 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetailed Geometry and Appearance from Opportunistic Motion
Mar 27, 2026Reconstructing 3D geometry and appearance from a sparse set of fixed cameras is a foundational task with broad applications, yet it remains fundamentally constrained by the limited viewpoints. We show that this bound can be broken by exploiting opportunistic object motion: as a person manipulates an object~(e.g., moving a chair or lifting a mug), the static cameras effectively ``orbit'' the object in its local coordinate frame, providing additional virtual viewpoints. Harnessing this object motion, however, poses two challenges: the tight coupling of object pose and geometry estimation and the complex appearance variations of a moving object under static illumination. We address these by formulating a joint pose and shape optimization using 2D Gaussian splatting with alternating minimization of 6DoF trajectories and primitive parameters, and by introducing a novel appearance model that factorizes diffuse and specular components with reflected directional probing within the spherical harmonics space. Extensive experiments on synthetic and real-world datasets with extremely sparse viewpoints demonstrate that our method recovers significantly more accurate geometry and appearance than state-of-the-art baselines.
How good was my shot? Quantifying Player Skill Level in Table Tennis
Mar 26, 2026Gauging an individual's skill level is crucial, as it inherently shapes their behavior. Quantifying skill, however, is challenging because it is latent to the observed actions. To explore skill understanding in human behavior, we focus on dyadic sports -- specifically table tennis -- where skill manifests not just in complex movements, but in the subtle nuances of execution conditioned on game context. Our key idea is to learn a generative model of each player's tactical racket strokes and jointly embed them in a common latent space that encodes individual characteristics, including those pertaining to skill levels. By training these player models on a large-scale dataset of 3D-reconstructed professional matches and conditioning them on comprehensive game context -- including player positioning and opponent behaviors -- the models capture individual tactical identities within their latent space. We probe this learned player space and find that it reflects distinct play styles and attributes that collectively represent skill. By training a simple relative ranking network on these embeddings, we demonstrate that both relative and absolute skill predictions can be achieved. These results demonstrate that the learned player space effectively quantifies skill levels, providing a foundation for automated skill assessment in complex, interactive behaviors.
Under One Sun: Multi-Object Generative Perception of Materials and Illumination
Mar 19, 2026We introduce Multi-Object Generative Perception (MultiGP), a generative inverse rendering method for stochastic sampling of all radiometric constituents -- reflectance, texture, and illumination -- underlying object appearance from a single image. Our key idea to solve this inherently ambiguous radiometric disentanglement is to leverage the fact that while their texture and reflectance may differ, objects in the same scene are all lit by the same illumination. MultiGP exploits this consensus to produce samples of reflectance, texture, and illumination from a single image of known shapes based on four key technical contributions: a cascaded end-to-end architecture that combines image-space and angular-space disentanglement; Coordinated Guidance for diffusion convergence to a single consistent illumination estimate; Axial Attention applied to facilitate ``cross-talk'' between objects of different reflectance; and a Texture Extraction ControlNet to preserve high-frequency texture details while ensuring decoupling from estimated lighting. Experimental results demonstrate that MultiGP effectively leverages the complementary spatial and frequency characteristics of multiple object appearances to recover individual texture and reflectance as well as the common illumination.
M-PhyGs: Multi-Material Object Dynamics from Video
Dec 18, 2025Knowledge of the physical material properties governing the dynamics of a real-world object becomes necessary to accurately anticipate its response to unseen interactions. Existing methods for estimating such physical material parameters from visual data assume homogeneous single-material objects, pre-learned dynamics, or simplistic topologies. Real-world objects, however, are often complex in material composition and geometry lying outside the realm of these assumptions. In this paper, we particularly focus on flowers as a representative common object. We introduce Multi-material Physical Gaussians (M-PhyGs) to estimate the material composition and parameters of such multi-material complex natural objects from video. From a short video captured in a natural setting, M-PhyGs jointly segments the object into similar materials and recovers their continuum mechanical parameters while accounting for gravity. M-PhyGs achieves this efficiently with newly introduced cascaded 3D and 2D losses, and by leveraging temporal mini-batching. We introduce a dataset, Phlowers, of people interacting with flowers as a novel platform to evaluate the accuracy of this challenging task of multi-material physical parameter estimation. Experimental results on Phlowers dataset demonstrate the accuracy and effectiveness of M-PhyGs and its components.
