 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactile Memory with Soft Robot: Robust Object Insertion via Masked Encoding and Soft Wrist
Jan 27, 2026Tactile memory, the ability to store and retrieve touch-based experience, is critical for contact-rich tasks such as key insertion under uncertainty. To replicate this capability, we introduce Tactile Memory with Soft Robot (TaMeSo-bot), a system that integrates a soft wrist with tactile retrieval-based control to enable safe and robust manipulation. The soft wrist allows safe contact exploration during data collection, while tactile memory reuses past demonstrations via retrieval for flexible adaptation to unseen scenarios. The core of this system is the Masked Tactile Trajectory Transformer (MAT$^\text{3}$), which jointly models spatiotemporal interactions between robot actions, distributed tactile feedback, force-torque measurements, and proprioceptive signals. Through masked-token prediction, MAT$^\text{3}$ learns rich spatiotemporal representations by inferring missing sensory information from context, autonomously extracting task-relevant features without explicit subtask segmentation. We validate our approach on peg-in-hole tasks with diverse pegs and conditions in real-robot experiments. Our extensive evaluation demonstrates that MAT$^\text{3}$ achieves higher success rates than the baselines over all conditions and shows remarkable capability to adapt to unseen pegs and conditions.
Robot Swarm Control Based on Smoothed Particle Hydrodynamics for Obstacle-Unaware Navigation
Apr 25, 2024Robot swarms hold immense potential for performing complex tasks far beyond the capabilities of individual robots. However, the challenge in unleashing this potential is the robots' limited sensory capabilities, which hinder their ability to detect and adapt to unknown obstacles in real-time. To overcome this limitation, we introduce a novel robot swarm control method with an indirect obstacle detector using a smoothed particle hydrodynamics (SPH) model. The indirect obstacle detector can predict the collision with an obstacle and its collision point solely from the robot's velocity information. This approach enables the swarm to effectively and accurately navigate environments without the need for explicit obstacle detection, significantly enhancing their operational robustness and efficiency. Our method's superiority is quantitatively validated through a comparative analysis, showcasing its significant navigation and pattern formation improvements under obstacle-unaware conditions.
Swarm Body: Embodied Swarm Robots
Mar 01, 2024
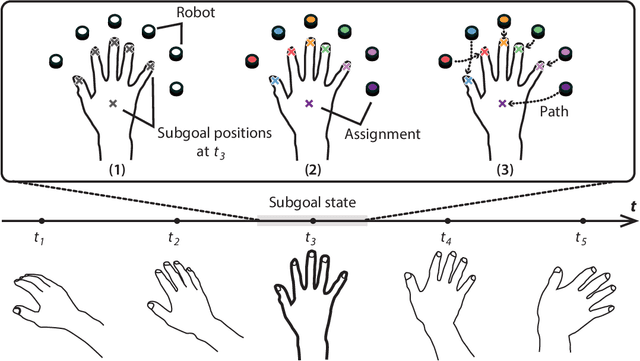

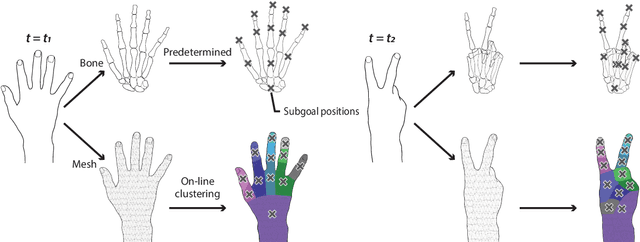
The human brain's plasticity allows for the integration of artificial body parts into the human body. Leveraging this, embodied systems realize intuitive interactions with the environment. We introduce a novel concept: embodied swarm robots. Swarm robots constitute a collective of robots working in harmony to achieve a common objective, in our case, serving as functional body parts. Embodied swarm robots can dynamically alter their shape, density, and the correspondences between body parts and individual robots. We contribute an investigation of the influence on embodiment of swarm robot-specific factors derived from these characteristics, focusing on a hand. Our paper is the first to examine these factors through virtual reality (VR) and real-world robot studies to provide essential design considerations and applications of embodied swarm robots. Through quantitative and qualitative analysis, we identified a system configuration to achieve the embodiment of swarm robots.
Multi-Agent Behavior Retrieval
Dec 04, 2023This paper aims to enable multi-agent systems to effectively utilize past memories to adapt to novel collaborative tasks in a data-efficient fashion. We propose the Multi-Agent Coordination Skill Database, a repository for storing a collection of coordinated behaviors associated with the key vector distinctive to them. Our Transformer-based skill encoder effectively captures spatio-temporal interactions that contribute to coordination and provide a skill representation unique to each coordinated behavior. By leveraging a small number of demonstrations of the target task, the database allows us to train the policy using a dataset augmented with the retrieved demonstrations. Experimental evaluations clearly demonstrate that our method achieves a significantly higher success rate in push manipulation tasks compared to baseline methods like few-shot imitation learning. Furthermore, we validate the effectiveness of our retrieve-and-learn framework in a real environment using a team of wheeled robots.
