 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Good CREPE needs more than just Sugar: Investigating Biases in Compositional Vision-Language Benchmarks
Jun 09, 2025



We investigate 17 benchmarks (e.g. SugarCREPE, VALSE) commonly used for measuring compositional understanding capabilities of vision-language models (VLMs). We scrutinize design choices in their construction, including data source (e.g. MS-COCO) and curation procedures (e.g. constructing negative images/captions), uncovering several inherent biases across most benchmarks. We find that blind heuristics (e.g. token-length, log-likelihood under a language model) perform on par with CLIP models, indicating that these benchmarks do not effectively measure compositional understanding. We demonstrate that the underlying factor is a distribution asymmetry between positive and negative images/captions, induced by the benchmark construction procedures. To mitigate these issues, we provide a few key recommendations for constructing more robust vision-language compositional understanding benchmarks, that would be less prone to such simple attacks.
Scaling Laws for Robust Comparison of Open Foundation Language-Vision Models and Datasets
Jun 05, 2025



In studies of transferable learning, scaling laws are obtained for various important foundation models to predict their properties and performance at larger scales. We show here how scaling law derivation can also be used for model and dataset comparison, allowing to decide which procedure is to be preferred for pre-training. For the first time, full scaling laws based on dense measurements across a wide span of model and samples seen scales are derived for two important language-vision learning procedures, CLIP and MaMMUT, that use either contrastive only or contrastive and captioning text generative loss. Ensuring sufficient prediction accuracy for held out points, we use derived scaling laws to compare both models, obtaining evidence for MaMMUT's stronger improvement with scale and better sample efficiency than standard CLIP. To strengthen validity of the comparison, we show scaling laws for various downstream tasks, classification, retrieval, and segmentation, and for different open datasets, DataComp, DFN and Re-LAION, observing consistently the same trends. We show that comparison can also be performed when deriving scaling laws with a constant learning rate schedule, reducing compute cost. Accurate derivation of scaling laws provides thus means to perform model and dataset comparison across scale spans, avoiding misleading conclusions based on measurements from single reference scales only, paving the road for systematic comparison and improvement of open foundation models and datasets for their creation. We release all the pre-trained models with their intermediate checkpoints, including openMaMMUT-L/14, which achieves $80.3\%$ zero-shot ImageNet-1k accuracy, trained on 12.8B samples from DataComp-1.4B. Code for reproducing experiments in the paper and raw experiments data can be found at https://github.com/LAION-AI/scaling-laws-for-comparison.
A Practitioner's Guide to Continual Multimodal Pretraining
Aug 26, 2024Multimodal foundation models serve numerous applications at the intersection of vision and language. Still, despite being pretrained on extensive data, they become outdated over time. To keep models updated, research into continual pretraining mainly explores scenarios with either (1) infrequent, indiscriminate updates on large-scale new data, or (2) frequent, sample-level updates. However, practical model deployment often operates in the gap between these two limit cases, as real-world applications often demand adaptation to specific subdomains, tasks or concepts -- spread over the entire, varying life cycle of a model. In this work, we complement current perspectives on continual pretraining through a research test bed as well as provide comprehensive guidance for effective continual model updates in such scenarios. We first introduce FoMo-in-Flux, a continual multimodal pretraining benchmark with realistic compute constraints and practical deployment requirements, constructed over 63 datasets with diverse visual and semantic coverage. Using FoMo-in-Flux, we explore the complex landscape of practical continual pretraining through multiple perspectives: (1) A data-centric investigation of data mixtures and stream orderings that emulate real-world deployment situations, (2) a method-centric investigation ranging from simple fine-tuning and traditional continual learning strategies to parameter-efficient updates and model merging, (3) meta learning rate schedules and mechanistic design choices, and (4) the influence of model and compute scaling. Together, our insights provide a practitioner's guide to continual multimodal pretraining for real-world deployment. Our benchmark and code is here: https://github.com/ExplainableML/fomo_in_flux.