Single-Shot Shape and Reflectance with Spatial Polarization Multiplexing
Apr 17, 2025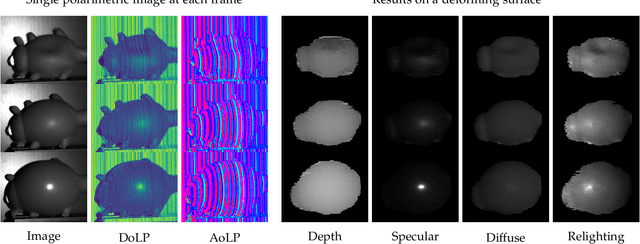
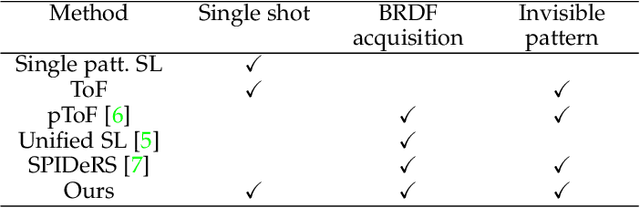

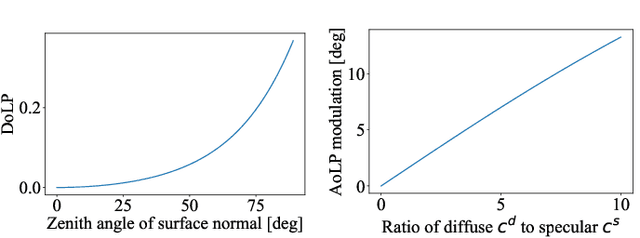
We propose spatial polarization multiplexing (SPM) for reconstructing object shape and reflectance from a single polarimetric image and demonstrate its application to dynamic surface recovery. Although single-pattern structured light enables single-shot shape reconstruction, the reflectance is challenging to recover due to the lack of angular sampling of incident light and the entanglement of the projected pattern and the surface color texture. We design a spatially multiplexed pattern of polarization that can be robustly and uniquely decoded for shape reconstruction by quantizing the AoLP values. At the same time, our spatial-multiplexing enables single-shot ellipsometry of linear polarization by projecting differently polarized light within a local region, which separates the specular and diffuse reflections for BRDF estimation. We achieve this spatial polarization multiplexing with a constrained de Bruijn sequence. Unlike single-pattern structured light with intensity and color, our polarization pattern is invisible to the naked eye and retains the natural surface appearance which is essential for accurate appearance modeling and also interaction with people. We experimentally validate our method on real data. The results show that our method can recover the shape, the Mueller matrix, and the BRDF from a single-shot polarimetric image. We also demonstrate the application of our method to dynamic surfaces.
SHeaP: Self-Supervised Head Geometry Predictor Learned via 2D Gaussians
Apr 16, 2025Accurate, real-time 3D reconstruction of human heads from monocular images and videos underlies numerous visual applications. As 3D ground truth data is hard to come by at scale, previous methods have sought to learn from abundant 2D videos in a self-supervised manner. Typically, this involves the use of differentiable mesh rendering, which is effective but faces limitations. To improve on this, we propose SHeaP (Self-supervised Head Geometry Predictor Learned via 2D Gaussians). Given a source image, we predict a 3DMM mesh and a set of Gaussians that are rigged to this mesh. We then reanimate this rigged head avatar to match a target frame, and backpropagate photometric losses to both the 3DMM and Gaussian prediction networks. We find that using Gaussians for rendering substantially improves the effectiveness of this self-supervised approach. Training solely on 2D data, our method surpasses existing self-supervised approaches in geometric evaluations on the NoW benchmark for neutral faces and a new benchmark for non-neutral expressions. Our method also produces highly expressive meshes, outperforming state-of-the-art in emotion classification.
