 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWHODUNIT: Evaluation benchmark for culprit detection in mystery stories
Feb 11, 2025We present a novel data set, WhoDunIt, to assess the deductive reasoning capabilities of large language models (LLM) within narrative contexts. Constructed from open domain mystery novels and short stories, the dataset challenges LLMs to identify the perpetrator after reading and comprehending the story. To evaluate model robustness, we apply a range of character-level name augmentations, including original names, name swaps, and substitutions with well-known real and/or fictional entities from popular discourse. We further use various prompting styles to investigate the influence of prompting on deductive reasoning accuracy. We conduct evaluation study with state-of-the-art models, specifically GPT-4o, GPT-4-turbo, and GPT-4o-mini, evaluated through multiple trials with majority response selection to ensure reliability. The results demonstrate that while LLMs perform reliably on unaltered texts, accuracy diminishes with certain name substitutions, particularly those with wide recognition. This dataset is publicly available here.
Robin: a Suite of Multi-Scale Vision-Language Models and the CHIRP Evaluation Benchmark
Jan 16, 2025



The proliferation of Vision-Language Models (VLMs) in the past several years calls for rigorous and comprehensive evaluation methods and benchmarks. This work analyzes existing VLM evaluation techniques, including automated metrics, AI-based assessments, and human evaluations across diverse tasks. We first introduce Robin - a novel suite of VLMs that we built by combining Large Language Models (LLMs) and Vision Encoders (VEs) at multiple scales, and use Robin to identify shortcomings of current evaluation approaches across scales. Next, to overcome the identified limitations, we introduce CHIRP - a new long form response benchmark we developed for more robust and complete VLM evaluation. We provide open access to the Robin training code, model suite, and CHIRP benchmark to promote reproducibility and advance VLM research.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024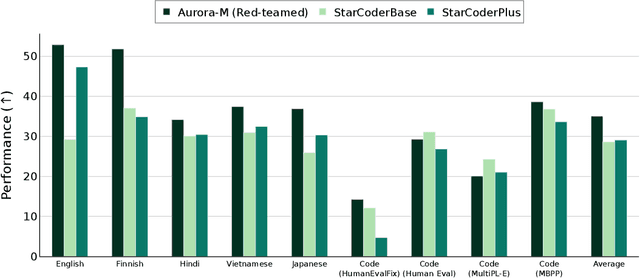

