 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARB: Advanced Reasoning Benchmark for Large Language Models
Jul 28, 2023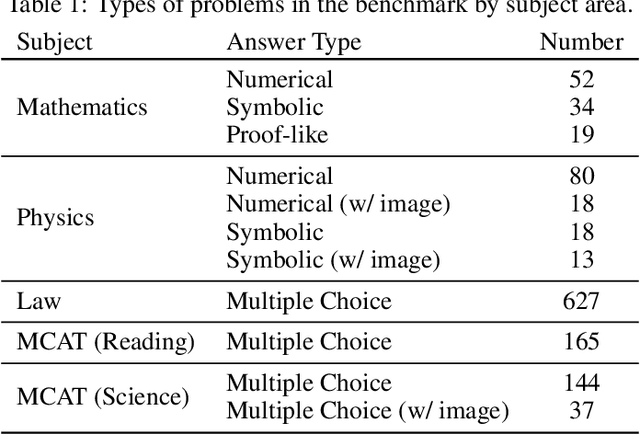
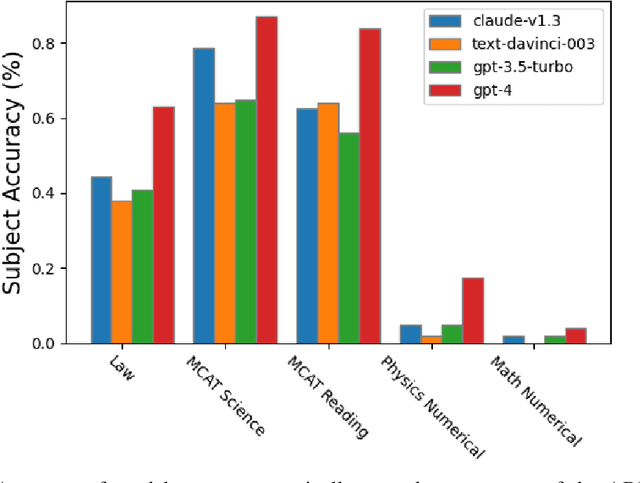


Large Language Models (LLMs) have demonstrated remarkable performance on various quantitative reasoning and knowledge benchmarks. However, many of these benchmarks are losing utility as LLMs get increasingly high scores, despite not yet reaching expert performance in these domains. We introduce ARB, a novel benchmark composed of advanced reasoning problems in multiple fields. ARB presents a more challenging test than prior benchmarks, featuring problems in mathematics, physics, biology, chemistry, and law. As a subset of ARB, we introduce a challenging set of math and physics problems which require advanced symbolic reasoning and domain knowledge. We evaluate recent models such as GPT-4 and Claude on ARB and demonstrate that current models score well below 50% on more demanding tasks. In order to improve both automatic and assisted evaluation capabilities, we introduce a rubric-based evaluation approach, allowing GPT-4 to score its own intermediate reasoning steps. Further, we conduct a human evaluation of the symbolic subset of ARB, finding promising agreement between annotators and GPT-4 rubric evaluation scores.
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints
Dec 09, 2022



Training large, deep neural networks to convergence can be prohibitively expensive. As a result, often only a small selection of popular, dense models are reused across different contexts and tasks. Increasingly, sparsely activated models, which seek to decouple model size from computation costs, are becoming an attractive alternative to dense models. Although more efficient in terms of quality and computation cost, sparse models remain data-hungry and costly to train from scratch in the large scale regime. In this work, we propose sparse upcycling -- a simple way to reuse sunk training costs by initializing a sparsely activated Mixture-of-Experts model from a dense checkpoint. We show that sparsely upcycled T5 Base, Large, and XL language models and Vision Transformer Base and Large models, respectively, significantly outperform their dense counterparts on SuperGLUE and ImageNet, using only ~50% of the initial dense pretraining sunk cost. The upcycled models also outperform sparse models trained from scratch on 100% of the initial dense pretraining computation budget.
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Nov 03, 2021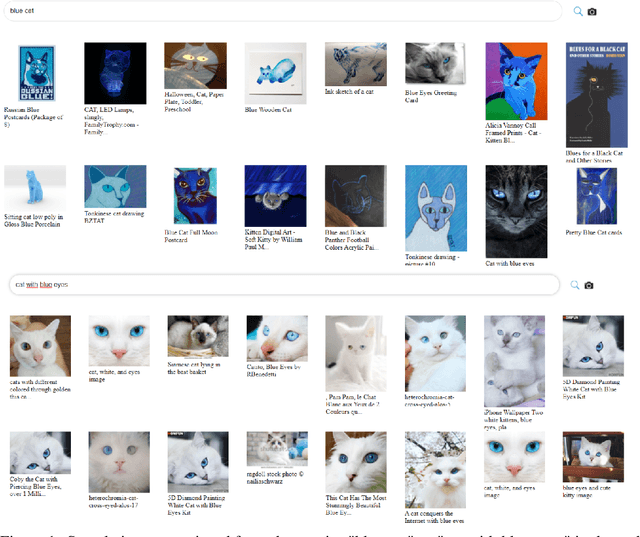

