computational budget of 20-50 seconds, ReNO-enhanced one-step models consistently surpass the performance of all current open-source Text-to-Image models. Extensive user studies demonstrate that our model is preferred nearly twice as often compared to the popular SDXL model and is on par with the proprietary Stable Diffusion 3 with 8B parameters. Moreover, given the same computational resources, a ReNO-optimized one-step model outperforms widely-used open-source models such as SDXL and PixArt-$\alpha$, highlighting the efficiency and effectiveness of ReNO in enhancing T2I model performance at inference time. Code is available at https://github.com/ExplainableML/ReNO.
ETHER: Efficient Finetuning of Large-Scale Models with Hyperplane Reflections
May 30, 2024Parameter-efficient finetuning (PEFT) has become ubiquitous to adapt foundation models to downstream task requirements while retaining their generalization ability. However, the amount of additionally introduced parameters and compute for successful adaptation and hyperparameter searches can explode quickly, especially when deployed at scale to serve numerous individual requests. To ensure effective, parameter-efficient, and hyperparameter-robust adaptation, we propose the ETHER transformation family, which performs Efficient fineTuning via HypErplane Reflections. By design, ETHER transformations require a minimal number of parameters, are less likely to deteriorate model performance, and exhibit robustness to hyperparameter and learning rate choices. In particular, we introduce ETHER and its relaxation ETHER+, which match or outperform existing PEFT methods with significantly fewer parameters ($\sim$$10$-$100$ times lower than LoRA or OFT) across multiple image synthesis and natural language tasks without exhaustive hyperparameter tuning. Finally, we investigate the recent emphasis on Hyperspherical Energy retention for adaptation and raise questions on its practical utility. The code is available at https://github.com/mwbini/ether.
Improving Intervention Efficacy via Concept Realignment in Concept Bottleneck Models
May 02, 2024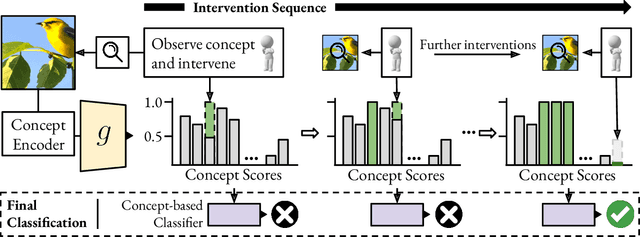


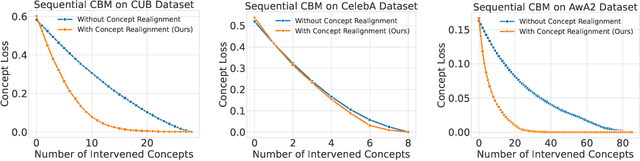
Concept Bottleneck Models (CBMs) ground image classification on human-understandable concepts to allow for interpretable model decisions. Crucially, the CBM design inherently allows for human interventions, in which expert users are given the ability to modify potentially misaligned concept choices to influence the decision behavior of the model in an interpretable fashion. However, existing approaches often require numerous human interventions per image to achieve strong performances, posing practical challenges in scenarios where obtaining human feedback is expensive. In this paper, we find that this is noticeably driven by an independent treatment of concepts during intervention, wherein a change of one concept does not influence the use of other ones in the model's final decision. To address this issue, we introduce a trainable concept intervention realignment module, which leverages concept relations to realign concept assignments post-intervention. Across standard, real-world benchmarks, we find that concept realignment can significantly improve intervention efficacy; significantly reducing the number of interventions needed to reach a target classification performance or concept prediction accuracy. In addition, it easily integrates into existing concept-based architectures without requiring changes to the models themselves. This reduced cost of human-model collaboration is crucial to enhancing the feasibility of CBMs in resource-constrained environments.