 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Stochastic Gradient-Based Planning for World Models
Jan 31, 2026World models simulate environment dynamics from raw sensory inputs like video. However, using them for planning can be challenging due to the vast and unstructured search space. We propose a robust and highly parallelizable planner that leverages the differentiability of the learned world model for efficient optimization, solving long-horizon control tasks from visual input. Our method treats states as optimization variables ("virtual states") with soft dynamics constraints, enabling parallel computation and easier optimization. To facilitate exploration and avoid local optima, we introduce stochasticity into the states. To mitigate sensitive gradients through high-dimensional vision-based world models, we modify the gradient structure to descend towards valid plans while only requiring action-input gradients. Our planner, which we call GRASP (Gradient RelAxed Stochastic Planner), can be viewed as a stochastic version of a non-condensed or collocation-based optimal controller. We provide theoretical justification and experiments on video-based world models, where our resulting planner outperforms existing planning algorithms like the cross-entropy method (CEM) and vanilla gradient-based optimization (GD) on long-horizon experiments, both in success rate and time to convergence.
Learning Latent Action World Models In The Wild
Jan 08, 2026Agents capable of reasoning and planning in the real world require the ability of predicting the consequences of their actions. While world models possess this capability, they most often require action labels, that can be complex to obtain at scale. This motivates the learning of latent action models, that can learn an action space from videos alone. Our work addresses the problem of learning latent actions world models on in-the-wild videos, expanding the scope of existing works that focus on simple robotics simulations, video games, or manipulation data. While this allows us to capture richer actions, it also introduces challenges stemming from the video diversity, such as environmental noise, or the lack of a common embodiment across videos. To address some of the challenges, we discuss properties that actions should follow as well as relevant architectural choices and evaluations. We find that continuous, but constrained, latent actions are able to capture the complexity of actions from in-the-wild videos, something that the common vector quantization does not. We for example find that changes in the environment coming from agents, such as humans entering the room, can be transferred across videos. This highlights the capability of learning actions that are specific to in-the-wild videos. In the absence of a common embodiment across videos, we are mainly able to learn latent actions that become localized in space, relative to the camera. Nonetheless, we are able to train a controller that maps known actions to latent ones, allowing us to use latent actions as a universal interface and solve planning tasks with our world model with similar performance as action-conditioned baselines. Our analyses and experiments provide a step towards scaling latent action models to the real world.
World Models Can Leverage Human Videos for Dexterous Manipulation
Dec 15, 2025
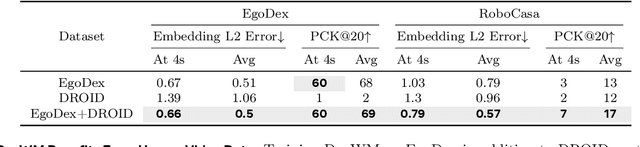
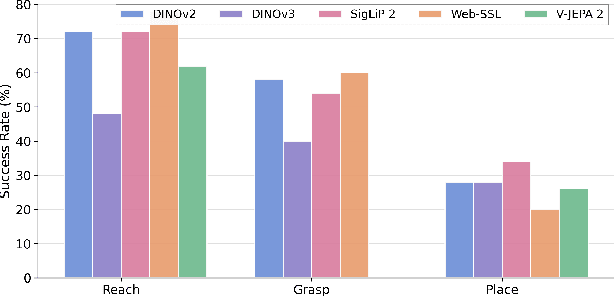
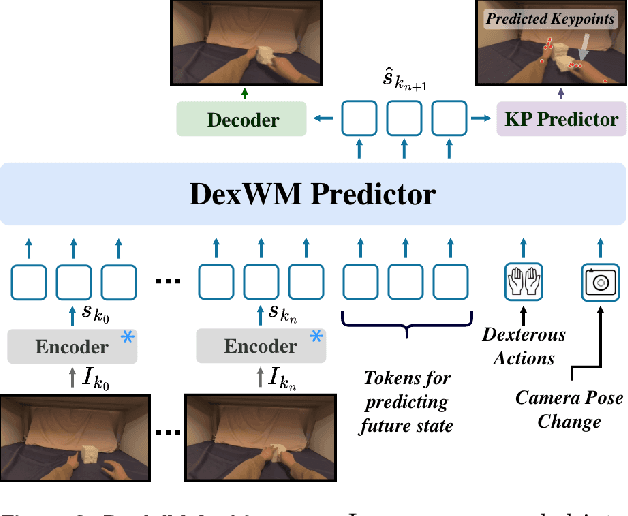
Dexterous manipulation is challenging because it requires understanding how subtle hand motion influences the environment through contact with objects. We introduce DexWM, a Dexterous Manipulation World Model that predicts the next latent state of the environment conditioned on past states and dexterous actions. To overcome the scarcity of dexterous manipulation datasets, DexWM is trained on over 900 hours of human and non-dexterous robot videos. To enable fine-grained dexterity, we find that predicting visual features alone is insufficient; therefore, we introduce an auxiliary hand consistency loss that enforces accurate hand configurations. DexWM outperforms prior world models conditioned on text, navigation, and full-body actions, achieving more accurate predictions of future states. DexWM also demonstrates strong zero-shot generalization to unseen manipulation skills when deployed on a Franka Panda arm equipped with an Allegro gripper, outperforming Diffusion Policy by over 50% on average in grasping, placing, and reaching tasks.
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
IntPhys 2: Benchmarking Intuitive Physics Understanding In Complex Synthetic Environments
Jun 11, 2025



