 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Robust Comparison of Open Foundation Language-Vision Models and Datasets
Jun 05, 2025



In studies of transferable learning, scaling laws are obtained for various important foundation models to predict their properties and performance at larger scales. We show here how scaling law derivation can also be used for model and dataset comparison, allowing to decide which procedure is to be preferred for pre-training. For the first time, full scaling laws based on dense measurements across a wide span of model and samples seen scales are derived for two important language-vision learning procedures, CLIP and MaMMUT, that use either contrastive only or contrastive and captioning text generative loss. Ensuring sufficient prediction accuracy for held out points, we use derived scaling laws to compare both models, obtaining evidence for MaMMUT's stronger improvement with scale and better sample efficiency than standard CLIP. To strengthen validity of the comparison, we show scaling laws for various downstream tasks, classification, retrieval, and segmentation, and for different open datasets, DataComp, DFN and Re-LAION, observing consistently the same trends. We show that comparison can also be performed when deriving scaling laws with a constant learning rate schedule, reducing compute cost. Accurate derivation of scaling laws provides thus means to perform model and dataset comparison across scale spans, avoiding misleading conclusions based on measurements from single reference scales only, paving the road for systematic comparison and improvement of open foundation models and datasets for their creation. We release all the pre-trained models with their intermediate checkpoints, including openMaMMUT-L/14, which achieves $80.3\%$ zero-shot ImageNet-1k accuracy, trained on 12.8B samples from DataComp-1.4B. Code for reproducing experiments in the paper and raw experiments data can be found at https://github.com/LAION-AI/scaling-laws-for-comparison.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
Reproducible scaling laws for contrastive language-image learning
Dec 14, 2022Scaling up neural networks has led to remarkable performance across a wide range of tasks. Moreover, performance often follows reliable scaling laws as a function of training set size, model size, and compute, which offers valuable guidance as large-scale experiments are becoming increasingly expensive. However, previous work on scaling laws has primarily used private data \& models or focused on uni-modal language or vision learning. To address these limitations, we investigate scaling laws for contrastive language-image pre-training (CLIP) with the public LAION dataset and the open-source OpenCLIP repository. Our large-scale experiments involve models trained on up to two billion image-text pairs and identify power law scaling for multiple downstream tasks including zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning. We find that the training distribution plays a key role in scaling laws as the OpenAI and OpenCLIP models exhibit different scaling behavior despite identical model architectures and similar training recipes. We open-source our evaluation workflow and all models, including the largest public CLIP models, to ensure reproducibility and make scaling laws research more accessible. Source code and instructions to reproduce this study will be available at https://github.com/LAION-AI/scaling-laws-openclip
LAION-5B: An open large-scale dataset for training next generation image-text models
Oct 16, 2022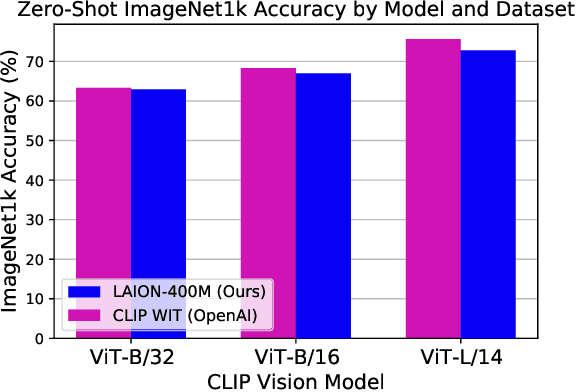
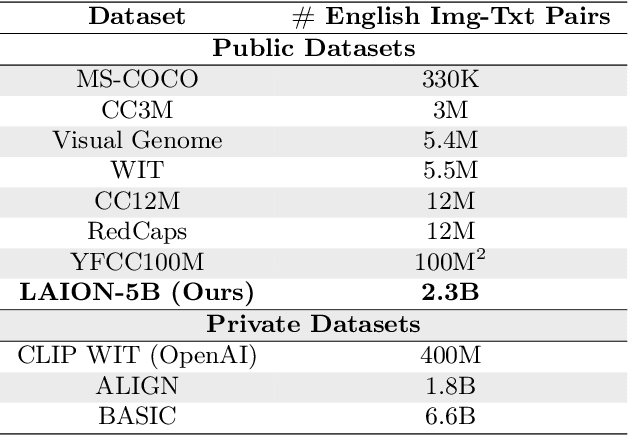
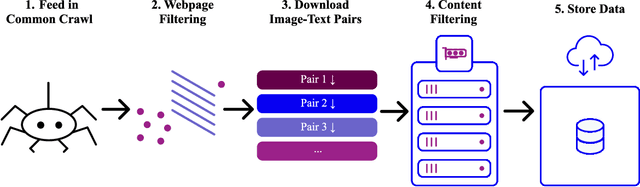
Groundbreaking language-vision architectures like CLIP and DALL-E proved the utility of training on large amounts of noisy image-text data, without relying on expensive accurate labels used in standard vision unimodal supervised learning. The resulting models showed capabilities of strong text-guided image generation and transfer to downstream tasks, while performing remarkably at zero-shot classification with noteworthy out-of-distribution robustness. Since then, large-scale language-vision models like ALIGN, BASIC, GLIDE, Flamingo and Imagen made further improvements. Studying the training and capabilities of such models requires datasets containing billions of image-text pairs. Until now, no datasets of this size have been made openly available for the broader research community. To address this problem and democratize research on large-scale multi-modal models, we present LAION-5B - a dataset consisting of 5.85 billion CLIP-filtered image-text pairs, of which 2.32B contain English language. We show successful replication and fine-tuning of foundational models like CLIP, GLIDE and Stable Diffusion using the dataset, and discuss further experiments enabled with an openly available dataset of this scale. Additionally we provide several nearest neighbor indices, an improved web-interface for dataset exploration and subset generation, and detection scores for watermark, NSFW, and toxic content detection. Announcement page https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/
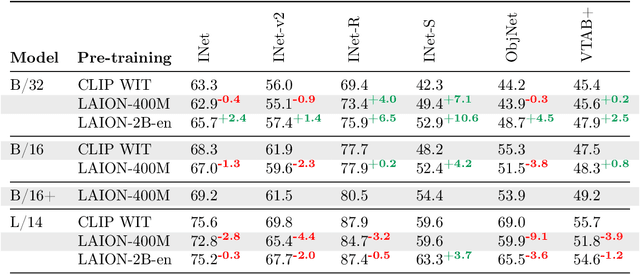
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Nov 03, 2021