Inverse Deep Learning Ray Tracing for Heliostat Surface Prediction
Aug 20, 2024Concentrating Solar Power (CSP) plants play a crucial role in the global transition towards sustainable energy. A key factor in ensuring the safe and efficient operation of CSP plants is the distribution of concentrated flux density on the receiver. However, the non-ideal flux density generated by individual heliostats can undermine the safety and efficiency of the power plant. The flux density from each heliostat is influenced by its precise surface profile, which includes factors such as canting and mirror errors. Accurately measuring these surface profiles for a large number of heliostats in operation is a formidable challenge. Consequently, control systems often rely on the assumption of ideal surface conditions, which compromises both safety and operational efficiency. In this study, we introduce inverse Deep Learning Ray Tracing (iDLR), an innovative method designed to predict heliostat surfaces based solely on target images obtained during heliostat calibration. Our simulation-based investigation demonstrates that sufficient information regarding the heliostat surface is retained in the flux density distribution of a single heliostat, enabling deep learning models to accurately predict the underlying surface with deflectometry-like precision for the majority of heliostats. Additionally, we assess the limitations of this method, particularly in relation to surface accuracy and resultant flux density predictions. Furthermore, we are presenting a new comprehensive heliostat model using Non-Uniform Rational B-Spline (NURBS) that has the potential to become the new State of the Art for heliostat surface parameterization. Our findings reveal that iDLR has significant potential to enhance CSP plant operations, potentially increasing the overall efficiency and energy output of the power plants.
Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models
Jun 04, 2024



Large Language Models (LLMs) are often described as being instances of foundation models - that is, models that transfer strongly across various tasks and conditions in few-show or zero-shot manner, while exhibiting scaling laws that predict function improvement when increasing the pre-training scale. These claims of excelling in different functions and tasks rely on measurements taken across various sets of standardized benchmarks showing high scores for such models. We demonstrate here a dramatic breakdown of function and reasoning capabilities of state-of-the-art models trained at the largest available scales which claim strong function, using a simple, short, conventional common sense problem formulated in concise natural language, easily solvable by humans. The breakdown is dramatic, as models also express strong overconfidence in their wrong solutions, while providing often non-sensical "reasoning"-like explanations akin to confabulations to justify and backup the validity of their clearly failed responses, making them sound plausible. Various standard interventions in an attempt to get the right solution, like various type of enhanced prompting, or urging the models to reconsider the wrong solutions again by multi step re-evaluation, fail. We take these initial observations to the scientific and technological community to stimulate urgent re-assessment of the claimed capabilities of current generation of LLMs, Such re-assessment also requires common action to create standardized benchmarks that would allow proper detection of such basic reasoning deficits that obviously manage to remain undiscovered by current state-of-the-art evaluation procedures and benchmarks. Code for reproducing experiments in the paper and raw experiments data can be found at https://github.com/LAION-AI/AIW
DataComp: In search of the next generation of multimodal datasets
May 03, 2023Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
A Comparative Study on Generative Models for High Resolution Solar Observation Imaging
Apr 14, 2023Solar activity is one of the main drivers of variability in our solar system and the key source of space weather phenomena that affect Earth and near Earth space. The extensive record of high resolution extreme ultraviolet (EUV) observations from the Solar Dynamics Observatory (SDO) offers an unprecedented, very large dataset of solar images. In this work, we make use of this comprehensive dataset to investigate capabilities of current state-of-the-art generative models to accurately capture the data distribution behind the observed solar activity states. Starting from StyleGAN-based methods, we uncover severe deficits of this model family in handling fine-scale details of solar images when training on high resolution samples, contrary to training on natural face images. When switching to the diffusion based generative model family, we observe strong improvements of fine-scale detail generation. For the GAN family, we are able to achieve similar improvements in fine-scale generation when turning to ProjectedGANs, which uses multi-scale discriminators with a pre-trained frozen feature extractor. We conduct ablation studies to clarify mechanisms responsible for proper fine-scale handling. Using distributed training on supercomputers, we are able to train generative models for up to 1024x1024 resolution that produce high quality samples indistinguishable to human experts, as suggested by the evaluation we conduct. We make all code, models and workflows used in this study publicly available at \url{https://github.com/SLAMPAI/generative-models-for-highres-solar-images}.
