 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Optimal Reasoning Length for RL-Trained Language Models
Feb 11, 2026Reinforcement learning substantially improves reasoning in large language models, but it also tends to lengthen chain of thought outputs and increase computational cost during both training and inference. Though length control methods have been proposed, it remains unclear what the optimal output length is for balancing efficiency and performance. In this work, we compare several length control methods on two models, Qwen3-1.7B Base and DeepSeek-R1-Distill-Qwen-1.5B. Our results indicate that length penalties may hinder reasoning acquisition, while properly tuned length control can improve efficiency for models with strong prior reasoning. By extending prior work to RL trained policies, we identify two failure modes, 1) long outputs increase dispersion, and 2) short outputs lead to under-thinking.
Open-sci-ref-0.01: open and reproducible reference baselines for language model and dataset comparison
Sep 10, 2025We introduce open-sci-ref, a family of dense transformer models trained as research baselines across multiple model (0.13B to 1.7B parameters) and token scales (up to 1T) on 8 recent open reference datasets. Evaluating the models on various standardized benchmarks, our training runs set establishes reference points that enable researchers to assess the sanity and quality of alternative training approaches across scales and datasets. Intermediate checkpoints allow comparison and studying of the training dynamics. The established reference baselines allow training procedures to be compared through their scaling trends, aligning them on a common compute axis. Comparison of open reference datasets reveals that training on NemoTron-CC HQ consistently outperforms other reference datasets, followed by DCLM-baseline and FineWeb-Edu. In addition to intermediate training checkpoints, the release includes logs, code, and downstream evaluations to simplify reproduction, standardize comparison, and facilitate future research.
Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks
Aug 26, 2025Empirical scaling laws have driven the evolution of large language models (LLMs), yet their coefficients shift whenever the model architecture or data pipeline changes. Mixture-of-Experts (MoE) models, now standard in state-of-the-art systems, introduce a new sparsity dimension that current dense-model frontiers overlook. We investigate how MoE sparsity influences two distinct capability regimes: memorization and reasoning. We train families of MoE Transformers that systematically vary total parameters, active parameters, and top-$k$ routing while holding the compute budget fixed. For every model we record pre-training loss, downstream task loss, and task accuracy, allowing us to separate the train-test generalization gap from the loss-accuracy gap. Memorization benchmarks improve monotonically with total parameters, mirroring training loss. By contrast, reasoning performance saturates and can even regress despite continued gains in both total parameters and training loss. Altering top-$k$ alone has little effect when active parameters are constant, and classic hyperparameters such as learning rate and initialization modulate the generalization gap in the same direction as sparsity. Neither post-training reinforcement learning (GRPO) nor extra test-time compute rescues the reasoning deficit of overly sparse models. Our model checkpoints, code and logs are open-source at https://github.com/rioyokotalab/optimal-sparsity.
Rewriting Pre-Training Data Boosts LLM Performance in Math and Code
May 05, 2025The performance of large language models (LLMs) in program synthesis and mathematical reasoning is fundamentally limited by the quality of their pre-training corpora. We introduce two openly licensed datasets, released under the Llama 3.3 Community License, that significantly enhance LLM performance by systematically rewriting public data. SwallowCode (approximately 16.1 billion tokens) refines Python snippets from The-Stack-v2 through a novel four-stage pipeline: syntax validation, pylint-based style filtering, and a two-stage LLM rewriting process that enforces style conformity and transforms snippets into self-contained, algorithmically efficient examples. Unlike prior methods that rely on exclusionary filtering or limited transformations, our transform-and-retain approach upgrades low-quality code, maximizing data utility. SwallowMath (approximately 2.3 billion tokens) enhances Finemath-4+ by removing boilerplate, restoring context, and reformatting solutions into concise, step-by-step explanations. Within a fixed 50 billion token training budget, continual pre-training of Llama-3.1-8B with SwallowCode boosts pass@1 by +17.0 on HumanEval and +17.7 on HumanEval+ compared to Stack-Edu, surpassing the baseline model's code generation capabilities. Similarly, substituting SwallowMath yields +12.4 accuracy on GSM8K and +7.6 on MATH. Ablation studies confirm that each pipeline stage contributes incrementally, with rewriting delivering the largest gains. All datasets, prompts, and checkpoints are publicly available, enabling reproducible research and advancing LLM pre-training for specialized domains.
