 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnMaskFork: Test-Time Scaling for Masked Diffusion via Deterministic Action Branching
Feb 04, 2026Test-time scaling strategies have effectively leveraged inference-time compute to enhance the reasoning abilities of Autoregressive Large Language Models. In this work, we demonstrate that Masked Diffusion Language Models (MDLMs) are inherently amenable to advanced search strategies, owing to their iterative and non-autoregressive generation process. To leverage this, we propose UnMaskFork (UMF), a framework that formulates the unmasking trajectory as a search tree and employs Monte Carlo Tree Search to optimize the generation path. In contrast to standard scaling methods relying on stochastic sampling, UMF explores the search space through deterministic partial unmasking actions performed by multiple MDLMs. Our empirical evaluation demonstrates that UMF consistently outperforms existing test-time scaling baselines on complex coding benchmarks, while also exhibiting strong scalability on mathematical reasoning tasks.
Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings
Dec 13, 2025



So far, expensive finetuning beyond the pretraining sequence length has been a requirement for effectively extending the context of language models (LM). In this work, we break this key bottleneck by Dropping the Positional Embeddings of LMs after training (DroPE). Our simple method is motivated by three key theoretical and empirical observations. First, positional embeddings (PEs) serve a crucial role during pretraining, providing an important inductive bias that significantly facilitates convergence. Second, over-reliance on this explicit positional information is also precisely what prevents test-time generalization to sequences of unseen length, even when using popular PE-scaling methods. Third, positional embeddings are not an inherent requirement of effective language modeling and can be safely removed after pretraining, following a short recalibration phase. Empirically, DroPE yields seamless zero-shot context extension without any long-context finetuning, quickly adapting pretrained LMs without compromising their capabilities in the original training context. Our findings hold across different models and dataset sizes, far outperforming previous specialized architectures and established rotary positional embedding scaling methods.
DiffusionBlocks: Blockwise Training for Generative Models via Score-Based Diffusion
Jun 17, 2025Training large neural networks with end-to-end backpropagation creates significant memory bottlenecks, limiting accessibility to state-of-the-art AI research. We propose $\textit{DiffusionBlocks}$, a novel training framework that interprets neural network blocks as performing denoising operations in a continuous-time diffusion process. By partitioning the network into independently trainable blocks and optimizing noise level assignments based on equal cumulative probability mass, our approach achieves significant memory efficiency while maintaining competitive performance compared to traditional backpropagation in generative tasks. Experiments on image generation and language modeling tasks demonstrate memory reduction proportional to the number of blocks while achieving superior performance. DiffusionBlocks provides a promising pathway for democratizing access to large-scale neural network training with limited computational resources.
ALE-Bench: A Benchmark for Long-Horizon Objective-Driven Algorithm Engineering
Jun 10, 2025
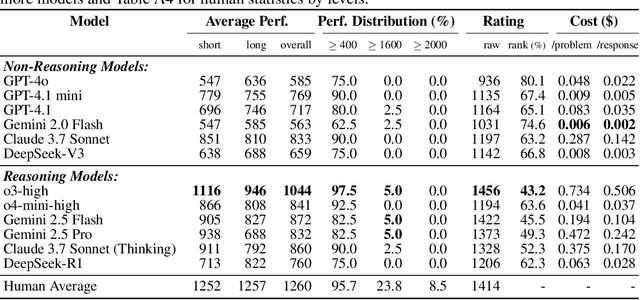


How well do AI systems perform in algorithm engineering for hard optimization problems in domains such as package-delivery routing, crew scheduling, factory production planning, and power-grid balancing? We introduce ALE-Bench, a new benchmark for evaluating AI systems on score-based algorithmic programming contests. Drawing on real tasks from the AtCoder Heuristic Contests, ALE-Bench presents optimization problems that are computationally hard and admit no known exact solution. Unlike short-duration, pass/fail coding benchmarks, ALE-Bench encourages iterative solution refinement over long time horizons. Our software framework supports interactive agent architectures that leverage test-run feedback and visualizations. Our evaluation of frontier LLMs revealed that while they demonstrate high performance on specific problems, a notable gap remains compared to humans in terms of consistency across problems and long-horizon problem-solving capabilities. This highlights the need for this benchmark to foster future AI advancements.
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search
Mar 06, 2025