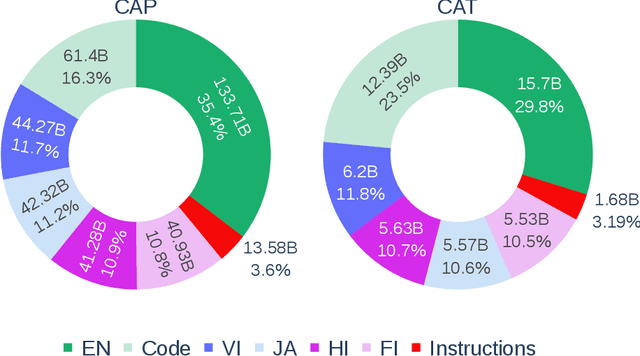
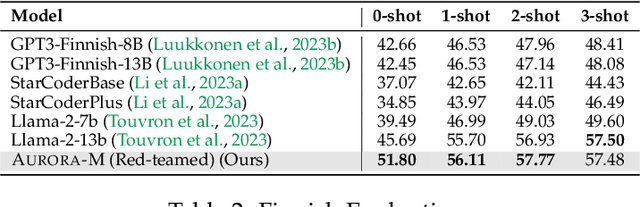
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
Simple and Scalable Strategies to Continually Pre-train Large Language Models
Mar 26, 2024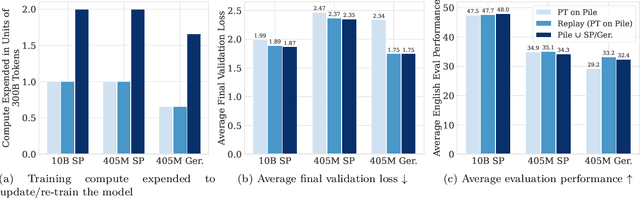
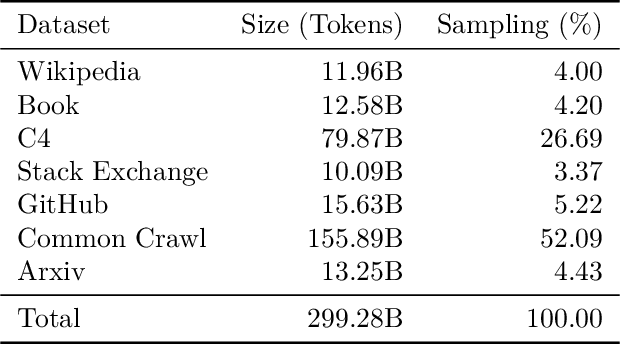
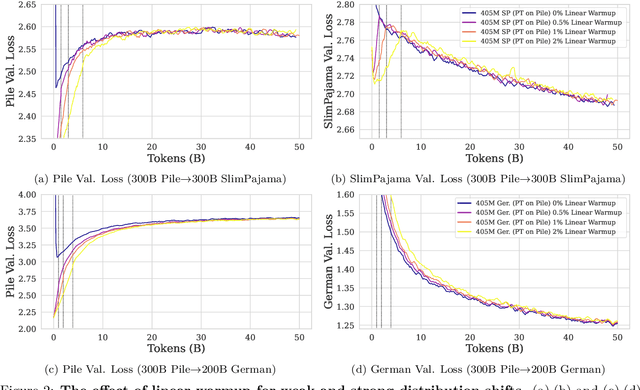
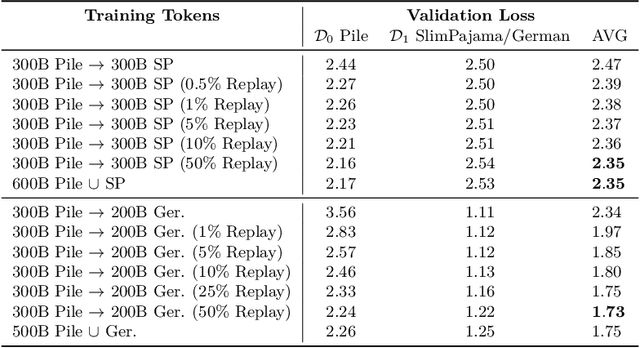
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre-train these models, saving significant compute compared to re-training. However, the distribution shift induced by new data typically results in degraded performance on previous data or poor adaptation to the new data. In this work, we show that a simple and scalable combination of learning rate (LR) re-warming, LR re-decaying, and replay of previous data is sufficient to match the performance of fully re-training from scratch on all available data, as measured by the final loss and the average score on several language model (LM) evaluation benchmarks. Specifically, we show this for a weak but realistic distribution shift between two commonly used LLM pre-training datasets (English$\rightarrow$English) and a stronger distribution shift (English$\rightarrow$German) at the $405$M parameter model scale with large dataset sizes (hundreds of billions of tokens). Selecting the weak but realistic shift for larger-scale experiments, we also find that our continual learning strategies match the re-training baseline for a 10B parameter LLM. Our results demonstrate that LLMs can be successfully updated via simple and scalable continual learning strategies, matching the re-training baseline using only a fraction of the compute. Finally, inspired by previous work, we propose alternatives to the cosine learning rate schedule that help circumvent forgetting induced by LR re-warming and that are not bound to a fixed token budget.
Continual Pre-Training of Large Language Models: How to (re)warm your model?
