 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe Medicine: Redefining Biomedical Research Through Human-AI Co-Work
Apr 26, 2026With the emergence of large language models (LLMs) and AI agent frameworks, the human-AI co-work paradigm known as Vibe Coding is changing how people code, making it more accessible and productive. In scientific research, where workflows are more complex and the burden of specialized labor limits independent researchers and those in low-resource areas, the potential impact is even greater, particularly in biomedicine, which involves heterogeneous data modalities and multi-step analytical pipelines. In this paper, we introduce Vibe Medicine, a co-work paradigm in which clinicians and researchers direct skill-augmented AI agents through natural language to execute complex, multi-step biomedical workflows, while retaining the role of research director who specifies objectives, reviews intermediate results, and makes domain-informed decisions. The enabling infrastructure consists of three layers: capable LLMs, agent frameworks such as OpenClaw and Hermes Agent, and the OpenClaw medical skills collection, which includes more than 1,000 curated skills from multiple open-source repositories. We analyze the architecture and skill categories of this collection across ten biomedical domains, and present case studies covering rare disease diagnosis, drug repurposing, and clinical trial design that demonstrate end-to-end workflows in practice. We also identify the principal risks, such as hallucination, data privacy, and over-reliance, and outline directions toward more reliable, trustworthy, and clinically integrated agent-assisted research that advances research and technological equity and reduces health care resource disparities.
NIM4-ASR: Towards Efficient, Robust, and Customizable Real-Time LLM-Based ASR
Apr 20, 2026Integrating large language models (LLMs) into automatic speech recognition (ASR) has become a mainstream paradigm in recent years. Although existing LLM-based ASR models demonstrate impressive performance on public benchmarks, their training remains predominantly data-driven, leaving key practical challenges insufficiently addressed -- particularly limited downward scalability in resource-constrained deployments and hallucinations under acoustically challenging conditions. To address these issues, we present NIM4-ASR, a production-oriented LLM-based ASR framework optimized for both efficiency and robustness. Grounded in a principled delineation of functional roles between the encoder and the LLM, we redesign the multi-stage training paradigm to align each module with its intended capability boundary. Specifically, we reformulate the pre-training architecture and objective to mitigate the modality gap and improve parameter efficiency; introduce an iterative asynchronous SFT stage to preserve acoustic fidelity and constrain representation drift; and design an ASR-specialized reinforcement learning stage to further enhance recognition quality and robustness. We additionally incorporate a suite of production-oriented optimizations, including robustness under noisy and silent conditions, real-time streaming inference, and hotword customization via retrieval-augmented generation (RAG). Experiments show that NIM4-ASR achieves state-of-the-art performance on multiple public benchmarks with merely 2.3B parameters, while substantially outperforming larger-scale competitors on internal benchmarks -- particularly in entity-intensive real-world scenarios. NIM4-ASR further supports million-scale hotword customization via RAG with sub-millisecond retrieval latency, enabling efficient adaptation to emerging entities and personalized user requirements.
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
Apr 15, 2026Reinforcement Learning from Human Feedback (RLHF) and related alignment paradigms have become central to steering large language models (LLMs) and multimodal large language models (MLLMs) toward human-preferred behaviors. However, these approaches introduce a systemic vulnerability: reward hacking, where models exploit imperfections in learned reward signals to maximize proxy objectives without fulfilling true task intent. As models scale and optimization intensifies, such exploitation manifests as verbosity bias, sycophancy, hallucinated justification, benchmark overfitting, and, in multimodal settings, perception--reasoning decoupling and evaluator manipulation. Recent evidence further suggests that seemingly benign shortcut behaviors can generalize into broader forms of misalignment, including deception and strategic gaming of oversight mechanisms. In this survey, we propose the Proxy Compression Hypothesis (PCH) as a unifying framework for understanding reward hacking. We formalize reward hacking as an emergent consequence of optimizing expressive policies against compressed reward representations of high-dimensional human objectives. Under this view, reward hacking arises from the interaction of objective compression, optimization amplification, and evaluator--policy co-adaptation. This perspective unifies empirical phenomena across RLHF, RLAIF, and RLVR regimes, and explains how local shortcut learning can generalize into broader forms of misalignment, including deception and strategic manipulation of oversight mechanisms. We further organize detection and mitigation strategies according to how they intervene on compression, amplification, or co-adaptation dynamics. By framing reward hacking as a structural instability of proxy-based alignment under scale, we highlight open challenges in scalable oversight, multimodal grounding, and agentic autonomy.
