 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCTG Bench: LLM Controlled Text Generation Benchmark
Jan 27, 2025



The rise of large language models (LLMs) has led to more diverse and higher-quality machine-generated text. However, their high expressive power makes it difficult to control outputs based on specific business instructions. In response, benchmarks focusing on the controllability of LLMs have been developed, but several issues remain: (1) They primarily cover major languages like English and Chinese, neglecting low-resource languages like Japanese; (2) Current benchmarks employ task-specific evaluation metrics, lacking a unified framework for selecting models based on controllability across different use cases. To address these challenges, this research introduces LCTG Bench, the first Japanese benchmark for evaluating the controllability of LLMs. LCTG Bench provides a unified framework for assessing control performance, enabling users to select the most suitable model for their use cases based on controllability. By evaluating nine diverse Japanese-specific and multilingual LLMs like GPT-4, we highlight the current state and challenges of controllability in Japanese LLMs and reveal the significant gap between multilingual models and Japanese-specific models.
PBDyG: Position Based Dynamic Gaussians for Motion-Aware Clothed Human Avatars
Dec 05, 2024



This paper introduces a novel clothed human model that can be learned from multiview RGB videos, with a particular emphasis on recovering physically accurate body and cloth movements. Our method, Position Based Dynamic Gaussians (PBDyG), realizes ``movement-dependent'' cloth deformation via physical simulation, rather than merely relying on ``pose-dependent'' rigid transformations. We model the clothed human holistically but with two distinct physical entities in contact: clothing modeled as 3D Gaussians, which are attached to a skinned SMPL body that follows the movement of the person in the input videos. The articulation of the SMPL body also drives physically-based simulation of the clothes' Gaussians to transform the avatar to novel poses. In order to run position based dynamics simulation, physical properties including mass and material stiffness are estimated from the RGB videos through Dynamic 3D Gaussian Splatting. Experiments demonstrate that our method not only accurately reproduces appearance but also enables the reconstruction of avatars wearing highly deformable garments, such as skirts or coats, which have been challenging to reconstruct using existing methods.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
A Single Linear Layer Yields Task-Adapted Low-Rank Matrices
Mar 22, 2024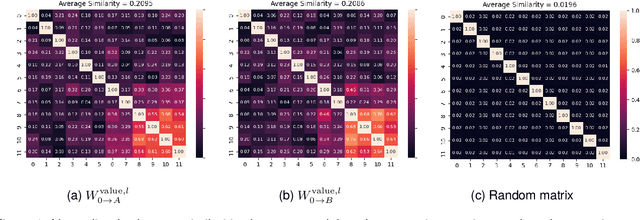

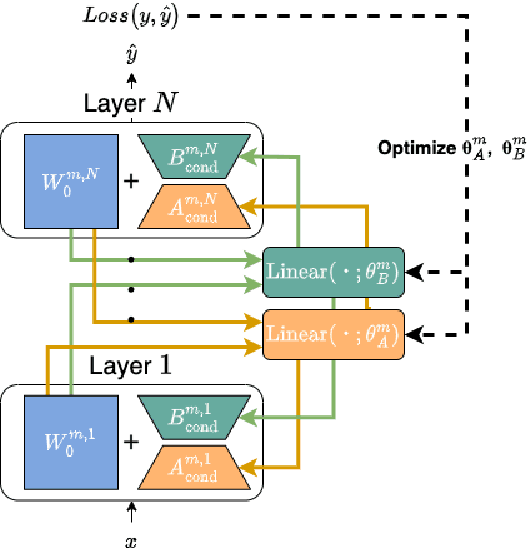
Low-Rank Adaptation (LoRA) is a widely used Parameter-Efficient Fine-Tuning (PEFT) method that updates an initial weight matrix $W_0$ with a delta matrix $\Delta W$ consisted by two low-rank matrices $A$ and $B$. A previous study suggested that there is correlation between $W_0$ and $\Delta W$. In this study, we aim to delve deeper into relationships between $W_0$ and low-rank matrices $A$ and $B$ to further comprehend the behavior of LoRA. In particular, we analyze a conversion matrix that transform $W_0$ into low-rank matrices, which encapsulates information about the relationships. Our analysis reveals that the conversion matrices are similar across each layer. Inspired by these findings, we hypothesize that a single linear layer, which takes each layer's $W_0$ as input, can yield task-adapted low-rank matrices. To confirm this hypothesis, we devise a method named Conditionally Parameterized LoRA (CondLoRA) that updates initial weight matrices with low-rank matrices derived from a single linear layer. Our empirical results show that CondLoRA maintains a performance on par with LoRA, despite the fact that the trainable parameters of CondLoRA are fewer than those of LoRA. Therefore, we conclude that "a single linear layer yields task-adapted low-rank matrices."