 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
Feb 03, 2026We present EB-JEPA, an open-source library for learning representations and world models using Joint-Embedding Predictive Architectures (JEPAs). JEPAs learn to predict in representation space rather than pixel space, avoiding the pitfalls of generative modeling while capturing semantically meaningful features suitable for downstream tasks. Our library provides modular, self-contained implementations that illustrate how representation learning techniques developed for image-level self-supervised learning can transfer to video, where temporal dynamics add complexity, and ultimately to action-conditioned world models, where the model must additionally learn to predict the effects of control inputs. Each example is designed for single-GPU training within a few hours, making energy-based self-supervised learning accessible for research and education. We provide ablations of JEA components on CIFAR-10. Probing these representations yields 91% accuracy, indicating that the model learns useful features. Extending to video, we include a multi-step prediction example on Moving MNIST that demonstrates how the same principles scale to temporal modeling. Finally, we show how these representations can drive action-conditioned world models, achieving a 97% planning success rate on the Two Rooms navigation task. Comprehensive ablations reveal the critical importance of each regularization component for preventing representation collapse. Code is available at https://github.com/facebookresearch/eb_jepa.
Rectified LpJEPA: Joint-Embedding Predictive Architectures with Sparse and Maximum-Entropy Representations
Feb 01, 2026Joint-Embedding Predictive Architectures (JEPA) learn view-invariant representations and admit projection-based distribution matching for collapse prevention. Existing approaches regularize representations towards isotropic Gaussian distributions, but inherently favor dense representations and fail to capture the key property of sparsity observed in efficient representations. We introduce Rectified Distribution Matching Regularization (RDMReg), a sliced two-sample distribution-matching loss that aligns representations to a Rectified Generalized Gaussian (RGG) distribution. RGG enables explicit control over expected $\ell_0$ norm through rectification, while preserving maximum-entropy up to rescaling under expected $\ell_p$ norm constraints. Equipping JEPAs with RDMReg yields Rectified LpJEPA, which strictly generalizes prior Gaussian-based JEPAs. Empirically, Rectified LpJEPA learns sparse, non-negative representations with favorable sparsity-performance trade-offs and competitive downstream performance on image classification benchmarks, demonstrating that RDMReg effectively enforces sparsity while preserving task-relevant information.
Parallel Stochastic Gradient-Based Planning for World Models
Jan 31, 2026World models simulate environment dynamics from raw sensory inputs like video. However, using them for planning can be challenging due to the vast and unstructured search space. We propose a robust and highly parallelizable planner that leverages the differentiability of the learned world model for efficient optimization, solving long-horizon control tasks from visual input. Our method treats states as optimization variables ("virtual states") with soft dynamics constraints, enabling parallel computation and easier optimization. To facilitate exploration and avoid local optima, we introduce stochasticity into the states. To mitigate sensitive gradients through high-dimensional vision-based world models, we modify the gradient structure to descend towards valid plans while only requiring action-input gradients. Our planner, which we call GRASP (Gradient RelAxed Stochastic Planner), can be viewed as a stochastic version of a non-condensed or collocation-based optimal controller. We provide theoretical justification and experiments on video-based world models, where our resulting planner outperforms existing planning algorithms like the cross-entropy method (CEM) and vanilla gradient-based optimization (GD) on long-horizon experiments, both in success rate and time to convergence.
Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
Jan 22, 2026Representation Autoencoders (RAEs) have shown distinct advantages in diffusion modeling on ImageNet by training in high-dimensional semantic latent spaces. In this work, we investigate whether this framework can scale to large-scale, freeform text-to-image (T2I) generation. We first scale RAE decoders on the frozen representation encoder (SigLIP-2) beyond ImageNet by training on web, synthetic, and text-rendering data, finding that while scale improves general fidelity, targeted data composition is essential for specific domains like text. We then rigorously stress-test the RAE design choices originally proposed for ImageNet. Our analysis reveals that scaling simplifies the framework: while dimension-dependent noise scheduling remains critical, architectural complexities such as wide diffusion heads and noise-augmented decoding offer negligible benefits at scale Building on this simplified framework, we conduct a controlled comparison of RAE against the state-of-the-art FLUX VAE across diffusion transformer scales from 0.5B to 9.8B parameters. RAEs consistently outperform VAEs during pretraining across all model scales. Further, during finetuning on high-quality datasets, VAE-based models catastrophically overfit after 64 epochs, while RAE models remain stable through 256 epochs and achieve consistently better performance. Across all experiments, RAE-based diffusion models demonstrate faster convergence and better generation quality, establishing RAEs as a simpler and stronger foundation than VAEs for large-scale T2I generation. Additionally, because both visual understanding and generation can operate in a shared representation space, the multimodal model can directly reason over generated latents, opening new possibilities for unified models.