Building Instruction-Tuning Datasets from Human-Written Instructions with Open-Weight Large Language Models
Mar 31, 2025Instruction tuning is crucial for enabling Large Language Models (LLMs) to solve real-world tasks. Prior work has shown the effectiveness of instruction-tuning data synthesized solely from LLMs, raising a fundamental question: Do we still need human-originated signals for instruction tuning? This work answers the question affirmatively: we build state-of-the-art instruction-tuning datasets sourced from human-written instructions, by simply pairing them with LLM-generated responses. LLMs fine-tuned on our datasets consistently outperform those fine-tuned on existing ones. Our data construction approach can be easily adapted to other languages; we build datasets for Japanese and confirm that LLMs tuned with our data reach state-of-the-art performance. Analyses suggest that instruction-tuning in a new language allows LLMs to follow instructions, while the tuned models exhibit a notable lack of culture-specific knowledge in that language. The datasets and fine-tuned models will be publicly available. Our datasets, synthesized with open-weight LLMs, are openly distributed under permissive licenses, allowing for diverse use cases.
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search
Mar 06, 2025

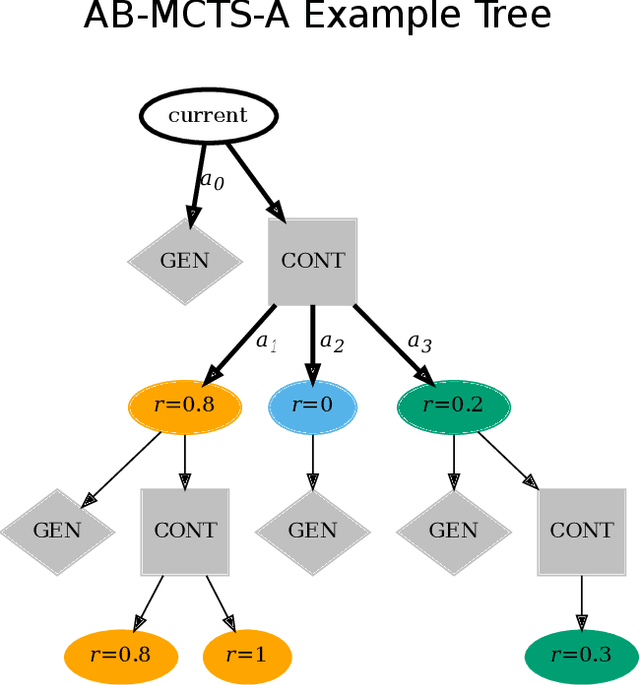

Recent advances demonstrate that increasing inference-time computation can significantly boost the reasoning capabilities of large language models (LLMs). Although repeated sampling (i.e., generating multiple candidate outputs) is a highly effective strategy, it does not leverage external feedback signals for refinement, which are often available in tasks like coding. In this work, we propose $\textit{Adaptive Branching Monte Carlo Tree Search (AB-MCTS)}$, a novel inference-time framework that generalizes repeated sampling with principled multi-turn exploration and exploitation. At each node in the search tree, AB-MCTS dynamically decides whether to "go wider" by expanding new candidate responses or "go deeper" by revisiting existing ones based on external feedback signals. We evaluate our method on complex coding and engineering tasks using frontier models. Empirical results show that AB-MCTS consistently outperforms both repeated sampling and standard MCTS, underscoring the importance of combining the response diversity of LLMs with multi-turn solution refinement for effective inference-time scaling.
Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization
Feb 26, 2025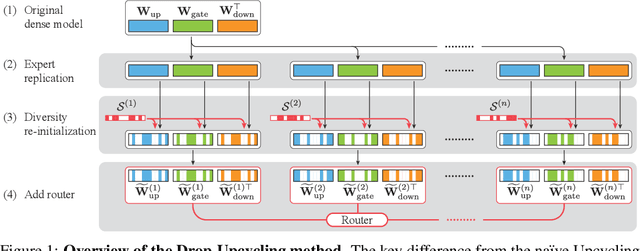
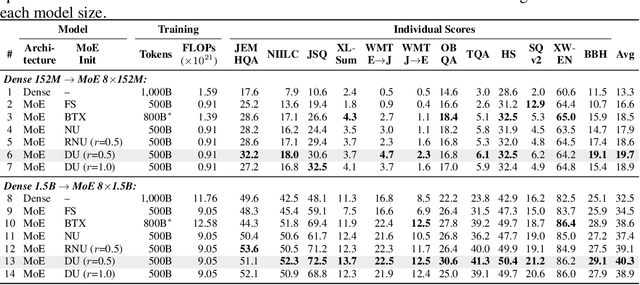
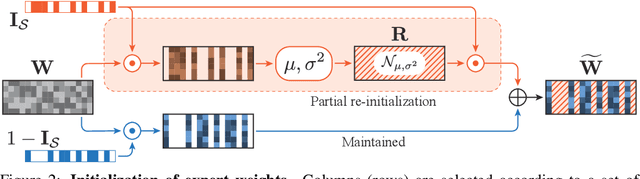
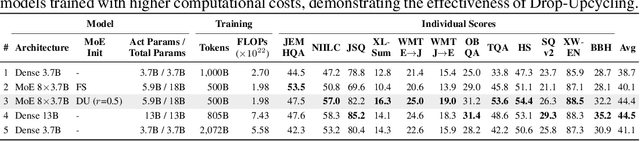
The Mixture of Experts (MoE) architecture reduces the training and inference cost significantly compared to a dense model of equivalent capacity. Upcycling is an approach that initializes and trains an MoE model using a pre-trained dense model. While upcycling leads to initial performance gains, the training progresses slower than when trained from scratch, leading to suboptimal performance in the long term. We propose Drop-Upcycling - a method that effectively addresses this problem. Drop-Upcycling combines two seemingly contradictory approaches: utilizing the knowledge of pre-trained dense models while statistically re-initializing some parts of the weights. This approach strategically promotes expert specialization, significantly enhancing the MoE model's efficiency in knowledge acquisition. Extensive large-scale experiments demonstrate that Drop-Upcycling significantly outperforms previous MoE construction methods in the long term, specifically when training on hundreds of billions of tokens or more. As a result, our MoE model with 5.9B active parameters achieves comparable performance to a 13B dense model in the same model family, while requiring approximately 1/4 of the training FLOPs. All experimental resources, including source code, training data, model checkpoints and logs, are publicly available to promote reproducibility and future research on MoE.
Why We Build Local Large Language Models: An Observational Analysis from 35 Japanese and Multilingual LLMs
Dec 19, 2024



Why do we build local large language models (LLMs)? What should a local LLM learn from the target language? Which abilities can be transferred from other languages? Do language-specific scaling laws exist? To explore these research questions, we evaluated 35 Japanese, English, and multilingual LLMs on 19 evaluation benchmarks for Japanese and English, taking Japanese as a local language. Adopting an observational approach, we analyzed correlations of benchmark scores, and conducted principal component analysis (PCA) on the scores to derive \textit{ability factors} of local LLMs. We found that training on English text can improve the scores of academic subjects in Japanese (JMMLU). In addition, it is unnecessary to specifically train on Japanese text to enhance abilities for solving Japanese code generation, arithmetic reasoning, commonsense, and reading comprehension tasks. In contrast, training on Japanese text could improve question-answering tasks about Japanese knowledge and English-Japanese translation, which indicates that abilities for solving these two tasks can be regarded as \textit{Japanese abilities} for LLMs. Furthermore, we confirmed that the Japanese abilities scale with the computational budget for Japanese text.
Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs
Nov 10, 2024
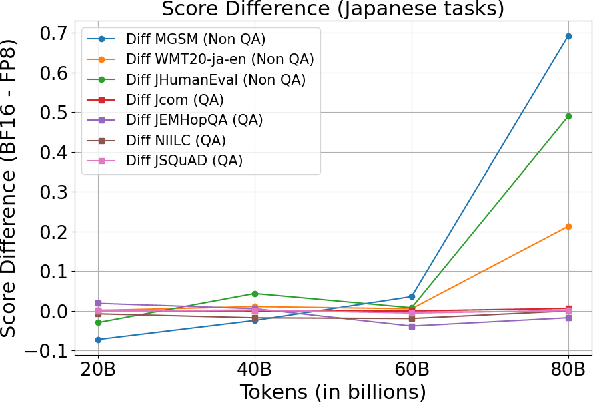

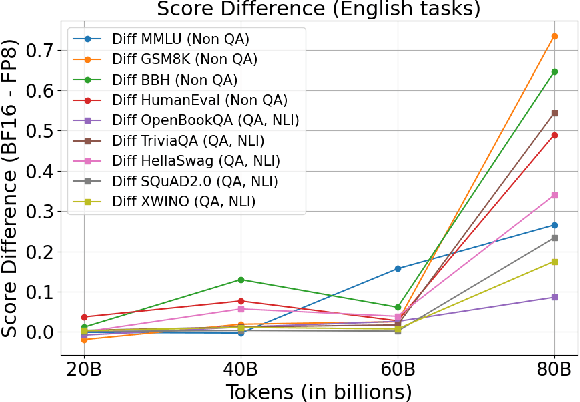
Large Language Models (LLMs) have attracted significant attention due to their human-like language understanding and generation capabilities, as well as their applicability across various domains. These models, characterized by their massive scale and extensive training data, continue to push the boundaries of what is possible in natural language processing. The Llama 3 series, for instance, exemplifies this trend with its flagship model boasting 405 billion parameters trained on 15.6 trillion tokens. The immense computational demands associated with training such models have spurred ongoing research into optimizing the efficiency of the training process, particularly through the use of lower-precision formats. NVIDIA's H100 GPU, which introduces support for FP8 in addition to the more conventional FP16 and BF16 formats, has emerged as a focal point in this optimization effort. Preliminary studies suggest that FP8 could offer substantial reductions in training time without sacrificing model performance when compared to BF16, making it a promising candidate for large-scale model training. However, the broader implications of adopting FP8, particularly in terms of training stability and downstream task performance, have yet to be fully understood. In this study, we delve into the practical trade-offs involved in adopting FP8 over BF16 for training LLMs.
Agent Skill Acquisition for Large Language Models via CycleQD
Oct 16, 2024



Training large language models to acquire specific skills remains a challenging endeavor. Conventional training approaches often struggle with data distribution imbalances and inadequacies in objective functions that do not align well with task-specific performance. To address these challenges, we introduce CycleQD, a novel approach that leverages the Quality Diversity framework through a cyclic adaptation of the algorithm, along with a model merging based crossover and an SVD-based mutation. In CycleQD, each task's performance metric is alternated as the quality measure while the others serve as the behavioral characteristics. This cyclic focus on individual tasks allows for concentrated effort on one task at a time, eliminating the need for data ratio tuning and simplifying the design of the objective function. Empirical results from AgentBench indicate that applying CycleQD to LLAMA3-8B-INSTRUCT based models not only enables them to surpass traditional fine-tuning methods in coding, operating systems, and database tasks, but also achieves performance on par with GPT-3.5-TURBO, which potentially contains much more parameters, across these domains. Crucially, this enhanced performance is achieved while retaining robust language capabilities, as evidenced by its performance on widely adopted language benchmark tasks. We highlight the key design choices in CycleQD, detailing how these contribute to its effectiveness. Furthermore, our method is general and can be applied to image segmentation models, highlighting its applicability across different domains.