 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnMaskFork: Test-Time Scaling for Masked Diffusion via Deterministic Action Branching
Feb 04, 2026Test-time scaling strategies have effectively leveraged inference-time compute to enhance the reasoning abilities of Autoregressive Large Language Models. In this work, we demonstrate that Masked Diffusion Language Models (MDLMs) are inherently amenable to advanced search strategies, owing to their iterative and non-autoregressive generation process. To leverage this, we propose UnMaskFork (UMF), a framework that formulates the unmasking trajectory as a search tree and employs Monte Carlo Tree Search to optimize the generation path. In contrast to standard scaling methods relying on stochastic sampling, UMF explores the search space through deterministic partial unmasking actions performed by multiple MDLMs. Our empirical evaluation demonstrates that UMF consistently outperforms existing test-time scaling baselines on complex coding benchmarks, while also exhibiting strong scalability on mathematical reasoning tasks.
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search
Mar 06, 2025

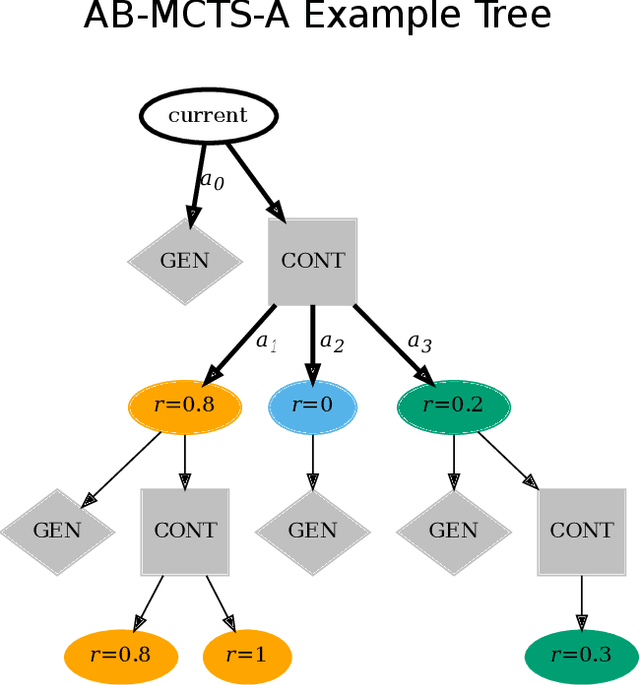

Recent advances demonstrate that increasing inference-time computation can significantly boost the reasoning capabilities of large language models (LLMs). Although repeated sampling (i.e., generating multiple candidate outputs) is a highly effective strategy, it does not leverage external feedback signals for refinement, which are often available in tasks like coding. In this work, we propose $\textit{Adaptive Branching Monte Carlo Tree Search (AB-MCTS)}$, a novel inference-time framework that generalizes repeated sampling with principled multi-turn exploration and exploitation. At each node in the search tree, AB-MCTS dynamically decides whether to "go wider" by expanding new candidate responses or "go deeper" by revisiting existing ones based on external feedback signals. We evaluate our method on complex coding and engineering tasks using frontier models. Empirical results show that AB-MCTS consistently outperforms both repeated sampling and standard MCTS, underscoring the importance of combining the response diversity of LLMs with multi-turn solution refinement for effective inference-time scaling.
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
Jan 29, 2025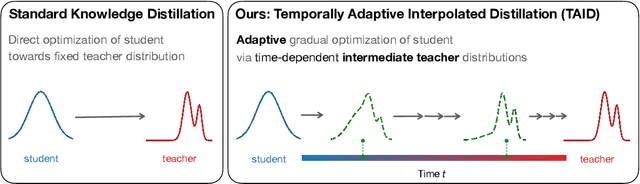
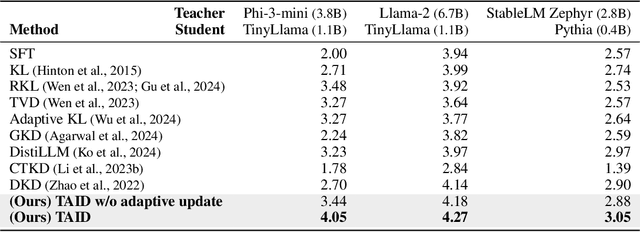
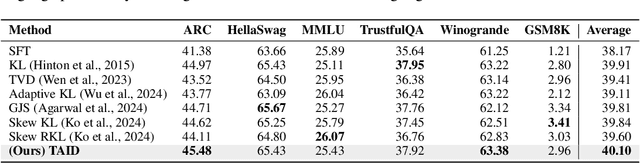
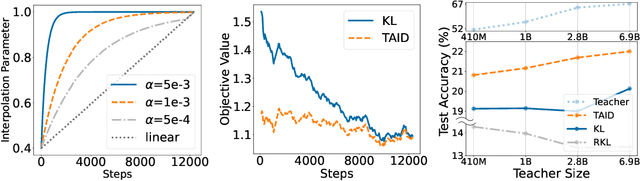
Causal language models have demonstrated remarkable capabilities, but their size poses significant challenges for deployment in resource-constrained environments. Knowledge distillation, a widely-used technique for transferring knowledge from a large teacher model to a small student model, presents a promising approach for model compression. A significant remaining issue lies in the major differences between teacher and student models, namely the substantial capacity gap, mode averaging, and mode collapse, which pose barriers during distillation. To address these issues, we introduce $\textit{Temporally Adaptive Interpolated Distillation (TAID)}$, a novel knowledge distillation approach that dynamically interpolates student and teacher distributions through an adaptive intermediate distribution, gradually shifting from the student's initial distribution towards the teacher's distribution. We provide a theoretical analysis demonstrating TAID's ability to prevent mode collapse and empirically show its effectiveness in addressing the capacity gap while balancing mode averaging and mode collapse. Our comprehensive experiments demonstrate TAID's superior performance across various model sizes and architectures in both instruction tuning and pre-training scenarios. Furthermore, we showcase TAID's practical impact by developing two state-of-the-art compact foundation models: $\texttt{TAID-LLM-1.5B}$ for language tasks and $\texttt{TAID-VLM-2B}$ for vision-language tasks. These results demonstrate TAID's effectiveness in creating high-performing and efficient models, advancing the development of more accessible AI technologies.