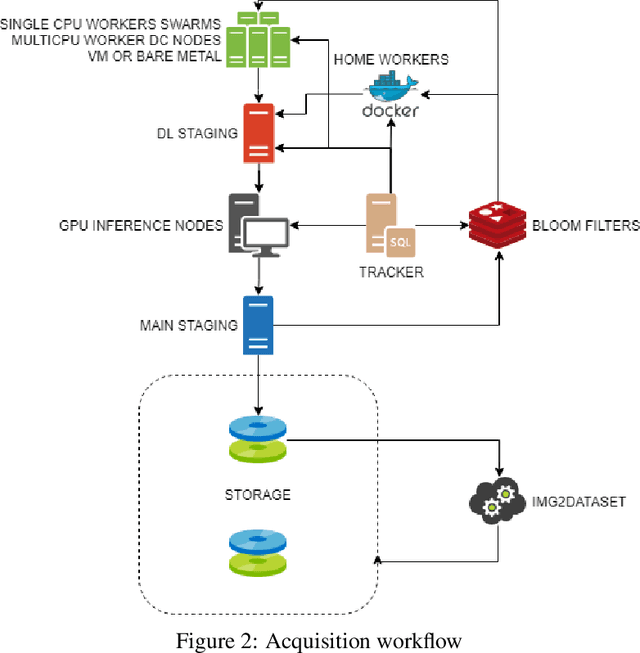
Multi-modal language-vision models trained on hundreds of millions of image-text pairs (e.g. CLIP, DALL-E) gained a recent surge, showing remarkable capability to perform zero- or few-shot learning and transfer even in absence of per-sample labels on target image data. Despite this trend, to date there has been no publicly available datasets of sufficient scale for training such models from scratch. To address this issue, in a community effort we build and release for public LAION-400M, a dataset with CLIP-filtered 400 million image-text pairs, their CLIP embeddings and kNN indices that allow efficient similarity search.
What Users Want? WARHOL: A Generative Model for Recommendation
Sep 02, 2021


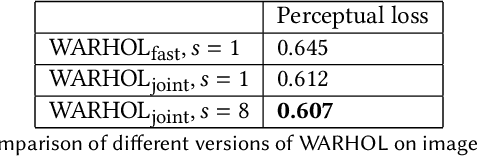
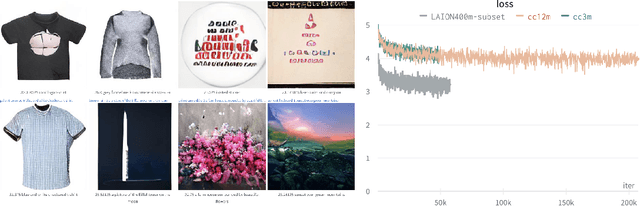
Current recommendation approaches help online merchants predict, for each visiting user, which subset of their existing products is the most relevant. However, besides being interested in matching users with existing products, merchants are also interested in understanding their users' underlying preferences. This could indeed help them produce or acquire better matching products in the future. We argue that existing recommendation models cannot directly be used to predict the optimal combination of features that will make new products serve better the needs of the target audience. To tackle this, we turn to generative models, which allow us to learn explicitly distributions over product feature combinations both in text and visual space. We develop WARHOL, a product generation and recommendation architecture that takes as input past user shopping activity and generates relevant textual and visual descriptions of novel products. We show that WARHOL can approach the performance of state-of-the-art recommendation models, while being able to generate entirely new products that are relevant to the given user profiles.