Reproducible scaling laws for contrastive language-image learning
Dec 14, 2022Scaling up neural networks has led to remarkable performance across a wide range of tasks. Moreover, performance often follows reliable scaling laws as a function of training set size, model size, and compute, which offers valuable guidance as large-scale experiments are becoming increasingly expensive. However, previous work on scaling laws has primarily used private data \& models or focused on uni-modal language or vision learning. To address these limitations, we investigate scaling laws for contrastive language-image pre-training (CLIP) with the public LAION dataset and the open-source OpenCLIP repository. Our large-scale experiments involve models trained on up to two billion image-text pairs and identify power law scaling for multiple downstream tasks including zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning. We find that the training distribution plays a key role in scaling laws as the OpenAI and OpenCLIP models exhibit different scaling behavior despite identical model architectures and similar training recipes. We open-source our evaluation workflow and all models, including the largest public CLIP models, to ensure reproducibility and make scaling laws research more accessible. Source code and instructions to reproduce this study will be available at https://github.com/LAION-AI/scaling-laws-openclip
LAION-5B: An open large-scale dataset for training next generation image-text models
Oct 16, 2022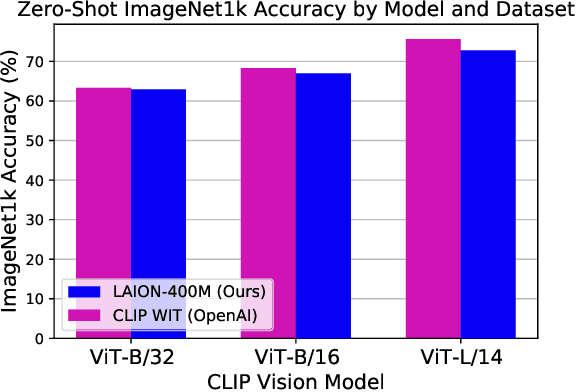
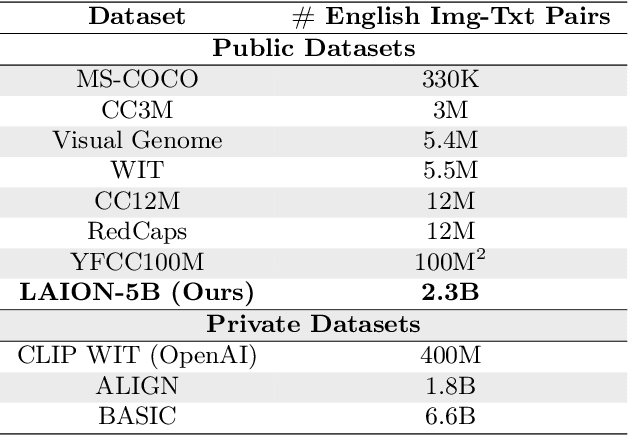
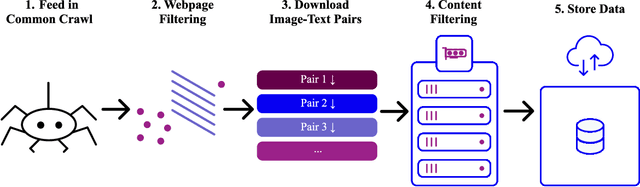
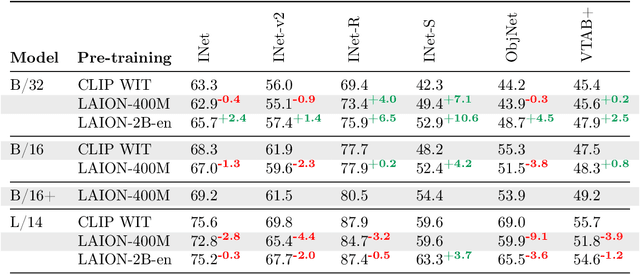
Groundbreaking language-vision architectures like CLIP and DALL-E proved the utility of training on large amounts of noisy image-text data, without relying on expensive accurate labels used in standard vision unimodal supervised learning. The resulting models showed capabilities of strong text-guided image generation and transfer to downstream tasks, while performing remarkably at zero-shot classification with noteworthy out-of-distribution robustness. Since then, large-scale language-vision models like ALIGN, BASIC, GLIDE, Flamingo and Imagen made further improvements. Studying the training and capabilities of such models requires datasets containing billions of image-text pairs. Until now, no datasets of this size have been made openly available for the broader research community. To address this problem and democratize research on large-scale multi-modal models, we present LAION-5B - a dataset consisting of 5.85 billion CLIP-filtered