Spectral Scalpel: Amplifying Adjacent Action Discrepancy via Frequency-Selective Filtering for Skeleton-Based Action Segmentation
Mar 25, 2026Skeleton-based Temporal Action Segmentation (STAS) seeks to densely segment and classify diverse actions within long, untrimmed skeletal motion sequences. However, existing STAS methodologies face challenges of limited inter-class discriminability and blurred segmentation boundaries, primarily due to insufficient distinction of spatio-temporal patterns between adjacent actions. To address these limitations, we propose Spectral Scalpel, a frequency-selective filtering framework aimed at suppressing shared frequency components between adjacent distinct actions while amplifying their action-specific frequencies, thereby enhancing inter-action discrepancies and sharpening transition boundaries. Specifically, Spectral Scalpel employs adaptive multi-scale spectral filters as scalpels to edit frequency spectra, coupled with a discrepancy loss between adjacent actions serving as the surgical objective. This design amplifies representational disparities between neighboring actions, effectively mitigating boundary localization ambiguities and inter-class confusion. Furthermore, complementing long-term temporal modeling, we introduce a frequency-aware channel mixer to strengthen channel evolution by aggregating spectra across channels. This work presents a novel paradigm for STAS that extends conventional spatio-temporal modeling by incorporating frequency-domain analysis. Extensive experiments on five public datasets demonstrate that Spectral Scalpel achieves state-of-the-art performance. Code is available at https://github.com/HaoyuJi/SpecScalpel.
A Comparative Analysis of LLM Memorization at Statistical and Internal Levels: Cross-Model Commonalities and Model-Specific Signatures
Mar 23, 2026Memorization is a fundamental component of intelligence for both humans and LLMs. However, while LLM performance scales rapidly, our understanding of memorization lags. Due to limited access to the pre-training data of LLMs, most previous studies focus on a single model series, leading to isolated observations among series, making it unclear which findings are general or specific. In this study, we collect multiple model series (Pythia, OpenLLaMa, StarCoder, OLMo1/2/3) and analyze their shared or unique memorization behavior at both the statistical and internal levels, connecting individual observations while showing new findings. At the statistical level, we reveal that the memorization rate scales log-linearly with model size, and memorized sequences can be further compressed. Further analysis demonstrated a shared frequency and domain distribution pattern for memorized sequences. However, different models also show individual features under the above observations. At the internal level, we find that LLMs can remove certain injected perturbations, while memorized sequences are more sensitive. By decoding middle layers and attention head ablation, we revealed the general decoding process and shared important heads for memorization. However, the distribution of those important heads differs between families, showing a unique family-level feature. Through bridging various experiments and revealing new findings, this study paves the way for a universal and fundamental understanding of memorization in LLM.
Seeing Beyond 8bits: Subjective and Objective Quality Assessment of HDR-UGC Videos
Mar 01, 2026High Dynamic Range (HDR) user-generated (UGC) videos are rapidly proliferating across social platforms, yet most perceptual video quality assessment (VQA) systems remain tailored to Standard Dynamic Range (SDR). HDR has a higher bit depth, wide color gamut, and elevated luminance range, exposing distortions such as near-black crushing, highlight clipping, banding, and exposure flicker that amplify UGC artifacts and challenge SDR models. To catalyze progress, we curate Beyond8Bits, a large-scale subjective dataset of 44K videos from 6.5K sources with over 1.5M crowd ratings, spanning diverse scenes, capture conditions, and compression settings. We further introduce HDR-Q, the first Multimodal Large Language Model (MLLM) for HDR-UGC VQA. We propose (i) a novel HDR-aware vision encoder to produce HDR-sensitive embeddings, and (ii) HDR-Aware Policy Optimization (HAPO), an RL finetuning framework that anchors reasoning to HDR cues. HAPO augments GRPO via an HDR-SDR contrastive KL that encourages token reliance on HDR inputs and a Gaussian weighted regression reward for fine-grained MOS calibration. Across Beyond8Bits and public HDR-VQA benchmarks, HDR-Q delivers state-of-the-art performance.