Counterfactual Fairness Filter for Fair-Delay Multi-Robot Navigation
May 19, 2023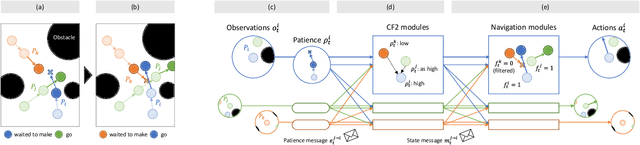
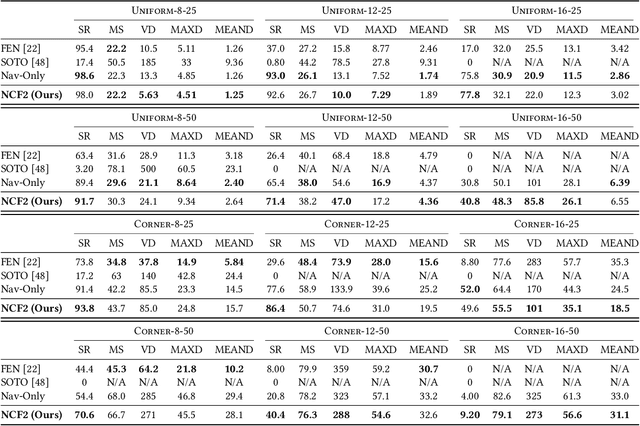
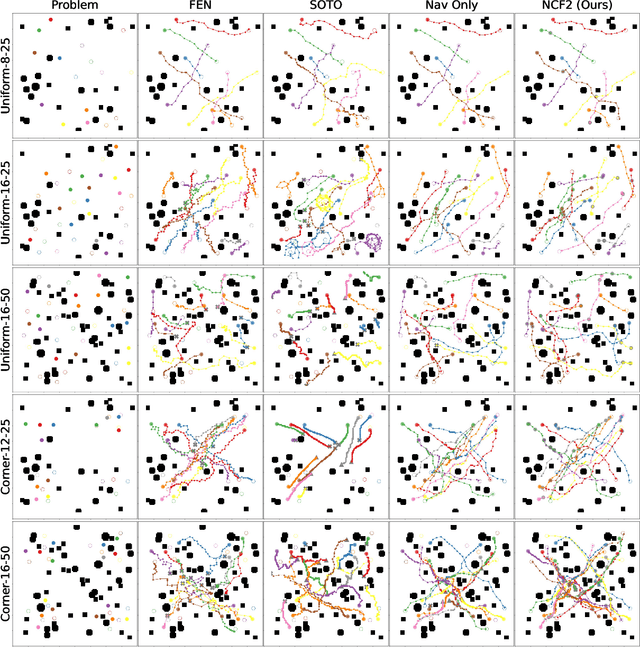
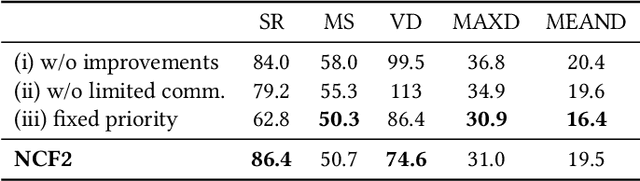
Multi-robot navigation is the task of finding trajectories for a team of robotic agents to reach their destinations as quickly as possible without collisions. In this work, we introduce a new problem: fair-delay multi-robot navigation, which aims not only to enable such efficient, safe travels but also to equalize the travel delays among agents in terms of actual trajectories as compared to the best possible trajectories. The learning of a navigation policy to achieve this objective requires resolving a nontrivial credit assignment problem with robotic agents having continuous action spaces. Hence, we developed a new algorithm called Navigation with Counterfactual Fairness Filter (NCF2). With NCF2, each agent performs counterfactual inference on whether it can advance toward its goal or should stay still to let other agents go. Doing so allows us to effectively address the aforementioned credit assignment problem and improve fairness regarding travel delays while maintaining high efficiency and safety. Our extensive experimental results in several challenging multi-robot navigation environments demonstrate the greater effectiveness of NCF2 as compared to state-of-the-art fairness-aware multi-agent reinforcement learning methods. Our demo videos and code are available on the project webpage: https://omron-sinicx.github.io/ncf2/
When to Replan? An Adaptive Replanning Strategy for Autonomous Navigation using Deep Reinforcement Learning
Apr 24, 2023The hierarchy of global and local planners is one of the most commonly utilized system designs in robot autonomous navigation. While the global planner generates a reference path from the current to goal locations based on the pre-built static map, the local planner produces a collision-free, kinodynamic trajectory to follow the reference path while avoiding perceived obstacles. The reference path should be replanned regularly to accommodate new obstacles that were absent in the pre-built map, but when to execute replanning remains an open question. In this work, we conduct an extensive simulation experiment to compare various replanning strategies and confirm that effective strategies highly depend on the environment as well as on the global and local planners. We then propose a new adaptive replanning strategy based on deep reinforcement learning, where an agent learns from experiences to decide appropriate replanning timings in the given environment and planning setups. Our experimental results demonstrate that the proposed replanning agent can achieve performance on par or even better than current best-performing strategies across multiple situations in terms of navigation robustness and efficiency.