Learning Latent Action World Models In The Wild
Jan 08, 2026Agents capable of reasoning and planning in the real world require the ability of predicting the consequences of their actions. While world models possess this capability, they most often require action labels, that can be complex to obtain at scale. This motivates the learning of latent action models, that can learn an action space from videos alone. Our work addresses the problem of learning latent actions world models on in-the-wild videos, expanding the scope of existing works that focus on simple robotics simulations, video games, or manipulation data. While this allows us to capture richer actions, it also introduces challenges stemming from the video diversity, such as environmental noise, or the lack of a common embodiment across videos. To address some of the challenges, we discuss properties that actions should follow as well as relevant architectural choices and evaluations. We find that continuous, but constrained, latent actions are able to capture the complexity of actions from in-the-wild videos, something that the common vector quantization does not. We for example find that changes in the environment coming from agents, such as humans entering the room, can be transferred across videos. This highlights the capability of learning actions that are specific to in-the-wild videos. In the absence of a common embodiment across videos, we are mainly able to learn latent actions that become localized in space, relative to the camera. Nonetheless, we are able to train a controller that maps known actions to latent ones, allowing us to use latent actions as a universal interface and solve planning tasks with our world model with similar performance as action-conditioned baselines. Our analyses and experiments provide a step towards scaling latent action models to the real world.
What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?
Dec 30, 2025A long-standing challenge in AI is to develop agents capable of solving a wide range of physical tasks and generalizing to new, unseen tasks and environments. A popular recent approach involves training a world model from state-action trajectories and subsequently use it with a planning algorithm to solve new tasks. Planning is commonly performed in the input space, but a recent family of methods has introduced planning algorithms that optimize in the learned representation space of the world model, with the promise that abstracting irrelevant details yields more efficient planning. In this work, we characterize models from this family as JEPA-WMs and investigate the technical choices that make algorithms from this class work. We propose a comprehensive study of several key components with the objective of finding the optimal approach within the family. We conducted experiments using both simulated environments and real-world robotic data, and studied how the model architecture, the training objective, and the planning algorithm affect planning success. We combine our findings to propose a model that outperforms two established baselines, DINO-WM and V-JEPA-2-AC, in both navigation and manipulation tasks. Code, data and checkpoints are available at https://github.com/facebookresearch/jepa-wms.
Value-guided action planning with JEPA world models
