 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAPPI: Interactive Optimization with LLM-Assisted Preference-Based Problem Instantiation
Dec 16, 2025Many real-world tasks, such as trip planning or meal planning, can be formulated as combinatorial optimization problems. However, using optimization solvers is difficult for end users because it requires problem instantiation: defining candidate items, assigning preference scores, and specifying constraints. We introduce LAPPI (LLM-Assisted Preference-based Problem Instantiation), an interactive approach that uses large language models (LLMs) to support users in this instantiation process. Through natural language conversations, the system helps users transform vague preferences into well-defined optimization problems. These instantiated problems are then passed to existing optimization solvers to generate solutions. In a user study on trip planning, our method successfully captured user preferences and generated feasible plans that outperformed both conventional and prompt-engineering approaches. We further demonstrate LAPPI's versatility by adapting it to an additional use case.
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search
Mar 06, 2025

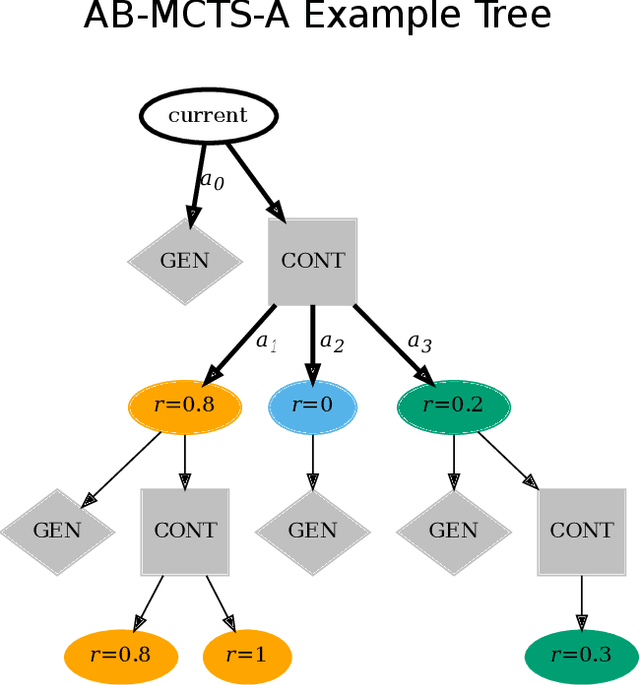

Recent advances demonstrate that increasing inference-time computation can significantly boost the reasoning capabilities of large language models (LLMs). Although repeated sampling (i.e., generating multiple candidate outputs) is a highly effective strategy, it does not leverage external feedback signals for refinement, which are often available in tasks like coding. In this work, we propose $\textit{Adaptive Branching Monte Carlo Tree Search (AB-MCTS)}$, a novel inference-time framework that generalizes repeated sampling with principled multi-turn exploration and exploitation. At each node in the search tree, AB-MCTS dynamically decides whether to "go wider" by expanding new candidate responses or "go deeper" by revisiting existing ones based on external feedback signals. We evaluate our method on complex coding and engineering tasks using frontier models. Empirical results show that AB-MCTS consistently outperforms both repeated sampling and standard MCTS, underscoring the importance of combining the response diversity of LLMs with multi-turn solution refinement for effective inference-time scaling.
Agent Skill Acquisition for Large Language Models via CycleQD
Oct 16, 2024



Training large language models to acquire specific skills remains a challenging endeavor. Conventional training approaches often struggle with data distribution imbalances and inadequacies in objective functions that do not align well with task-specific performance. To address these challenges, we introduce CycleQD, a novel approach that leverages the Quality Diversity framework through a cyclic adaptation of the algorithm, along with a model merging based crossover and an SVD-based mutation. In CycleQD, each task's performance metric is alternated as the quality measure while the others serve as the behavioral characteristics. This cyclic focus on individual tasks allows for concentrated effort on one task at a time, eliminating the need for data ratio tuning and simplifying the design of the objective function. Empirical results from AgentBench indicate that applying CycleQD to LLAMA3-8B-INSTRUCT based models not only enables them to surpass traditional fine-tuning methods in coding, operating systems, and database tasks, but also achieves performance on par with GPT-3.5-TURBO, which potentially contains much more parameters, across these domains. Crucially, this enhanced performance is achieved while retaining robust language capabilities, as evidenced by its performance on widely adopted language benchmark tasks. We highlight the key design choices in CycleQD, detailing how these contribute to its effectiveness. Furthermore, our method is general and can be applied to image segmentation models, highlighting its applicability across different domains.
