 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor defense, learnability and obfuscation
Sep 04, 2024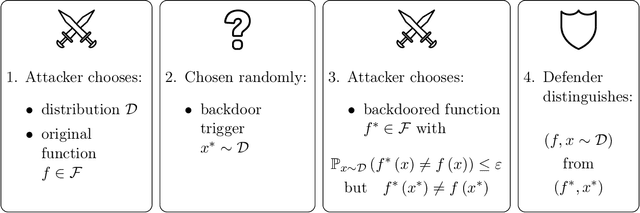
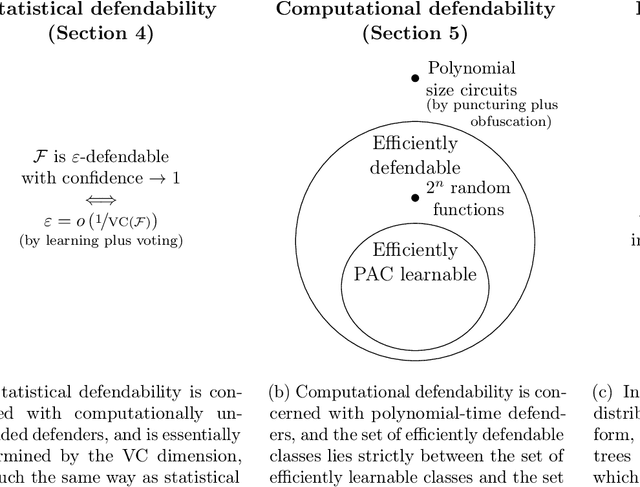
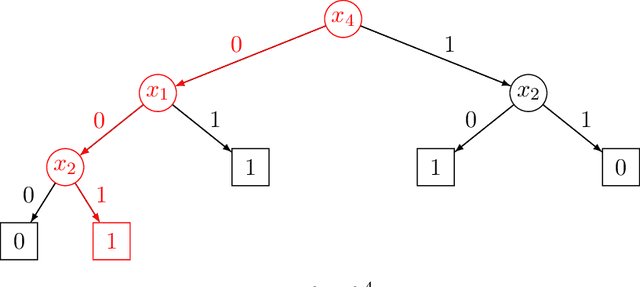
We introduce a formal notion of defendability against backdoors using a game between an attacker and a defender. In this game, the attacker modifies a function to behave differently on a particular input known as the "trigger", while behaving the same almost everywhere else. The defender then attempts to detect the trigger at evaluation time. If the defender succeeds with high enough probability, then the function class is said to be defendable. The key constraint on the attacker that makes defense possible is that the attacker's strategy must work for a randomly-chosen trigger. Our definition is simple and does not explicitly mention learning, yet we demonstrate that it is closely connected to learnability. In the computationally unbounded setting, we use a voting algorithm of Hanneke et al. (2022) to show that defendability is essentially determined by the VC dimension of the function class, in much the same way as PAC learnability. In the computationally bounded setting, we use a similar argument to show that efficient PAC learnability implies efficient defendability, but not conversely. On the other hand, we use indistinguishability obfuscation to show that the class of polynomial size circuits is not efficiently defendable. Finally, we present polynomial size decision trees as a natural example for which defense is strictly easier than learning. Thus, we identify efficient defendability as a notable intermediate concept in between efficient learnability and obfuscation.
Towards an Improved Understanding and Utilization of Maximum Manifold Capacity Representations
Jun 13, 2024Maximum Manifold Capacity Representations (MMCR) is a recent multi-view self-supervised learning (MVSSL) method that matches or surpasses other leading MVSSL methods. MMCR is intriguing because it does not fit neatly into any of the commonplace MVSSL lineages, instead originating from a statistical mechanical perspective on the linear separability of data manifolds. In this paper, we seek to improve our understanding and our utilization of MMCR. To better understand MMCR, we leverage tools from high dimensional probability to demonstrate that MMCR incentivizes alignment and uniformity of learned embeddings. We then leverage tools from information theory to show that such embeddings maximize a well-known lower bound on mutual information between views, thereby connecting the geometric perspective of MMCR to the information-theoretic perspective commonly discussed in MVSSL. To better utilize MMCR, we mathematically predict and experimentally confirm non-monotonic changes in the pretraining loss akin to double descent but with respect to atypical hyperparameters. We also discover compute scaling laws that enable predicting the pretraining loss as a function of gradients steps, batch size, embedding dimension and number of views. We then show that MMCR, originally applied to image data, is performant on multimodal image-text data. By more deeply understanding the theoretical and empirical behavior of MMCR, our work reveals insights on improving MVSSL methods.
Incidental Polysemanticity
Dec 05, 2023



Polysemantic neurons (neurons that activate for a set of unrelated features) have been seen as a significant obstacle towards interpretability of task-optimized deep networks, with implications for AI safety. The classic origin story of polysemanticity is that the data contains more "features" than neurons, such that learning to perform a task forces the network to co-allocate multiple unrelated features to the same neuron, endangering our ability to understand the network's internal processing. In this work, we present a second and non-mutually exclusive origin story of polysemanticity. We show that polysemanticity can arise incidentally, even when there are ample neurons to represent all features in the data, using a combination of theory and experiments. This second type of polysemanticity occurs because random initialization can, by chance alone, initially assign multiple features to the same neuron, and the training dynamics then strengthen such overlap. Due to its origin, we term this \textit{incidental polysemanticity}.