Dec 28, 2025Building deep learning models that can reason about their environment requires capturing its underlying dynamics. Joint-Embedded Predictive Architectures (JEPA) provide a promising framework to model such dynamics by learning representations and predictors through a self-supervised prediction objective. However, their ability to support effective action planning remains limited. We propose an approach to enhance planning with JEPA world models by shaping their representation space so that the negative goal-conditioned value function for a reaching cost in a given environment is approximated by a distance (or quasi-distance) between state embeddings. We introduce a practical method to enforce this constraint during training and show that it leads to significantly improved planning performance compared to standard JEPA models on simple control tasks.
SpidR-Adapt: A Universal Speech Representation Model for Few-Shot Adaptation
Dec 24, 2025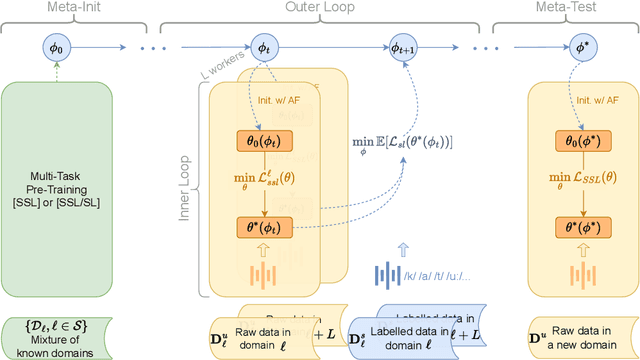

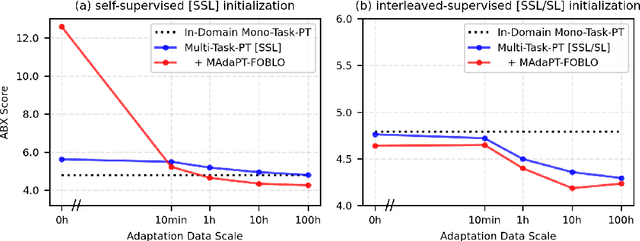
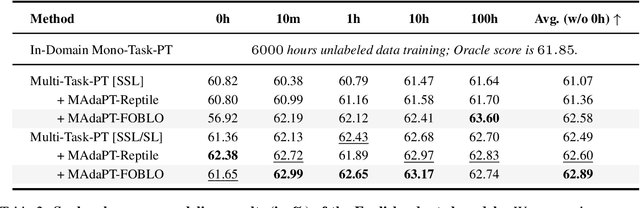
Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain language models after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
World Models Can Leverage Human Videos for Dexterous Manipulation
Dec 15, 2025
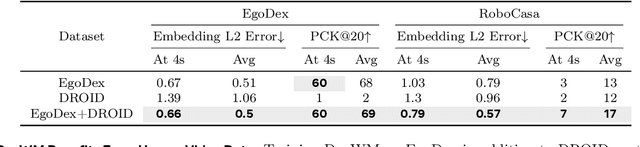
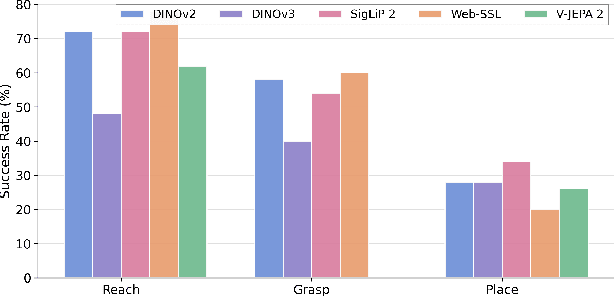
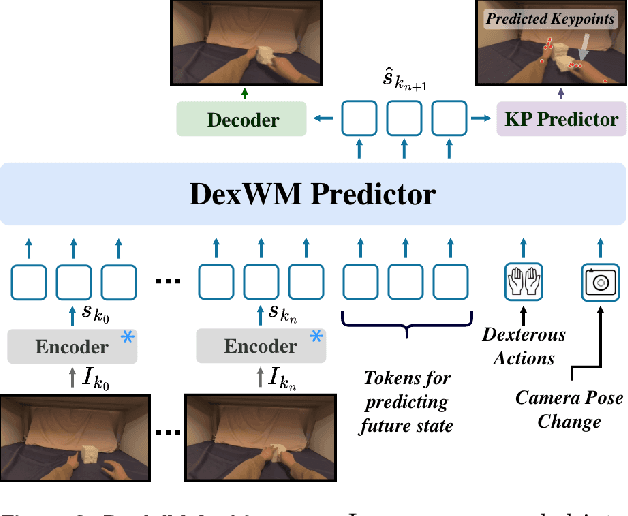
Dexterous manipulation is challenging because it requires understanding how subtle hand motion influences the environment through contact with objects. We introduce DexWM, a Dexterous Manipulation World Model that predicts the next latent state of the environment conditioned on past states and dexterous actions. To overcome the scarcity of dexterous manipulation datasets, DexWM is trained on over 900 hours of human and non-dexterous robot videos. To enable fine-grained dexterity, we find that predicting visual features alone is insufficient; therefore, we introduce an auxiliary hand consistency loss that enforces accurate hand configurations. DexWM outperforms prior world models conditioned on text, navigation, and full-body actions, achieving more accurate predictions of future states. DexWM also demonstrates strong zero-shot generalization to unseen manipulation skills when deployed on a Franka Panda arm equipped with an Allegro gripper, outperforming Diffusion Policy by over 50% on average in grasping, placing, and reaching tasks.
VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
Dec 11, 2025We introduce VL-JEPA, a vision-language model built on a Joint Embedding Predictive Architecture (JEPA). Instead of autoregressively generating tokens as in classical VLMs, VL-JEPA predicts continuous embeddings of the target texts. By learning in an abstract representation space, the model focuses on task-relevant semantics while abstracting away surface-level linguistic variability. In a strictly controlled comparison against standard token-space VLM training with the same vision encoder and training data, VL-JEPA achieves stronger performance while having 50% fewer trainable parameters. At inference time, a lightweight text decoder is invoked only when needed to translate VL-JEPA predicted embeddings into text. We show that VL-JEPA natively supports selective decoding that reduces the number of decoding operations by 2.85x while maintaining similar performance compared to non-adaptive uniform decoding. Beyond generation, the VL-JEPA's embedding space naturally supports open-vocabulary classification, text-to-video retrieval, and discriminative VQA without any architecture modification. On eight video classification and eight video retrieval datasets, the average performance VL-JEPA surpasses that of CLIP, SigLIP2, and Perception Encoder. At the same time, the model achieves comparable performance as classical VLMs (InstructBLIP, QwenVL) on four VQA datasets: GQA, TallyQA, POPE and POPEv2, despite only having 1.6B parameters.