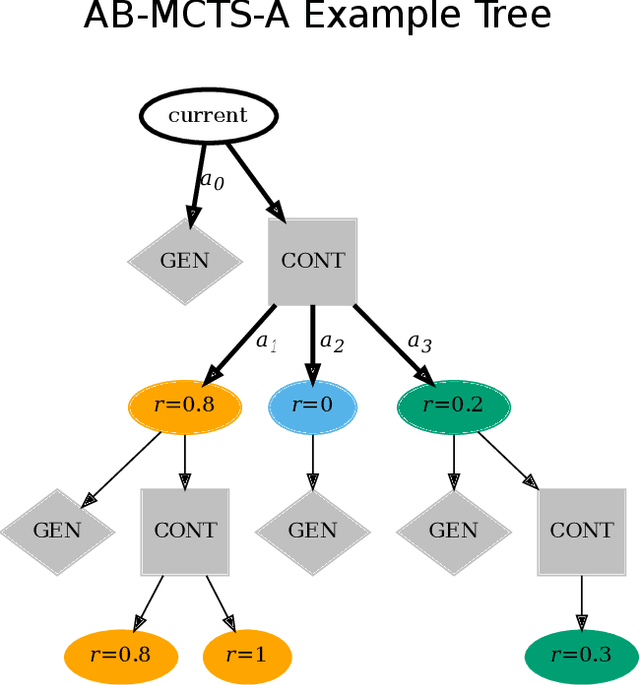

Recent advances demonstrate that increasing inference-time computation can significantly boost the reasoning capabilities of large language models (LLMs). Although repeated sampling (i.e., generating multiple candidate outputs) is a highly effective strategy, it does not leverage external feedback signals for refinement, which are often available in tasks like coding. In this work, we propose $\textit{Adaptive Branching Monte Carlo Tree Search (AB-MCTS)}$, a novel inference-time framework that generalizes repeated sampling with principled multi-turn exploration and exploitation. At each node in the search tree, AB-MCTS dynamically decides whether to "go wider" by expanding new candidate responses or "go deeper" by revisiting existing ones based on external feedback signals. We evaluate our method on complex coding and engineering tasks using frontier models. Empirical results show that AB-MCTS consistently outperforms both repeated sampling and standard MCTS, underscoring the importance of combining the response diversity of LLMs with multi-turn solution refinement for effective inference-time scaling.
Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization
Feb 26, 2025The Mixture of Experts (MoE) architecture reduces the training and inference cost significantly compared to a dense model of equivalent capacity. Upcycling is an approach that initializes and trains an MoE model using a pre-trained dense model. While upcycling leads to initial performance gains, the training progresses slower than when trained from scratch, leading to suboptimal performance in the long term. We propose Drop-Upcycling - a method that effectively addresses this problem. Drop-Upcycling combines two seemingly contradictory approaches: utilizing the knowledge of pre-trained dense models while statistically re-initializing some parts of the weights. This approach strategically promotes expert specialization, significantly enhancing the MoE model's efficiency in knowledge acquisition. Extensive large-scale experiments demonstrate that Drop-Upcycling significantly outperforms previous MoE construction methods in the long term, specifically when training on hundreds of billions of tokens or more. As a result, our MoE model with 5.9B active parameters achieves comparable performance to a 13B dense model in the same model family, while requiring approximately 1/4 of the training FLOPs. All experimental resources, including source code, training data, model checkpoints and logs, are publicly available to promote reproducibility and future research on MoE.
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
Jan 29, 2025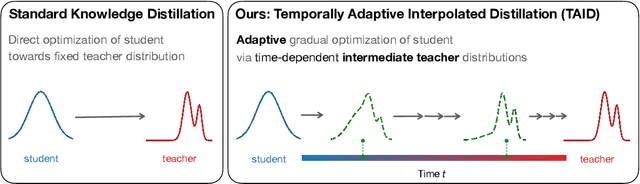
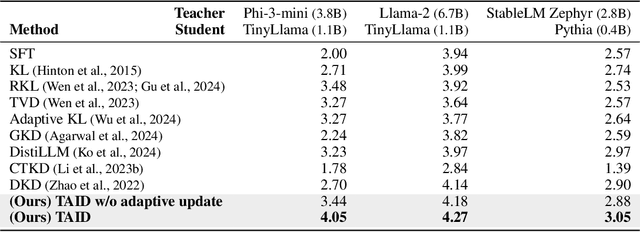
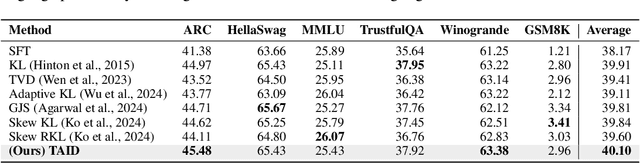
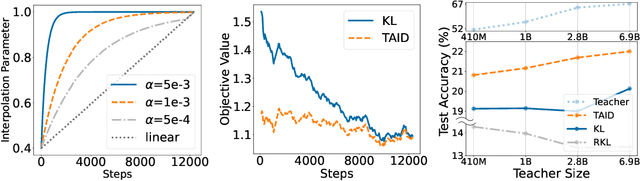
Causal language models have demonstrated remarkable capabilities, but their size poses significant challenges for deployment in resource-constrained environments. Knowledge distillation, a widely-used technique for transferring knowledge from a large teacher model to a small student model, presents a promising approach for model compression. A significant remaining issue lies in the major differences between teacher and student models, namely the substantial capacity gap, mode averaging, and mode collapse, which pose barriers during distillation. To address these issues, we introduce $\textit{Temporally Adaptive Interpolated Distillation (TAID)}$, a novel knowledge distillation approach that dynamically interpolates student and teacher distributions through an adaptive intermediate distribution, gradually shifting from the student's initial distribution towards the teacher's distribution. We provide a theoretical analysis demonstrating TAID's ability to prevent mode collapse and empirically show its effectiveness in addressing the capacity gap while balancing mode averaging and mode collapse. Our comprehensive experiments demonstrate TAID's superior performance across various model sizes and architectures in both instruction tuning and pre-training scenarios. Furthermore, we showcase TAID's practical impact by developing two state-of-the-art compact foundation models: $\texttt{TAID-LLM-1.5B}$ for language tasks and $\texttt{TAID-VLM-2B}$ for vision-language tasks. These results demonstrate TAID's effectiveness in creating high-performing and efficient models, advancing the development of more accessible AI technologies.
Agent Skill Acquisition for Large Language Models via CycleQD
Oct 16, 2024