RegionRoute: Regional Style Transfer with Diffusion Model
Feb 22, 2026Precise spatial control in diffusion-based style transfer remains challenging. This challenge arises because diffusion models treat style as a global feature and lack explicit spatial grounding of style representations, making it difficult to restrict style application to specific objects or regions. To our knowledge, existing diffusion models are unable to perform true localized style transfer, typically relying on handcrafted masks or multi-stage post-processing that introduce boundary artifacts and limit generalization. To address this, we propose an attention-supervised diffusion framework that explicitly teaches the model where to apply a given style by aligning the attention scores of style tokens with object masks during training. Two complementary objectives, a Focus loss based on KL divergence and a Cover loss using binary cross-entropy, jointly encourage accurate localization and dense coverage. A modular LoRA-MoE design further enables efficient and scalable multi-style adaptation. To evaluate localized stylization, we introduce the Regional Style Editing Score, which measures Regional Style Matching through CLIP-based similarity within the target region and Identity Preservation via masked LPIPS and pixel-level consistency on unedited areas. Experiments show that our method achieves mask-free, single-object style transfer at inference, producing regionally accurate and visually coherent results that outperform existing diffusion-based editing approaches.
SPICE: Submodular Penalized Information-Conflict Selection for Efficient Large Language Model Training
Jan 30, 2026Information-based data selection for instruction tuning is compelling: maximizing the log-determinant of the Fisher information yields a monotone submodular objective, enabling greedy algorithms to achieve a $(1-1/e)$ approximation under a cardinality budget. In practice, however, we identify alleviating gradient conflicts, misalignment between per-sample gradients, is a key factor that slows down the decay of marginal log-determinant information gains, thereby preventing significant loss of information. We formalize this via an $\varepsilon$-decomposition that quantifies the deviation from ideal submodularity as a function of conflict statistics, yielding data-dependent approximation factors that tighten as conflicts diminish. Guided by this analysis, we propose SPICE, a conflict-aware selector that maximizes information while penalizing misalignment, and that supports early stopping and proxy models for efficiency. Empirically, SPICE selects subsets with higher log-determinant information than original criteria, and these informational gains translate into performance improvements: across 8 benchmarks with LLaMA2-7B and Qwen2-7B, SPICE uses only 10% of the data, yet matches or exceeds 6 methods including full-data tuning. This achieves performance improvements with substantially lower training cost.
RSRefSeg 2: Decoupling Referring Remote Sensing Image Segmentation with Foundation Models
Jul 08, 2025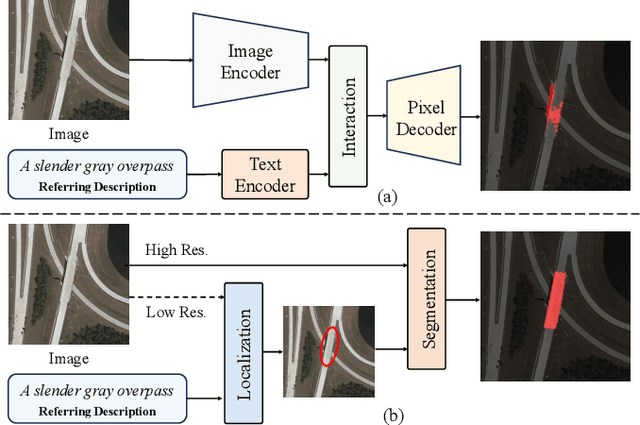
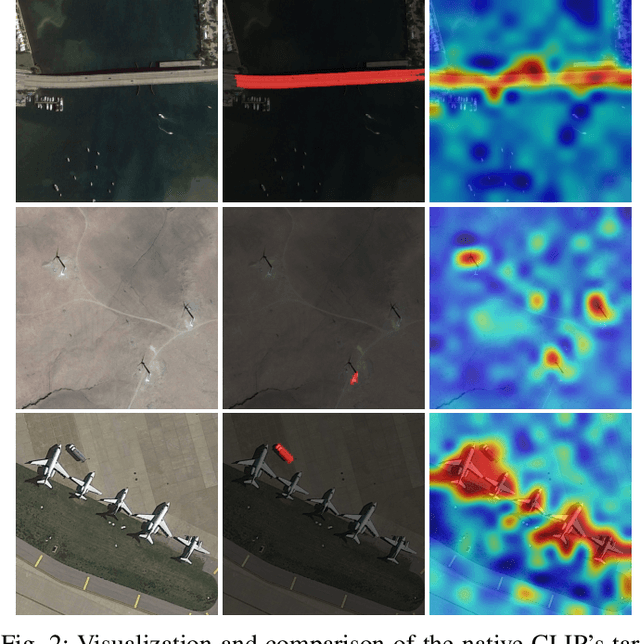