TransPoser: Transformer as an Optimizer for Joint Object Shape and Pose Estimation
Mar 23, 2023



We propose a novel method for joint estimation of shape and pose of rigid objects from their sequentially observed RGB-D images. In sharp contrast to past approaches that rely on complex non-linear optimization, we propose to formulate it as a neural optimization that learns to efficiently estimate the shape and pose. We introduce Deep Directional Distance Function (DeepDDF), a neural network that directly outputs the depth image of an object given the camera viewpoint and viewing direction, for efficient error computation in 2D image space. We formulate the joint estimation itself as a Transformer which we refer to as TransPoser. We fully leverage the tokenization and multi-head attention to sequentially process the growing set of observations and to efficiently update the shape and pose with a learned momentum, respectively. Experimental results on synthetic and real data show that DeepDDF achieves high accuracy as a category-level object shape representation and TransPoser achieves state-of-the-art accuracy efficiently for joint shape and pose estimation.
InCrowdFormer: On-Ground Pedestrian World Model From Egocentric Views
Mar 16, 2023We introduce an on-ground Pedestrian World Model, a computational model that can predict how pedestrians move around an observer in the crowd on the ground plane, but from just the egocentric-views of the observer. Our model, InCrowdFormer, fully leverages the Transformer architecture by modeling pedestrian interaction and egocentric to top-down view transformation with attention, and autoregressively predicts on-ground positions of a variable number of people with an encoder-decoder architecture. We encode the uncertainties arising from unknown pedestrian heights with latent codes to predict the posterior distributions of pedestrian positions. We validate the effectiveness of InCrowdFormer on a novel prediction benchmark of real movements. The results show that InCrowdFormer accurately predicts the future coordination of pedestrians. To the best of our knowledge, InCrowdFormer is the first-of-its-kind pedestrian world model which we believe will benefit a wide range of egocentric-view applications including crowd navigation, tracking, and synthesis.
ViewBirdiformer: Learning to recover ground-plane crowd trajectories and ego-motion from a single ego-centric view
Oct 12, 2022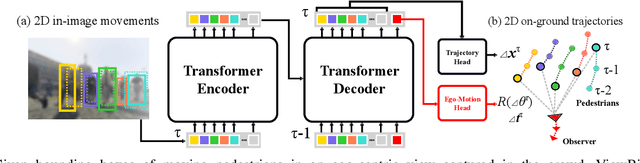
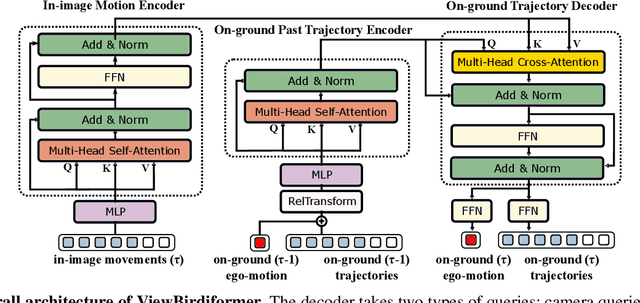
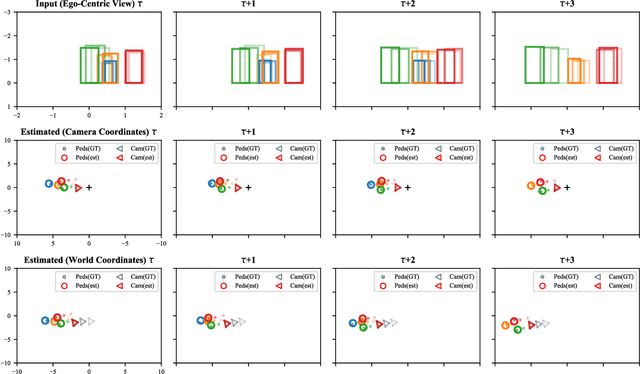
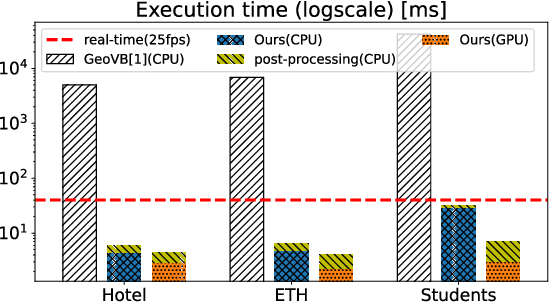