Aug 08, 2023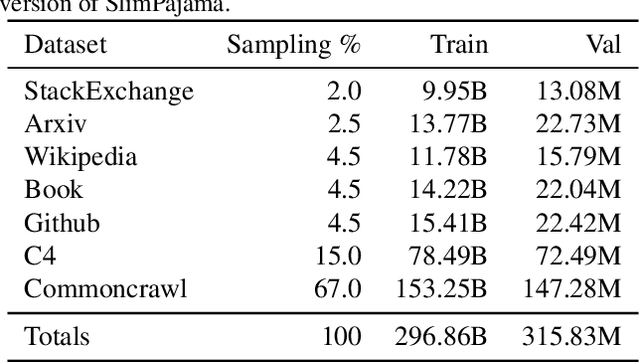
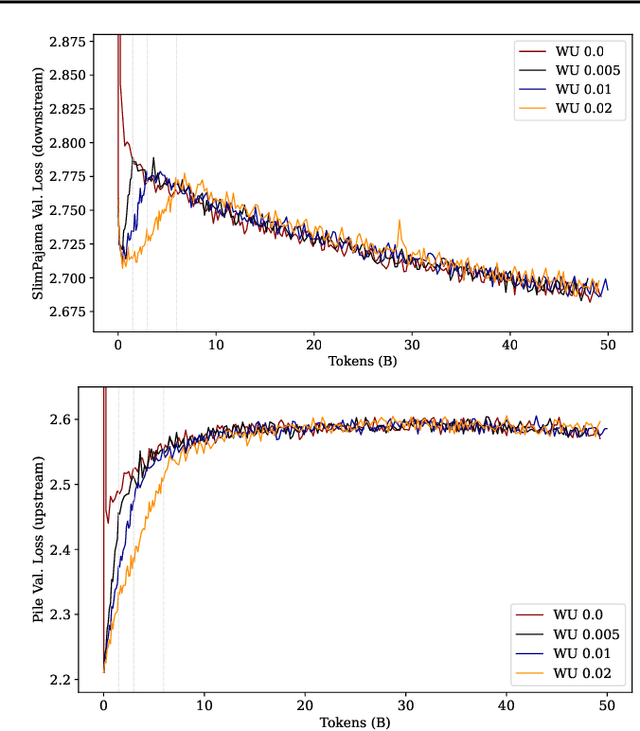
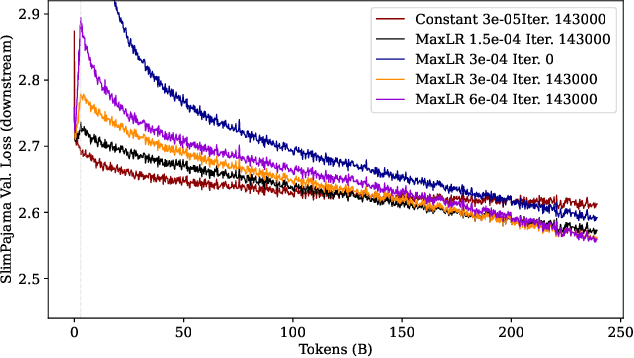
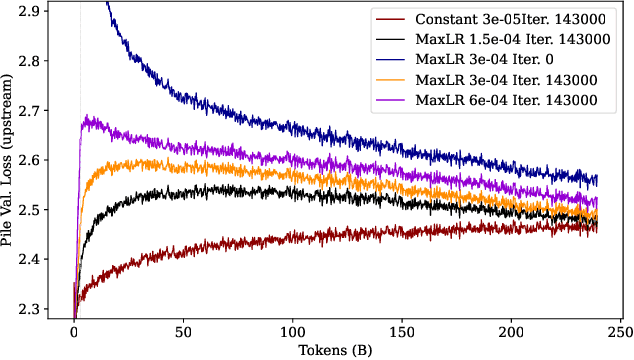
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to restart the process over again once new data becomes available. A much cheaper and more efficient solution would be to enable the continual pre-training of these models, i.e. updating pre-trained models with new data instead of re-training them from scratch. However, the distribution shift induced by novel data typically results in degraded performance on past data. Taking a step towards efficient continual pre-training, in this work, we examine the effect of different warm-up strategies. Our hypothesis is that the learning rate must be re-increased to improve compute efficiency when training on a new dataset. We study the warmup phase of models pre-trained on the Pile (upstream data, 300B tokens) as we continue to pre-train on SlimPajama (downstream data, 297B tokens), following a linear warmup and cosine decay schedule. We conduct all experiments on the Pythia 410M language model architecture and evaluate performance through validation perplexity. We experiment with different pre-training checkpoints, various maximum learning rates, and various warmup lengths. Our results show that while rewarming models first increases the loss on upstream and downstream data, in the longer run it improves the downstream performance, outperforming models trained from scratch$\unicode{x2013}$even for a large downstream dataset.