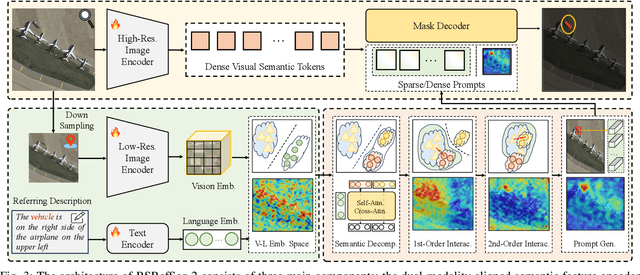
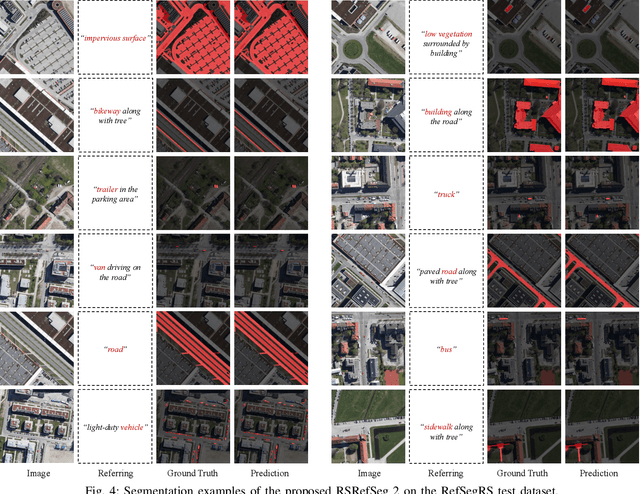
Referring Remote Sensing Image Segmentation provides a flexible and fine-grained framework for remote sensing scene analysis via vision-language collaborative interpretation. Current approaches predominantly utilize a three-stage pipeline encompassing dual-modal encoding, cross-modal interaction, and pixel decoding. These methods demonstrate significant limitations in managing complex semantic relationships and achieving precise cross-modal alignment, largely due to their coupled processing mechanism that conflates target localization with boundary delineation. This architectural coupling amplifies error propagation under semantic ambiguity while restricting model generalizability and interpretability. To address these issues, we propose RSRefSeg 2, a decoupling paradigm that reformulates the conventional workflow into a collaborative dual-stage framework: coarse localization followed by fine segmentation. RSRefSeg 2 integrates CLIP's cross-modal alignment strength with SAM's segmentation generalizability through strategic foundation model collaboration. Specifically, CLIP is employed as the dual-modal encoder to activate target features within its pre-aligned semantic space and generate localization prompts. To mitigate CLIP's misactivation challenges in multi-entity scenarios described by referring texts, a cascaded second-order prompter is devised, which enhances precision through implicit reasoning via decomposition of text embeddings into complementary semantic subspaces. These optimized semantic prompts subsequently direct the SAM to generate pixel-level refined masks, thereby completing the semantic transmission pipeline. Extensive experiments (RefSegRS, RRSIS-D, and RISBench) demonstrate that RSRefSeg 2 surpasses contemporary methods in segmentation accuracy (+~3% gIoU) and complex semantic interpretation. Code is available at: https://github.com/KyanChen/RSRefSeg2.
OMS: On-the-fly, Multi-Objective, Self-Reflective Ad Keyword Generation via LLM Agent
Jul 03, 2025



Keyword decision in Sponsored Search Advertising is critical to the success of ad campaigns. While LLM-based methods offer automated keyword generation, they face three major limitations: reliance on large-scale query-keyword pair data, lack of online multi-objective performance monitoring and optimization, and weak quality control in keyword selection. These issues hinder the agentic use of LLMs in fully automating keyword decisions by monitoring and reasoning over key performance indicators such as impressions, clicks, conversions, and CTA effectiveness. To overcome these challenges, we propose OMS, a keyword generation framework that is On-the-fly (requires no training data, monitors online performance, and adapts accordingly), Multi-objective (employs agentic reasoning to optimize keywords based on multiple performance metrics), and Self-reflective (agentically evaluates keyword quality). Experiments on benchmarks and real-world ad campaigns show that OMS outperforms existing methods; ablation and human evaluations confirm the effectiveness of each component and the quality of generated keywords.