 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCancerGUIDE: Cancer Guideline Understanding via Internal Disagreement Estimation
Sep 09, 2025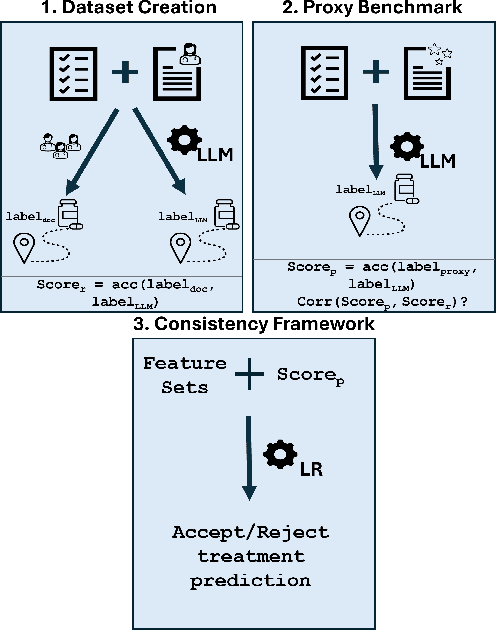
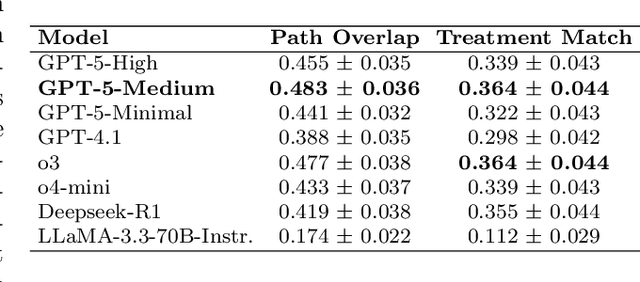
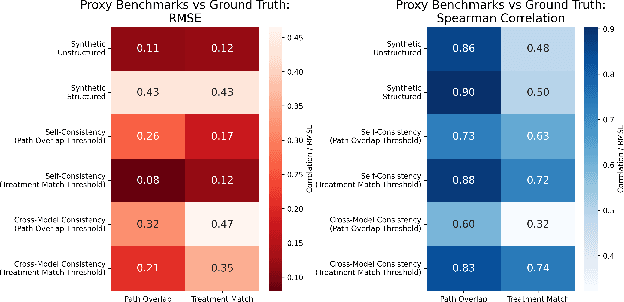

The National Comprehensive Cancer Network (NCCN) provides evidence-based guidelines for cancer treatment. Translating complex patient presentations into guideline-compliant treatment recommendations is time-intensive, requires specialized expertise, and is prone to error. Advances in large language model (LLM) capabilities promise to reduce the time required to generate treatment recommendations and improve accuracy. We present an LLM agent-based approach to automatically generate guideline-concordant treatment trajectories for patients with non-small cell lung cancer (NSCLC). Our contributions are threefold. First, we construct a novel longitudinal dataset of 121 cases of NSCLC patients that includes clinical encounters, diagnostic results, and medical histories, each expertly annotated with the corresponding NCCN guideline trajectories by board-certified oncologists. Second, we demonstrate that existing LLMs possess domain-specific knowledge that enables high-quality proxy benchmark generation for both model development and evaluation, achieving strong correlation (Spearman coefficient r=0.88, RMSE = 0.08) with expert-annotated benchmarks. Third, we develop a hybrid approach combining expensive human annotations with model consistency information to create both the agent framework that predicts the relevant guidelines for a patient, as well as a meta-classifier that verifies prediction accuracy with calibrated confidence scores for treatment recommendations (AUROC=0.800), a critical capability for communicating the accuracy of outputs, custom-tailoring tradeoffs in performance, and supporting regulatory compliance. This work establishes a framework for clinically viable LLM-based guideline adherence systems that balance accuracy, interpretability, and regulatory requirements while reducing annotation costs, providing a scalable pathway toward automated clinical decision support.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
TIMER: Temporal Instruction Modeling and Evaluation for Longitudinal Clinical Records
Mar 06, 2025Large language models (LLMs) have emerged as promising tools for assisting in medical tasks, yet processing Electronic Health Records (EHRs) presents unique challenges due to their longitudinal nature. While LLMs' capabilities to perform medical tasks continue to improve, their ability to reason over temporal dependencies across multiple patient visits and time frames remains unexplored. We introduce TIMER (Temporal Instruction Modeling and Evaluation for Longitudinal Clinical Records), a framework that incorporate instruction-response pairs grounding to different parts of a patient's record as a critical dimension in both instruction evaluation and tuning for longitudinal clinical records. We develop TIMER-Bench, the first time-aware benchmark that evaluates temporal reasoning capabilities over longitudinal EHRs, as well as TIMER-Instruct, an instruction-tuning methodology for LLMs to learn reasoning over time. We demonstrate that models fine-tuned with TIMER-Instruct improve performance by 7.3% on human-generated benchmarks and 9.2% on TIMER-Bench, indicating that temporal instruction-tuning improves model performance for reasoning over EHR.