Training large language models to acquire specific skills remains a challenging endeavor. Conventional training approaches often struggle with data distribution imbalances and inadequacies in objective functions that do not align well with task-specific performance. To address these challenges, we introduce CycleQD, a novel approach that leverages the Quality Diversity framework through a cyclic adaptation of the algorithm, along with a model merging based crossover and an SVD-based mutation. In CycleQD, each task's performance metric is alternated as the quality measure while the others serve as the behavioral characteristics. This cyclic focus on individual tasks allows for concentrated effort on one task at a time, eliminating the need for data ratio tuning and simplifying the design of the objective function. Empirical results from AgentBench indicate that applying CycleQD to LLAMA3-8B-INSTRUCT based models not only enables them to surpass traditional fine-tuning methods in coding, operating systems, and database tasks, but also achieves performance on par with GPT-3.5-TURBO, which potentially contains much more parameters, across these domains. Crucially, this enhanced performance is achieved while retaining robust language capabilities, as evidenced by its performance on widely adopted language benchmark tasks. We highlight the key design choices in CycleQD, detailing how these contribute to its effectiveness. Furthermore, our method is general and can be applied to image segmentation models, highlighting its applicability across different domains.
Evolutionary Optimization of Model Merging Recipes
Mar 19, 2024
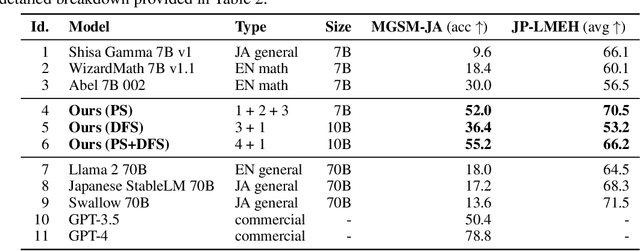

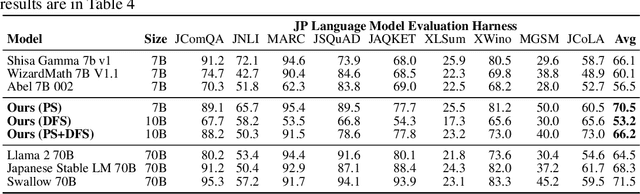
We present a novel application of evolutionary algorithms to automate the creation of powerful foundation models. While model merging has emerged as a promising approach for LLM development due to its cost-effectiveness, it currently relies on human intuition and domain knowledge, limiting its potential. Here, we propose an evolutionary approach that overcomes this limitation by automatically discovering effective combinations of diverse open-source models, harnessing their collective intelligence without requiring extensive additional training data or compute. Our approach operates in both parameter space and data flow space, allowing for optimization beyond just the weights of the individual models. This approach even facilitates cross-domain merging, generating models like a Japanese LLM with Math reasoning capabilities. Surprisingly, our Japanese Math LLM achieved state-of-the-art performance on a variety of established Japanese LLM benchmarks, even surpassing models with significantly more parameters, despite not being explicitly trained for such tasks. Furthermore, a culturally-aware Japanese VLM generated through our approach demonstrates its effectiveness in describing Japanese culture-specific content, outperforming previous Japanese VLMs. This work not only contributes new state-of-the-art models back to the open-source community, but also introduces a new paradigm for automated model composition, paving the way for exploring alternative, efficient approaches to foundation model development.
Team PFDet's Methods for Open Images Challenge 2019
Oct 25, 2019

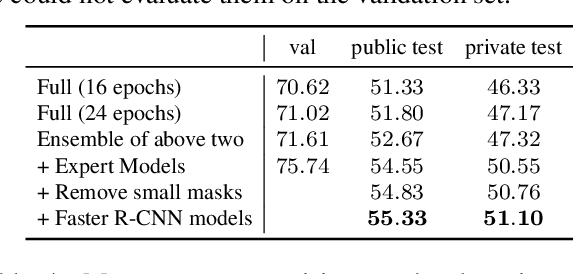

We present the instance segmentation and the object detection method used by team PFDet for Open Images Challenge 2019. We tackle a massive dataset size, huge class imbalance and federated annotations. Using this method, the team PFDet achieved 3rd and 4th place in the instance segmentation and the object detection track, respectively.