Swarm Body: Embodied Swarm Robots
Mar 01, 2024
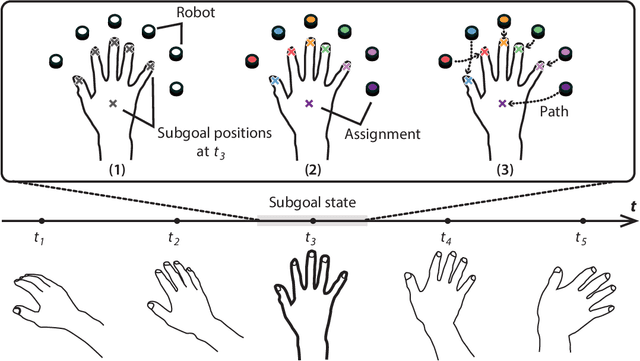

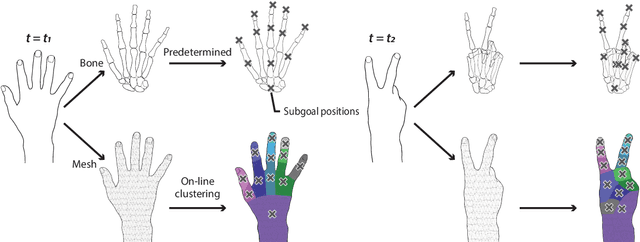
The human brain's plasticity allows for the integration of artificial body parts into the human body. Leveraging this, embodied systems realize intuitive interactions with the environment. We introduce a novel concept: embodied swarm robots. Swarm robots constitute a collective of robots working in harmony to achieve a common objective, in our case, serving as functional body parts. Embodied swarm robots can dynamically alter their shape, density, and the correspondences between body parts and individual robots. We contribute an investigation of the influence on embodiment of swarm robot-specific factors derived from these characteristics, focusing on a hand. Our paper is the first to examine these factors through virtual reality (VR) and real-world robot studies to provide essential design considerations and applications of embodied swarm robots. Through quantitative and qualitative analysis, we identified a system configuration to achieve the embodiment of swarm robots.
Multi-Agent Behavior Retrieval
Dec 04, 2023This paper aims to enable multi-agent systems to effectively utilize past memories to adapt to novel collaborative tasks in a data-efficient fashion. We propose the Multi-Agent Coordination Skill Database, a repository for storing a collection of coordinated behaviors associated with the key vector distinctive to them. Our Transformer-based skill encoder effectively captures spatio-temporal interactions that contribute to coordination and provide a skill representation unique to each coordinated behavior. By leveraging a small number of demonstrations of the target task, the database allows us to train the policy using a dataset augmented with the retrieved demonstrations. Experimental evaluations clearly demonstrate that our method achieves a significantly higher success rate in push manipulation tasks compared to baseline methods like few-shot imitation learning. Furthermore, we validate the effectiveness of our retrieve-and-learn framework in a real environment using a team of wheeled robots.
GenDOM: Generalizable One-shot Deformable Object Manipulation with Parameter-Aware Policy
Sep 19, 2023Due to the inherent uncertainty in their deformability during motion, previous methods in deformable object manipulation, such as rope and cloth, often required hundreds of real-world demonstrations to train a manipulation policy for each object, which hinders their applications in our ever-changing world. To address this issue, we introduce GenDOM, a framework that allows the manipulation policy to handle different deformable objects with only a single real-world demonstration. To achieve this, we augment the policy by conditioning it on deformable object parameters and training it with a diverse range of simulated deformable objects so that the policy can adjust actions based on different object parameters. At the time of inference, given a new object, GenDOM can estimate the deformable object parameters with only a single real-world demonstration by minimizing the disparity between the grid density of point clouds of real-world demonstrations and simulations in a differentiable physics simulator. Empirical validations on both simulated and real-world object manipulation setups clearly show that our method can manipulate different objects with a single demonstration and significantly outperforms the baseline in both environments (a 62% improvement for in-domain ropes and a 15% improvement for out-of-distribution ropes in simulation, as well as a 26% improvement for ropes and a 50% improvement for cloths in the real world), demonstrating the effectiveness of our approach in one-shot deformable object manipulation.