We present IntPhys 2, a video benchmark designed to evaluate the intuitive physics understanding of deep learning models. Building on the original IntPhys benchmark, IntPhys 2 focuses on four core principles related to macroscopic objects: Permanence, Immutability, Spatio-Temporal Continuity, and Solidity. These conditions are inspired by research into intuitive physical understanding emerging during early childhood. IntPhys 2 offers a comprehensive suite of tests, based on the violation of expectation framework, that challenge models to differentiate between possible and impossible events within controlled and diverse virtual environments. Alongside the benchmark, we provide performance evaluations of several state-of-the-art models. Our findings indicate that while these models demonstrate basic visual understanding, they face significant challenges in grasping intuitive physics across the four principles in complex scenes, with most models performing at chance levels (50%), in stark contrast to human performance, which achieves near-perfect accuracy. This underscores the gap between current models and human-like intuitive physics understanding, highlighting the need for advancements in model architectures and training methodologies.
Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
Apr 19, 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
Scaling Language-Free Visual Representation Learning
Apr 01, 2025



Visual Self-Supervised Learning (SSL) currently underperforms Contrastive Language-Image Pretraining (CLIP) in multimodal settings such as Visual Question Answering (VQA). This multimodal gap is often attributed to the semantics introduced by language supervision, even though visual SSL and CLIP models are often trained on different data. In this work, we ask the question: "Do visual self-supervised approaches lag behind CLIP due to the lack of language supervision, or differences in the training data?" We study this question by training both visual SSL and CLIP models on the same MetaCLIP data, and leveraging VQA as a diverse testbed for vision encoders. In this controlled setup, visual SSL models scale better than CLIP models in terms of data and model capacity, and visual SSL performance does not saturate even after scaling up to 7B parameters. Consequently, we observe visual SSL methods achieve CLIP-level performance on a wide range of VQA and classic vision benchmarks. These findings demonstrate that pure visual SSL can match language-supervised visual pretraining at scale, opening new opportunities for vision-centric representation learning.
Accelerating Neural Network Training: An Analysis of the AlgoPerf Competition
Feb 20, 2025



The goal of the AlgoPerf: Training Algorithms competition is to evaluate practical speed-ups in neural network training achieved solely by improving the underlying training algorithms. In the external tuning ruleset, submissions must provide workload-agnostic hyperparameter search spaces, while in the self-tuning ruleset they must be completely hyperparameter-free. In both rulesets, submissions are compared on time-to-result across multiple deep learning workloads, training on fixed hardware. This paper presents the inaugural AlgoPerf competition's results, which drew 18 diverse submissions from 10 teams. Our investigation reveals several key findings: (1) The winning submission in the external tuning ruleset, using Distributed Shampoo, demonstrates the effectiveness of non-diagonal preconditioning over popular methods like Adam, even when compared on wall-clock runtime. (2) The winning submission in the self-tuning ruleset, based on the Schedule Free AdamW algorithm, demonstrates a new level of effectiveness for completely hyperparameter-free training algorithms. (3) The top-scoring submissions were surprisingly robust to workload changes. We also discuss the engineering challenges encountered in ensuring a fair comparison between different training algorithms. These results highlight both the significant progress so far, and the considerable room for further improvements.
Intuitive physics understanding emerges from self-supervised pretraining on natural videos
Feb 17, 2025We investigate the emergence of intuitive physics understanding in general-purpose deep neural network models trained to predict masked regions in natural videos. Leveraging the violation-of-expectation framework, we find that video prediction models trained to predict outcomes in a learned representation space demonstrate an understanding of various intuitive physics properties, such as object permanence and shape consistency. In contrast, video prediction in pixel space and multimodal large language models, which reason through text, achieve performance closer to chance. Our comparisons of these architectures reveal that jointly learning an abstract representation space while predicting missing parts of sensory input, akin to predictive coding, is sufficient to acquire an understanding of intuitive physics, and that even models trained on one week of unique video achieve above chance performance. This challenges the idea that core knowledge -- a set of innate systems to help understand the world -- needs to be hardwired to develop an understanding of intuitive physics.
Towards General-Purpose Model-Free Reinforcement Learning
Jan 27, 2025



Reinforcement learning (RL) promises a framework for near-universal problem-solving. In practice however, RL algorithms are often tailored to specific benchmarks, relying on carefully tuned hyperparameters and algorithmic choices. Recently, powerful model-based RL methods have shown impressive general results across benchmarks but come at the cost of increased complexity and slow run times, limiting their broader applicability. In this paper, we attempt to find a unifying model-free deep RL algorithm that can address a diverse class of domains and problem settings. To achieve this, we leverage model-based representations that approximately linearize the value function, taking advantage of the denser task objectives used by model-based RL while avoiding the costs associated with planning or simulated trajectories. We evaluate our algorithm, MR.Q, on a variety of common RL benchmarks with a single set of hyperparameters and show a competitive performance against domain-specific and general baselines, providing a concrete step towards building general-purpose model-free deep RL algorithms.