image-text pairs, of which 2.32B contain English language. We show successful replication and fine-tuning of foundational models like CLIP, GLIDE and Stable Diffusion using the dataset, and discuss further experiments enabled with an openly available dataset of this scale. Additionally we provide several nearest neighbor indices, an improved web-interface for dataset exploration and subset generation, and detection scores for watermark, NSFW, and toxic content detection. Announcement page https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/
Effect of large-scale pre-training on full and few-shot transfer learning for natural and medical images
Jun 09, 2021
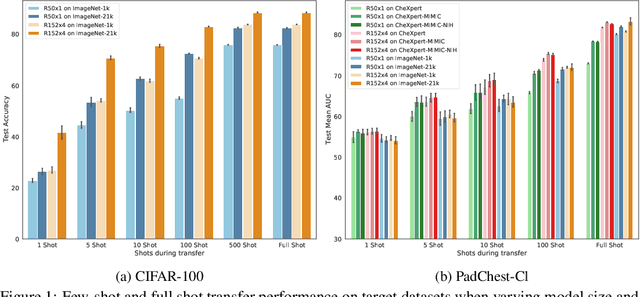

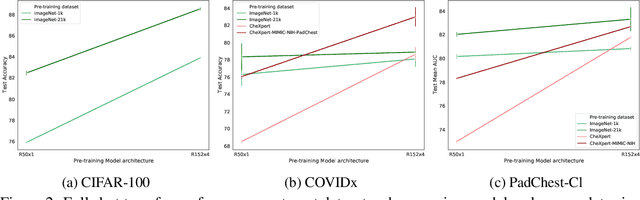
Transfer learning aims to exploit pre-trained models for more efficient follow-up training on wide range of downstream tasks and datasets, enabling successful training also on small data. Recent line of work posits strong benefits for model generalization and transfer when model size, data size, and compute budget are increased for the pre-training. It remains however still largely unclear whether the observed transfer improvement due to increase in scale also holds when source and target data distributions are far apart from each other. In this work we conduct large-scale pre-training on large source datasets of either natural (ImageNet-21k/1k) or medical chest X-Ray images and compare full and few-shot transfer using different target datasets from both natural and medical imaging domains. Our observations provide evidence that while pre-training and transfer on closely related datasets do show clear benefit of increasing model and data size during pre-training, such benefits are not clearly visible when source and target datasets are further apart. These observations hold across both full and few-shot transfer and indicate that scaling laws pointing to improvement of generalization and transfer with increasing model and data size are incomplete and should be revised by taking into account the type and proximity of the source and target data, to correctly predict the effect of model and data scale during pre-training on transfer. Remarkably, in full shot transfer to a large X-Ray chest imaging target (PadChest), the largest model pre-trained on ImageNet-21k slightly outperforms best models pre-trained on large X-Ray chest imaging data. This indicates possibility to obtain high quality models for domain-specific transfer even without access to large domain-specific data, by pre-training instead on comparably very large, generic source data.