 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALE-Bench: A Benchmark for Long-Horizon Objective-Driven Algorithm Engineering
Jun 10, 2025
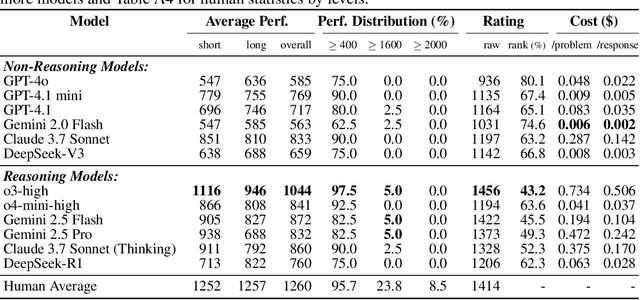


How well do AI systems perform in algorithm engineering for hard optimization problems in domains such as package-delivery routing, crew scheduling, factory production planning, and power-grid balancing? We introduce ALE-Bench, a new benchmark for evaluating AI systems on score-based algorithmic programming contests. Drawing on real tasks from the AtCoder Heuristic Contests, ALE-Bench presents optimization problems that are computationally hard and admit no known exact solution. Unlike short-duration, pass/fail coding benchmarks, ALE-Bench encourages iterative solution refinement over long time horizons. Our software framework supports interactive agent architectures that leverage test-run feedback and visualizations. Our evaluation of frontier LLMs revealed that while they demonstrate high performance on specific problems, a notable gap remains compared to humans in terms of consistency across problems and long-horizon problem-solving capabilities. This highlights the need for this benchmark to foster future AI advancements.
MangaVQA and MangaLMM: A Benchmark and Specialized Model for Multimodal Manga Understanding
May 26, 2025Manga, or Japanese comics, is a richly multimodal narrative form that blends images and text in complex ways. Teaching large multimodal models (LMMs) to understand such narratives at a human-like level could help manga creators reflect on and refine their stories. To this end, we introduce two benchmarks for multimodal manga understanding: MangaOCR, which targets in-page text recognition, and MangaVQA, a novel benchmark designed to evaluate contextual understanding through visual question answering. MangaVQA consists of 526 high-quality, manually constructed question-answer pairs, enabling reliable evaluation across diverse narrative and visual scenarios. Building on these benchmarks, we develop MangaLMM, a manga-specialized model finetuned from the open-source LMM Qwen2.5-VL to jointly handle both tasks. Through extensive experiments, including comparisons with proprietary models such as GPT-4o and Gemini 2.5, we assess how well LMMs understand manga. Our benchmark and model provide a comprehensive foundation for evaluating and advancing LMMs in the richly narrative domain of manga.
Sudoku-Bench: Evaluating creative reasoning with Sudoku variants
May 22, 2025



Existing reasoning benchmarks for large language models (LLMs) frequently fail to capture authentic creativity, often rewarding memorization of previously observed patterns. We address this shortcoming with Sudoku-Bench, a curated benchmark of challenging and unconventional Sudoku variants specifically selected to evaluate creative, multi-step logical reasoning. Sudoku variants form an unusually effective domain for reasoning research: each puzzle introduces unique or subtly interacting constraints, making memorization infeasible and requiring solvers to identify novel logical breakthroughs (``break-ins''). Despite their diversity, Sudoku variants maintain a common and compact structure, enabling clear and consistent evaluation. Sudoku-Bench includes a carefully chosen puzzle set, a standardized text-based puzzle representation, and flexible tools compatible with thousands of publicly available puzzles -- making it easy to extend into a general research environment. Baseline experiments show that state-of-the-art LLMs solve fewer than 15\% of puzzles unaided, highlighting significant opportunities to advance long-horizon, strategic reasoning capabilities.
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search
Mar 06, 2025