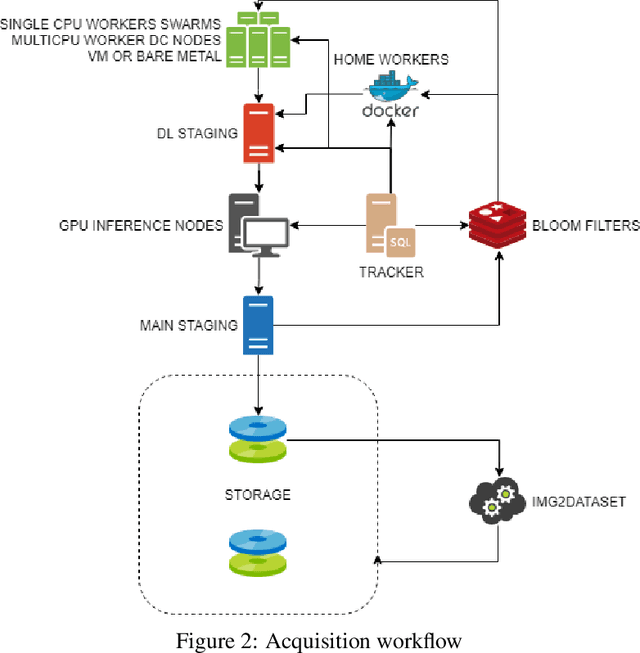
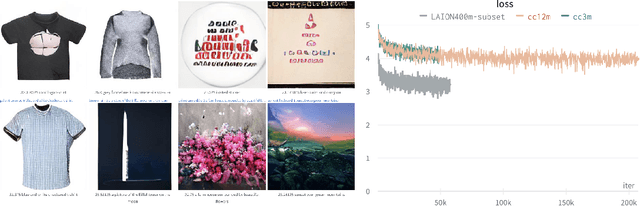
Multi-modal language-vision models trained on hundreds of millions of image-text pairs (e.g. CLIP, DALL-E) gained a recent surge, showing remarkable capability to perform zero- or few-shot learning and transfer even in absence of per-sample labels on target image data. Despite this trend, to date there has been no publicly available datasets of sufficient scale for training such models from scratch. To address this issue, in a community effort we build and release for public LAION-400M, a dataset with CLIP-filtered 400 million image-text pairs, their CLIP embeddings and kNN indices that allow efficient similarity search.
Current Limitations of Language Models: What You Need is Retrieval
Sep 15, 2020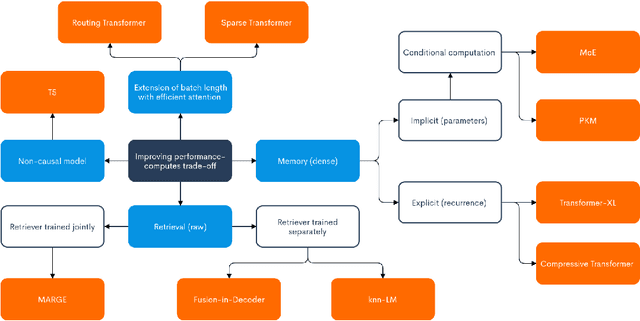