ARB: Advanced Reasoning Benchmark for Large Language Models
Jul 28, 2023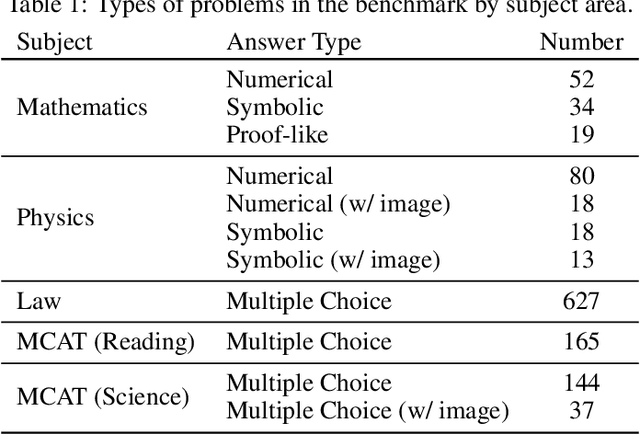
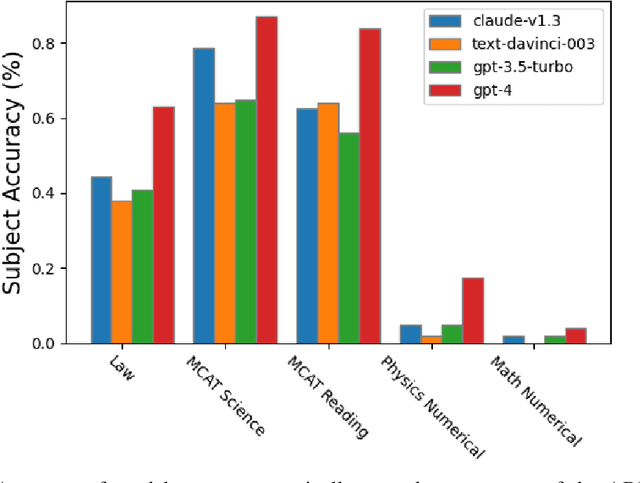


Large Language Models (LLMs) have demonstrated remarkable performance on various quantitative reasoning and knowledge benchmarks. However, many of these benchmarks are losing utility as LLMs get increasingly high scores, despite not yet reaching expert performance in these domains. We introduce ARB, a novel benchmark composed of advanced reasoning problems in multiple fields. ARB presents a more challenging test than prior benchmarks, featuring problems in mathematics, physics, biology, chemistry, and law. As a subset of ARB, we introduce a challenging set of math and physics problems which require advanced symbolic reasoning and domain knowledge. We evaluate recent models such as GPT-4 and Claude on ARB and demonstrate that current models score well below 50% on more demanding tasks. In order to improve both automatic and assisted evaluation capabilities, we introduce a rubric-based evaluation approach, allowing GPT-4 to score its own intermediate reasoning steps. Further, we conduct a human evaluation of the symbolic subset of ARB, finding promising agreement between annotators and GPT-4 rubric evaluation scores.
Broken Neural Scaling Laws
Nov 10, 2022We present a smoothly broken power law functional form that accurately models and extrapolates the scaling behaviors of deep neural networks (i.e. how the evaluation metric of interest varies as the amount of compute used for training, number of model parameters, training dataset size, or upstream performance varies) for each task within a large and diverse set of upstream and downstream tasks, in zero-shot, prompted, and fine-tuned settings. This set includes large-scale vision and unsupervised language tasks, diffusion generative modeling of images, arithmetic, and reinforcement learning. When compared to other functional forms for neural scaling behavior, this functional form yields extrapolations of scaling behavior that are considerably more accurate on this set. Moreover, this functional form accurately models and extrapolates scaling behavior that other functional forms are incapable of expressing such as the non-monotonic transitions present in the scaling behavior of phenomena such as double descent and the delayed, sharp inflection points present in the scaling behavior of tasks such as arithmetic. Lastly, we use this functional form to glean insights about the limit of the predictability of scaling behavior. Code is available at https://github.com/ethancaballero/broken_neural_scaling_laws
Data Augmentation for Automated Essay Scoring using Transformer Models
Oct 29, 2022


Automated essay scoring is one of the most important problem in Natural Language Processing. It has been explored for a number of years, and it remains partially solved. In addition to its economic and educational usefulness, it presents research problems. Transfer learning has proved to be beneficial in NLP. Data augmentation techniques have also helped build state-of-the-art models for automated essay scoring. Many works in the past have attempted to solve this problem by using RNNs, LSTMs, etc. This work examines the transformer models like BERT, RoBERTa, etc. We empirically demonstrate the effectiveness of transformer models and data augmentation for automated essay grading across many topics using a single model.