We introduce a novel learning-based method for view birdification, the task of recovering ground-plane trajectories of pedestrians of a crowd and their observer in the same crowd just from the observed ego-centric video. View birdification becomes essential for mobile robot navigation and localization in dense crowds where the static background is hard to see and reliably track. It is challenging mainly for two reasons; i) absolute trajectories of pedestrians are entangled with the movement of the observer which needs to be decoupled from their observed relative movements in the ego-centric video, and ii) a crowd motion model describing the pedestrian movement interactions is specific to the scene yet unknown a priori. For this, we introduce a Transformer-based network referred to as ViewBirdiformer which implicitly models the crowd motion through self-attention and decomposes relative 2D movement observations onto the ground-plane trajectories of the crowd and the camera through cross-attention between views. Most important, ViewBirdiformer achieves view birdification in a single forward pass which opens the door to accurate real-time, always-on situational awareness. Extensive experimental results demonstrate that ViewBirdiformer achieves accuracy similar to or better than state-of-the-art with three orders of magnitude reduction in execution time.
CTRMs: Learning to Construct Cooperative Timed Roadmaps for Multi-agent Path Planning in Continuous Spaces
Jan 24, 2022
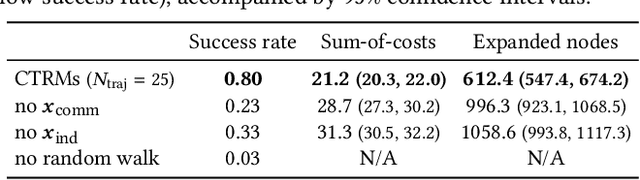
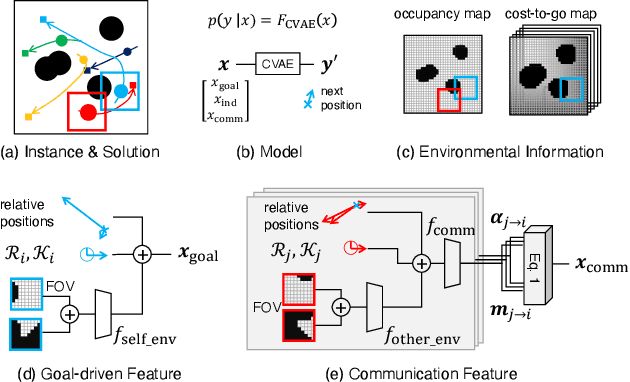
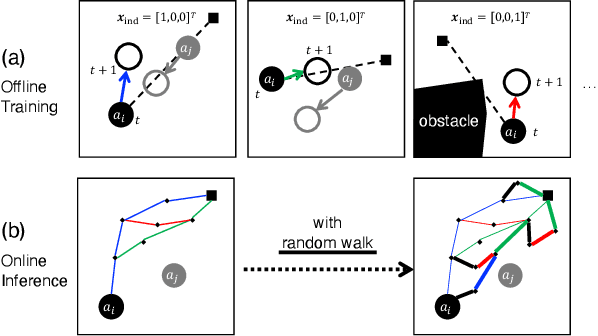
Multi-agent path planning (MAPP) in continuous spaces is a challenging problem with significant practical importance. One promising approach is to first construct graphs approximating the spaces, called roadmaps, and then apply multi-agent pathfinding (MAPF) algorithms to derive a set of conflict-free paths. While conventional studies have utilized roadmap construction methods developed for single-agent planning, it remains largely unexplored how we can construct roadmaps that work effectively for multiple agents. To this end, we propose a novel concept of roadmaps called cooperative timed roadmaps (CTRMs). CTRMs enable each agent to focus on its important locations around potential solution paths in a way that considers the behavior of other agents to avoid inter-agent collisions (i.e., "cooperative"), while being augmented in the time direction to make it easy to derive a "timed" solution path. To construct CTRMs, we developed a machine-learning approach that learns a generative model from a collection of relevant problem instances and plausible solutions and then uses the learned model to sample the vertices of CTRMs for new, previously unseen problem instances. Our empirical evaluation revealed that the use of CTRMs significantly reduced the planning effort with acceptable overheads while maintaining a success rate and solution quality comparable to conventional roadmap construction approaches.