GenORM: Generalizable One-shot Rope Manipulation with Parameter-Aware Policy
Jun 20, 2023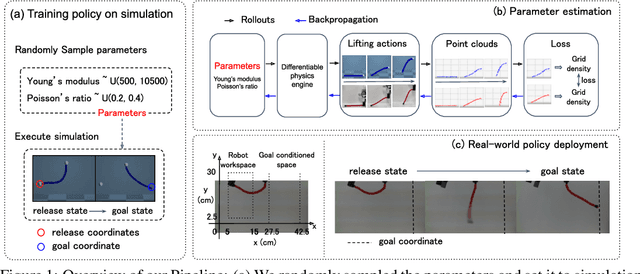
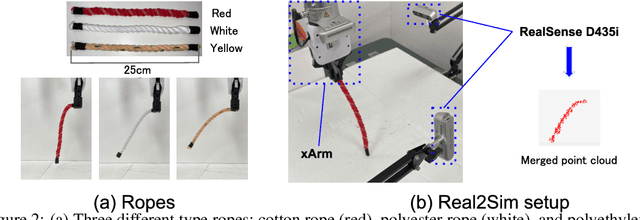
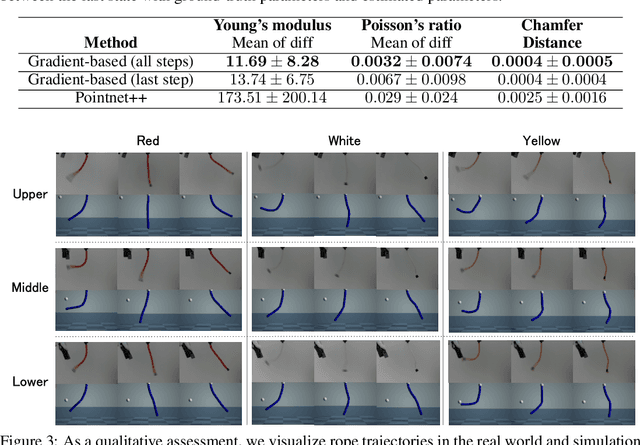
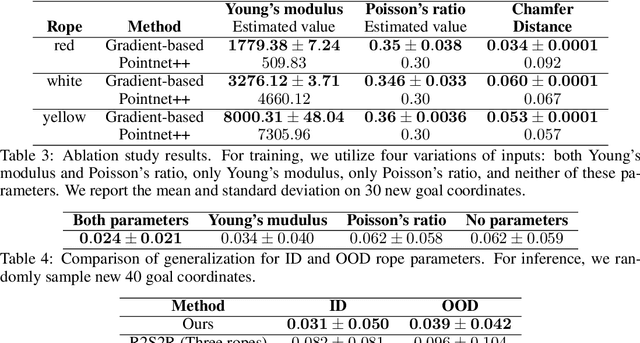
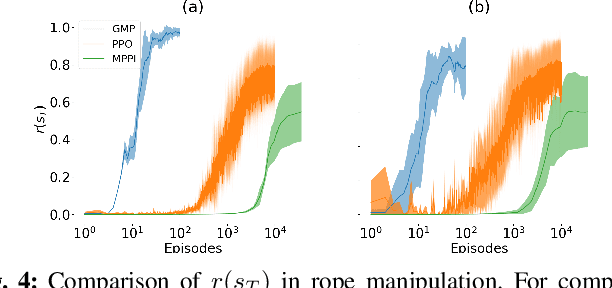
Due to the inherent uncertainty in their deformability during motion, previous methods in rope manipulation often require hundreds of real-world demonstrations to train a manipulation policy for each rope, even for simple tasks such as rope goal reaching, which hinder their applications in our ever-changing world. To address this issue, we introduce GenORM, a framework that allows the manipulation policy to handle different deformable ropes with a single real-world demonstration. To achieve this, we augment the policy by conditioning it on deformable rope parameters and training it with a diverse range of simulated deformable ropes so that the policy can adjust actions based on different rope parameters. At the time of inference, given a new rope, GenORM estimates the deformable rope parameters by minimizing the disparity between the grid density of point clouds of real-world demonstrations and simulations. With the help of a differentiable physics simulator, we require only a single real-world demonstration. Empirical validations on both simulated and real-world rope manipulation setups clearly show that our method can manipulate different ropes with a single demonstration and significantly outperforms the baseline in both environments (62% improvement in in-domain ropes, and 15% improvement in out-of-distribution ropes in simulation, 26% improvement in real-world), demonstrating the effectiveness of our approach in one-shot rope manipulation.
Collective Intelligence for Object Manipulation with Mobile Robots
Nov 28, 2022
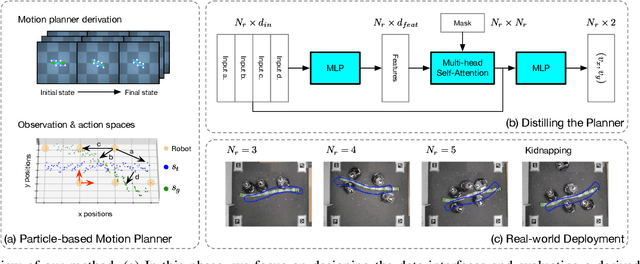
While natural systems often present collective intelligence that allows them to self-organize and adapt to changes, the equivalent is missing in most artificial systems. We explore the possibility of such a system in the context of cooperative object manipulation using mobile robots. Although conventional works demonstrate potential solutions for the problem in restricted settings, they have computational and learning difficulties. More importantly, these systems do not possess the ability to adapt when facing environmental changes. In this work, we show that by distilling a planner derived from a gradient-based soft-body physics simulator into an attention-based neural network, our multi-robot manipulation system can achieve better performance than baselines. In addition, our system also generalizes to unseen configurations during training and is able to adapt toward task completions when external turbulence and environmental changes are applied.