We classify and re-examine some of the current approaches to improve the performance-computes trade-off of language models, including (1) non-causal models (such as masked language models), (2) extension of batch length with efficient attention, (3) recurrence, (4) conditional computation and (5) retrieval. We identify some limitations (1) - (4) suffer from. For example, (1) currently struggles with open-ended text generation with the output loosely constrained by the input as well as performing general textual tasks like GPT-2/3 due to its need for a specific fine-tuning dataset. (2) and (3) do not improve the prediction of the first $\sim 10^3$ tokens. Scaling up a model size (e.g. efficiently with (4)) still results in poor performance scaling for some tasks. We argue (5) would resolve many of these limitations, and it can (a) reduce the amount of supervision and (b) efficiently extend the context over the entire training dataset and the entire past of the current sample. We speculate how to modify MARGE to perform unsupervised causal modeling that achieves (b) with the retriever jointly trained.
One Epoch Is All You Need
Jun 16, 2019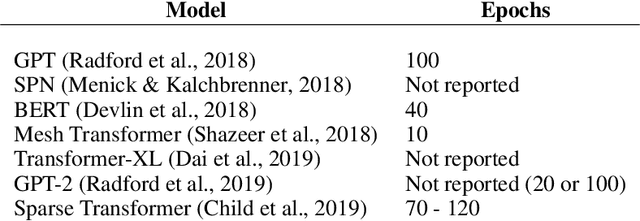



In unsupervised learning, collecting more data is not always a costly process unlike the training. For example, it is not hard to enlarge the 40GB WebText used for training GPT-2 by modifying its sampling methodology considering how many webpages there are in the Internet. On the other hand, given that training on this dataset already costs tens of thousands of dollars, training on a larger dataset naively is not cost-wise feasible. In this paper, we suggest to train on a larger dataset for only one epoch unlike the current practice, in which the unsupervised models are trained for from tens to hundreds of epochs. Furthermore, we suggest to adjust the model size and the number of iterations to be performed appropriately. We show that the performance of Transformer language model becomes dramatically improved in this way, especially if the original number of epochs is greater. For example, by replacing the training for 10 epochs with the one epoch training, this translates to 1.9-3.3x speedup in wall-clock time in our settings and more if the original number of epochs is greater. Under one epoch training, no overfitting occurs, and regularization method does nothing but slows down the training. Also, the curve of test loss over iterations follows power-law extensively. We compare the wall-clock time of the training of models with different parameter budget under one epoch training, and we show that size/iteration adjustment based on our proposed heuristics leads to 1-2.7x speedup in our cases. With the two methods combined, we achieve 3.3-5.1x speedup. Finally, we speculate various implications of one epoch training and size/iteration adjustment. In particular, based on our analysis we believe that we can reduce the cost to train the state-of-the-art models as BERT and GPT-2 dramatically, maybe even by the factor of 10.
Extractive Summary as Discrete Latent Variables
Nov 14, 2018
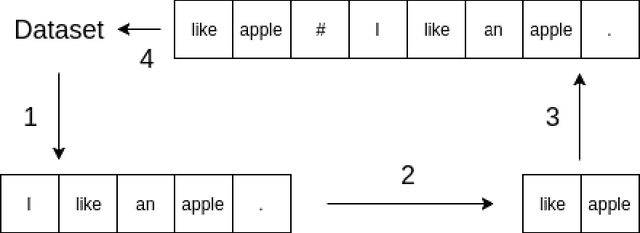


In this paper, we compare various methods to compress a text using a neural model. We found that extracting words as latent variables significantly outperforms the state-of-the-art discrete latent variable models such as VQ-VAE. Furthermore, we compare various extractive compression schemes. There are two best-performing methods that perform equally. One method is to simply choose the tokens with the highest tf-idf scores. Another is to train a bidirectional language model similar to ELMo and choose the tokens with the highest loss. If we consider any subsequence of text to be a text in a broader sense, we conclude that language is a strong compression code of itself. Our finding justifies the high quality of generation achieved with hierarchical method as in \citep{hier}, as their latent variables are nothing but natural language summary of the story. We also conclude that there is a hierarchy in language such that an entire text can be predicted much more easily based on a sequence of a small number of keywords, which can be easily found by classical methods as tf-idf. Therefore, we believe that this extraction process is crucial for generating discrete latent variables of text and, in particular, unsupervised hierarchical generation.