Spatiotemporal Multi-Camera Calibration using Freely Moving People
Feb 18, 2025



We propose a novel method for spatiotemporal multi-camera calibration using freely moving people in multiview videos. Since calibrating multiple cameras and finding matches across their views are inherently interdependent, performing both in a unified framework poses a significant challenge. We address these issues as a single registration problem of matching two sets of 3D points, leveraging human motion in dynamic multi-person scenes. To this end, we utilize 3D human poses obtained from an off-the-shelf monocular 3D human pose estimator and transform them into 3D points on a unit sphere, to solve the rotation, time offset, and the association alternatingly. We employ a probabilistic approach that can jointly solve both problems of aligning spatiotemporal data and establishing correspondences through soft assignment between two views. The translation is determined by applying coplanarity constraints. The pairwise registration results are integrated into a multiview setup, and then a nonlinear optimization method is used to improve the accuracy of the camera poses, temporal offsets, and multi-person associations. Extensive experiments on synthetic and real data demonstrate the effectiveness and flexibility of the proposed method as a practical marker-free calibration tool.
RatBodyFormer: Rodent Body Surface from Keypoints
Dec 12, 2024


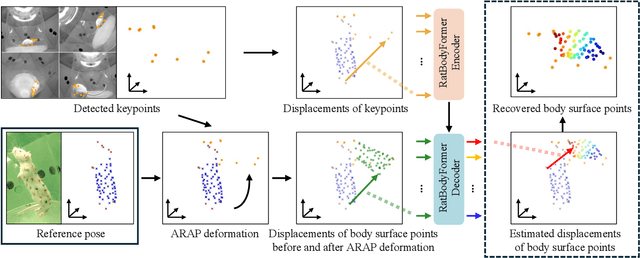
Rat behavior modeling goes to the heart of many scientific studies, yet the textureless body surface evades automatic analysis as it literally has no keypoints that detectors can find. The movement of the body surface, however, is a rich source of information for deciphering the rat behavior. We introduce two key contributions to automatically recover densely 3D sampled rat body surface points, passively. The first is RatDome, a novel multi-camera system for rat behavior capture, and a large-scale dataset captured with it that consists of pairs of 3D keypoints and 3D body surface points. The second is RatBodyFormer, a novel network to transform detected keypoints to 3D body surface points. RatBodyFormer is agnostic to the exact locations of the 3D body surface points in the training data and is trained with masked-learning. We experimentally validate our framework with a number of real-world experiments. Our results collectively serve as a novel foundation for automated rat behavior analysis and will likely have far-reaching implications for biomedical and neuroscientific research.