MALM: Mixing Augmented Language Modeling for Zero-Shot Machine Translation
Oct 01, 2022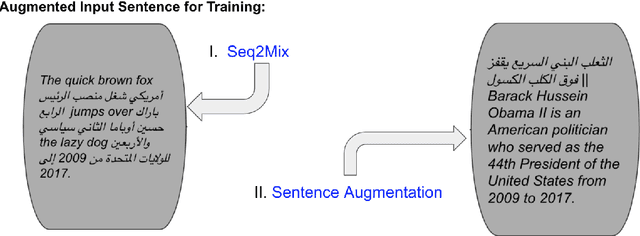
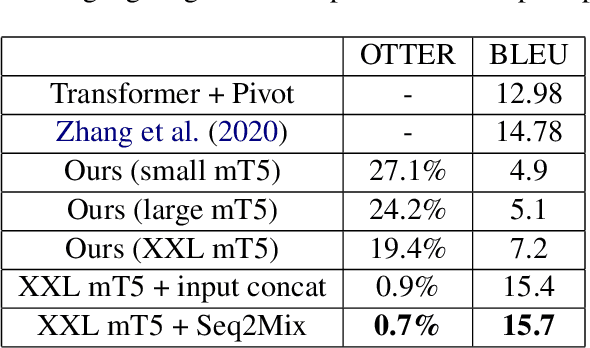
Large pre-trained language models have brought remarkable progress in NLP. Pre-training and Fine-tuning have given state-of-art performance across tasks in text processing. Data Augmentation techniques have also helped build state-of-art models on low or zero resource tasks. Many works in the past have attempted at learning a single massively-multilingual machine translation model for zero-shot translation. Although those translation models are producing correct translations, the main challenge is those models are producing the wrong languages for zero-shot translation. This work and its results indicate that prompt conditioned large models do not suffer from off-target language errors i.e. errors arising due to translation to wrong languages. We empirically demonstrate the effectiveness of self-supervised pre-training and data augmentation for zero-shot multi-lingual machine translation.
cViL: Cross-Lingual Training of Vision-Language Models using Knowledge Distillation
Jun 09, 2022
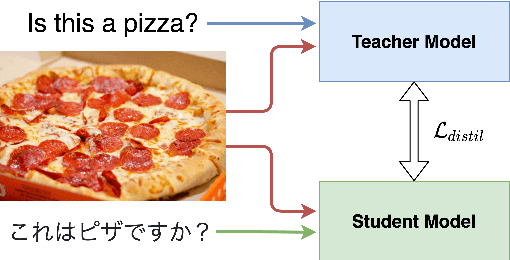

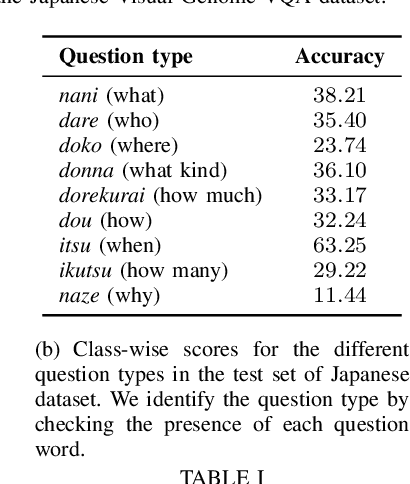
Vision-and-language tasks are gaining popularity in the research community, but the focus is still mainly on English. We propose a pipeline that utilizes English-only vision-language models to train a monolingual model for a target language. We propose to extend OSCAR+, a model which leverages object tags as anchor points for learning image-text alignments, to train on visual question answering datasets in different languages. We propose a novel approach to knowledge distillation to train the model in other languages using parallel sentences. Compared to other models that use the target language in the pretraining corpora, we can leverage an existing English model to transfer the knowledge to the target language using significantly lesser resources. We also release a large-scale visual question answering dataset in Japanese and Hindi language. Though we restrict our work to visual question answering, our model can be extended to any sequence-level classification task, and it can be extended to other languages as well. This paper focuses on two languages for the visual question answering task - Japanese and Hindi. Our pipeline outperforms the current state-of-the-art models by a relative increase of 4.4% and 13.4% respectively in accuracy.