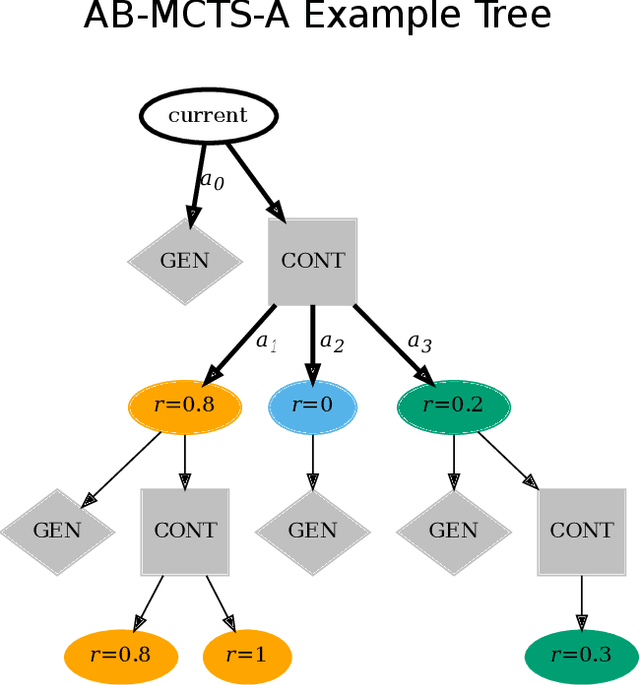

Recent advances demonstrate that increasing inference-time computation can significantly boost the reasoning capabilities of large language models (LLMs). Although repeated sampling (i.e., generating multiple candidate outputs) is a highly effective strategy, it does not leverage external feedback signals for refinement, which are often available in tasks like coding. In this work, we propose $\textit{Adaptive Branching Monte Carlo Tree Search (AB-MCTS)}$, a novel inference-time framework that generalizes repeated sampling with principled multi-turn exploration and exploitation. At each node in the search tree, AB-MCTS dynamically decides whether to "go wider" by expanding new candidate responses or "go deeper" by revisiting existing ones based on external feedback signals. We evaluate our method on complex coding and engineering tasks using frontier models. Empirical results show that AB-MCTS consistently outperforms both repeated sampling and standard MCTS, underscoring the importance of combining the response diversity of LLMs with multi-turn solution refinement for effective inference-time scaling.
JMMMU: A Japanese Massive Multi-discipline Multimodal Understanding Benchmark for Culture-aware Evaluation
Oct 22, 2024



Accelerating research on Large Multimodal Models (LMMs) in non-English languages is crucial for enhancing user experiences across broader populations. In this paper, we introduce JMMMU (Japanese MMMU), the first large-scale Japanese benchmark designed to evaluate LMMs on expert-level tasks based on the Japanese cultural context. To facilitate comprehensive culture-aware evaluation, JMMMU features two complementary subsets: (i) culture-agnostic (CA) subset, where the culture-independent subjects (e.g., Math) are selected and translated into Japanese, enabling one-to-one comparison with its English counterpart MMMU; and (ii) culture-specific (CS) subset, comprising newly crafted subjects that reflect Japanese cultural context. Using the CA subset, we observe performance drop in many LMMs when evaluated in Japanese, which is purely attributable to language variation. Using the CS subset, we reveal their inadequate Japanese cultural understanding. Further, by combining both subsets, we identify that some LMMs perform well on the CA subset but not on the CS subset, exposing a shallow understanding of the Japanese language that lacks depth in cultural understanding. We hope this work will not only help advance LMM performance in Japanese but also serve as a guideline to create high-standard, culturally diverse benchmarks for multilingual LMM development. The project page is https://mmmu-japanese-benchmark.github.io/JMMMU/.
FoodMLLM-JP: Leveraging Multimodal Large Language Models for Japanese Recipe Generation
Sep 27, 2024



Research on food image understanding using recipe data has been a long-standing focus due to the diversity and complexity of the data. Moreover, food is inextricably linked to people's lives, making it a vital research area for practical applications such as dietary management. Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities, not only in their vast knowledge but also in their ability to handle languages naturally. While English is predominantly used, they can also support multiple languages including Japanese. This suggests that MLLMs are expected to significantly improve performance in food image understanding tasks. We fine-tuned open MLLMs LLaVA-1.5 and Phi-3 Vision on a Japanese recipe dataset and benchmarked their performance against the closed model GPT-4o. We then evaluated the content of generated recipes, including ingredients and cooking procedures, using 5,000 evaluation samples that comprehensively cover Japanese food culture. Our evaluation demonstrates that the open models trained on recipe data outperform GPT-4o, the current state-of-the-art model, in ingredient generation. Our model achieved F1 score of 0.531, surpassing GPT-4o's F1 score of 0.481, indicating a higher level of accuracy. Furthermore, our model exhibited comparable performance to GPT-4o in generating cooking procedure text.