MAtCha Gaussians: Atlas of Charts for High-Quality Geometry and Photorealism From Sparse Views
Dec 09, 2024



We present a novel appearance model that simultaneously realizes explicit high-quality 3D surface mesh recovery and photorealistic novel view synthesis from sparse view samples. Our key idea is to model the underlying scene geometry Mesh as an Atlas of Charts which we render with 2D Gaussian surfels (MAtCha Gaussians). MAtCha distills high-frequency scene surface details from an off-the-shelf monocular depth estimator and refines it through Gaussian surfel rendering. The Gaussian surfels are attached to the charts on the fly, satisfying photorealism of neural volumetric rendering and crisp geometry of a mesh model, i.e., two seemingly contradicting goals in a single model. At the core of MAtCha lies a novel neural deformation model and a structure loss that preserve the fine surface details distilled from learned monocular depths while addressing their fundamental scale ambiguities. Results of extensive experimental validation demonstrate MAtCha's state-of-the-art quality of surface reconstruction and photorealism on-par with top contenders but with dramatic reduction in the number of input views and computational time. We believe MAtCha will serve as a foundational tool for any visual application in vision, graphics, and robotics that require explicit geometry in addition to photorealism. Our project page is the following: https://anttwo.github.io/matcha/
HeatFormer: A Neural Optimizer for Multiview Human Mesh Recovery
Dec 05, 2024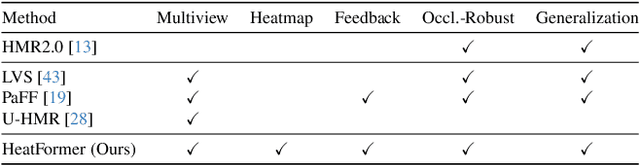
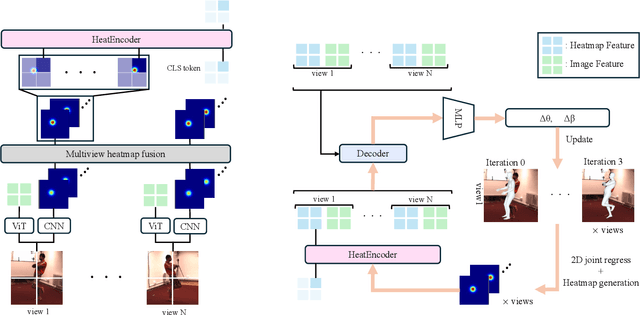
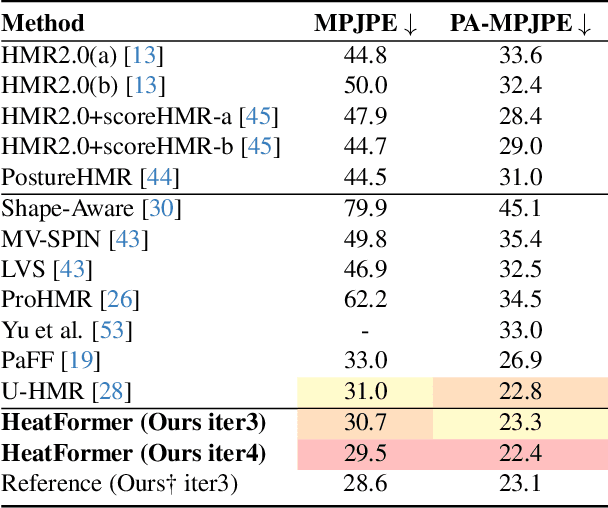
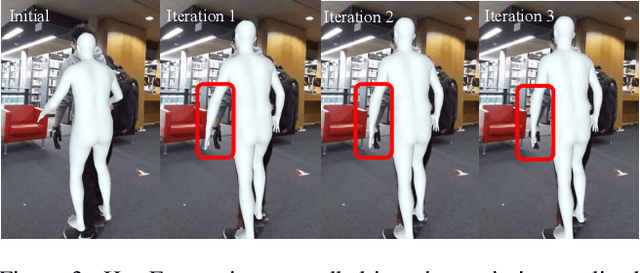
We introduce a novel method for human shape and pose recovery that can fully leverage multiple static views. We target fixed-multiview people monitoring, including elderly care and safety monitoring, in which calibrated cameras can be installed at the corners of a room or an open space but whose configuration may vary depending on the environment. Our key idea is to formulate it as neural optimization. We achieve this with HeatFormer, a neural optimizer that iteratively refines the SMPL parameters given multiview images, which is fundamentally agonistic to the configuration of views. HeatFormer realizes this SMPL parameter estimation as heat map generation and alignment with a novel transformer encoder and decoder. We demonstrate the effectiveness of HeatFormer including its accuracy, robustness to occlusion, and generalizability through an extensive set of experiments. We believe HeatFormer can serve a key role in passive human behavior modeling.