μ-Bench: A Vision-Language Benchmark for Microscopy Understanding
Jul 01, 2024



Recent advances in microscopy have enabled the rapid generation of terabytes of image data in cell biology and biomedical research. Vision-language models (VLMs) offer a promising solution for large-scale biological image analysis, enhancing researchers' efficiency, identifying new image biomarkers, and accelerating hypothesis generation and scientific discovery. However, there is a lack of standardized, diverse, and large-scale vision-language benchmarks to evaluate VLMs' perception and cognition capabilities in biological image understanding. To address this gap, we introduce {\mu}-Bench, an expert-curated benchmark encompassing 22 biomedical tasks across various scientific disciplines (biology, pathology), microscopy modalities (electron, fluorescence, light), scales (subcellular, cellular, tissue), and organisms in both normal and abnormal states. We evaluate state-of-the-art biomedical, pathology, and general VLMs on {\mu}-Bench and find that: i) current models struggle on all categories, even for basic tasks such as distinguishing microscopy modalities; ii) current specialist models fine-tuned on biomedical data often perform worse than generalist models; iii) fine-tuning in specific microscopy domains can cause catastrophic forgetting, eroding prior biomedical knowledge encoded in their base model. iv) weight interpolation between fine-tuned and pre-trained models offers one solution to forgetting and improves general performance across biomedical tasks. We release {\mu}-Bench under a permissive license to accelerate the research and development of microscopy foundation models.
Towards an Improved Understanding and Utilization of Maximum Manifold Capacity Representations
Jun 13, 2024Maximum Manifold Capacity Representations (MMCR) is a recent multi-view self-supervised learning (MVSSL) method that matches or surpasses other leading MVSSL methods. MMCR is intriguing because it does not fit neatly into any of the commonplace MVSSL lineages, instead originating from a statistical mechanical perspective on the linear separability of data manifolds. In this paper, we seek to improve our understanding and our utilization of MMCR. To better understand MMCR, we leverage tools from high dimensional probability to demonstrate that MMCR incentivizes alignment and uniformity of learned embeddings. We then leverage tools from information theory to show that such embeddings maximize a well-known lower bound on mutual information between views, thereby connecting the geometric perspective of MMCR to the information-theoretic perspective commonly discussed in MVSSL. To better utilize MMCR, we mathematically predict and experimentally confirm non-monotonic changes in the pretraining loss akin to double descent but with respect to atypical hyperparameters. We also discover compute scaling laws that enable predicting the pretraining loss as a function of gradients steps, batch size, embedding dimension and number of views. We then show that MMCR, originally applied to image data, is performant on multimodal image-text data. By more deeply understanding the theoretical and empirical behavior of MMCR, our work reveals insights on improving MVSSL methods.
Why are Visually-Grounded Language Models Bad at Image Classification?
May 28, 2024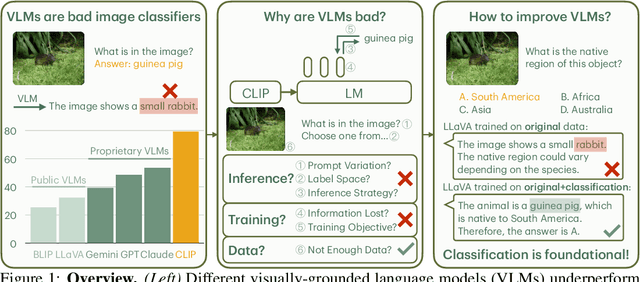
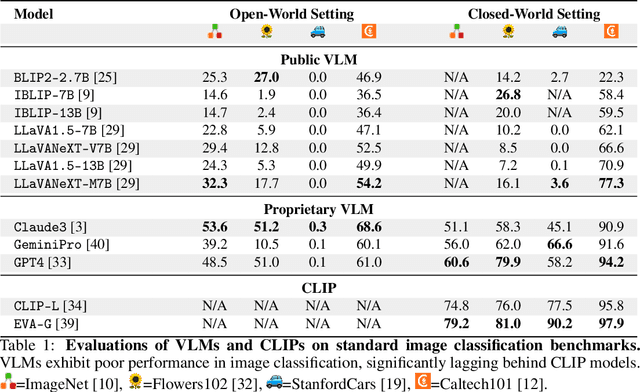
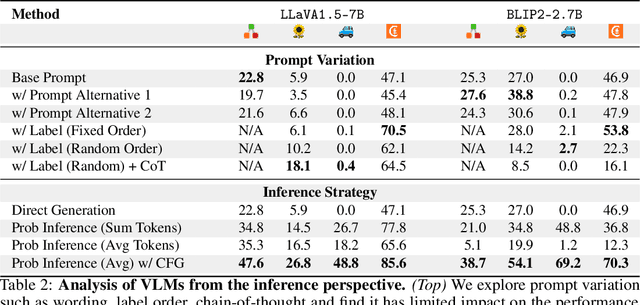
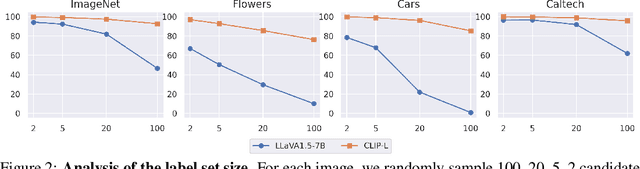
Image classification is one of the most fundamental capabilities of machine vision intelligence. In this work, we revisit the image classification task using visually-grounded language models (VLMs) such as GPT-4V and LLaVA. We find that existing proprietary and public VLMs, despite often using CLIP as a vision encoder and having many more parameters, significantly underperform CLIP on standard image classification benchmarks like ImageNet. To understand the reason, we explore several hypotheses concerning the inference algorithms, training objectives, and data processing in VLMs. Our analysis reveals that the primary cause is data-related: critical information for image classification is encoded in the VLM's latent space but can only be effectively decoded with enough training data. Specifically, there is a strong correlation between the frequency of class exposure during VLM training and instruction-tuning and the VLM's performance in those classes; when trained with sufficient data, VLMs can match the accuracy of state-of-the-art classification models. Based on these findings, we enhance a VLM by integrating classification-focused datasets into its training, and demonstrate that the enhanced classification performance of the VLM transfers to its general capabilities, resulting in an improvement of 11.8% on the newly collected ImageWikiQA dataset.