 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Reasoning Re-ranker
Feb 08, 2026Recent studies increasingly explore Large Language Models (LLMs) as a new paradigm for recommendation systems due to their scalability and world knowledge. However, existing work has three key limitations: (1) most efforts focus on retrieval and ranking, while the reranking phase, critical for refining final recommendations, is largely overlooked; (2) LLMs are typically used in zero-shot or supervised fine-tuning settings, leaving their reasoning abilities, especially those enhanced through reinforcement learning (RL) and high-quality reasoning data, underexploited; (3) items are commonly represented by non-semantic IDs, creating major scalability challenges in industrial systems with billions of identifiers. To address these gaps, we propose the Generative Reasoning Reranker (GR2), an end-to-end framework with a three-stage training pipeline tailored for reranking. First, a pretrained LLM is mid-trained on semantic IDs encoded from non-semantic IDs via a tokenizer achieving $\ge$99% uniqueness. Next, a stronger larger-scale LLM generates high-quality reasoning traces through carefully designed prompting and rejection sampling, which are used for supervised fine-tuning to impart foundational reasoning skills. Finally, we apply Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO), enabling scalable RL supervision with verifiable rewards designed specifically for reranking. Experiments on two real-world datasets demonstrate GR2's effectiveness: it surpasses the state-of-the-art OneRec-Think by 2.4% in Recall@5 and 1.3% in NDCG@5. Ablations confirm that advanced reasoning traces yield substantial gains across metrics. We further find that RL reward design is crucial in reranking: LLMs tend to exploit reward hacking by preserving item order, motivating conditional verifiable rewards to mitigate this behavior and optimize reranking performance.
MicLog: Towards Accurate and Efficient LLM-based Log Parsing via Progressive Meta In-Context Learning
Jan 11, 2026Log parsing converts semi-structured logs into structured templates, forming a critical foundation for downstream analysis. Traditional syntax and semantic-based parsers often struggle with semantic variations in evolving logs and data scarcity stemming from their limited domain coverage. Recent large language model (LLM)-based parsers leverage in-context learning (ICL) to extract semantics from examples, demonstrating superior accuracy. However, LLM-based parsers face two main challenges: 1) underutilization of ICL capabilities, particularly in dynamic example selection and cross-domain generalization, leading to inconsistent performance; 2) time-consuming and costly LLM querying. To address these challenges, we present MicLog, the first progressive meta in-context learning (ProgMeta-ICL) log parsing framework that combines meta-learning with ICL on small open-source LLMs (i.e., Qwen-2.5-3B). Specifically, MicLog: i) enhances LLMs' ICL capability through a zero-shot to k-shot ProgMeta-ICL paradigm, employing weighted DBSCAN candidate sampling and enhanced BM25 demonstration selection; ii) accelerates parsing via a multi-level pre-query cache that dynamically matches and refines recently parsed templates. Evaluated on Loghub-2.0, MicLog achieves 10.3% higher parsing accuracy than the state-of-the-art parser while reducing parsing time by 42.4%.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
A Distributed Data-Parallel PyTorch Implementation of the Distributed Shampoo Optimizer for Training Neural Networks At-Scale
Sep 12, 2023



Shampoo is an online and stochastic optimization algorithm belonging to the AdaGrad family of methods for training neural networks. It constructs a block-diagonal preconditioner where each block consists of a coarse Kronecker product approximation to full-matrix AdaGrad for each parameter of the neural network. In this work, we provide a complete description of the algorithm as well as the performance optimizations that our implementation leverages to train deep networks at-scale in PyTorch. Our implementation enables fast multi-GPU distributed data-parallel training by distributing the memory and computation associated with blocks of each parameter via PyTorch's DTensor data structure and performing an AllGather primitive on the computed search directions at each iteration. This major performance enhancement enables us to achieve at most a 10% performance reduction in per-step wall-clock time compared against standard diagonal-scaling-based adaptive gradient methods. We validate our implementation by performing an ablation study on training ImageNet ResNet50, demonstrating Shampoo's superiority over standard training recipes with minimal hyperparameter tuning.
Compiler-Driven Simulation of Reconfigurable Hardware Accelerators
Feb 01, 2022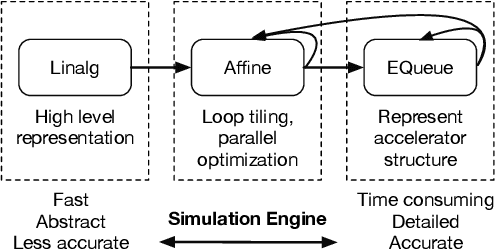


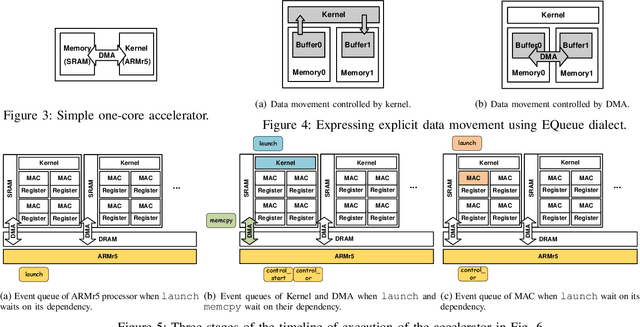
As customized accelerator design has become increasingly popular to keep up with the demand for high performance computing, it poses challenges for modern simulator design to adapt to such a large variety of accelerators. Existing simulators tend to two extremes: low-level and general approaches, such as RTL simulation, that can model any hardware but require substantial effort and long execution times; and higher-level application-specific models that can be much faster and easier to use but require one-off engineering effort. This work proposes a compiler-driven simulation workflow that can model configurable hardware accelerator. The key idea is to separate structure representation from simulation by developing an intermediate language that can flexibly represent a wide variety of hardware constructs. We design the Event Queue (EQueue) dialect of MLIR, a dialect that can model arbitrary hardware accelerators with explicit data movement and distributed event-based control; we also implement a generic simulation engine to model EQueue programs with hybrid MLIR dialects representing different abstraction levels. We demonstrate two case studies of EQueue-implemented accelerators: the systolic array of convolution and SIMD processors in a modern FPGA. In the former we show EQueue simulation is as accurate as a state-of-the-art simulator, while offering higher extensibility and lower iteration cost via compiler passes. In the latter we demonstrate our simulation flow can guide designer efficiently improve their design using visualizable simulation outputs.
Optimizing JPEG Quantization for Classification Networks
Mar 05, 2020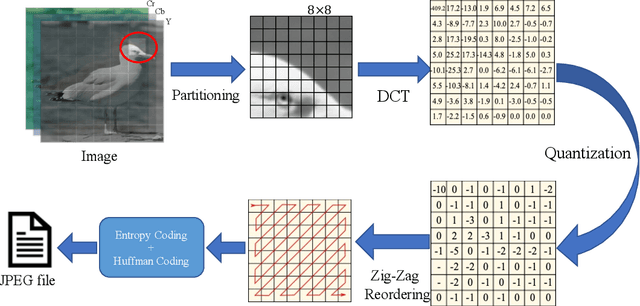

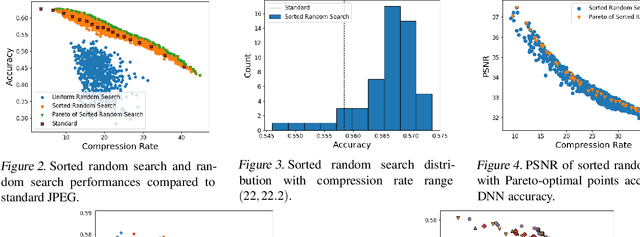
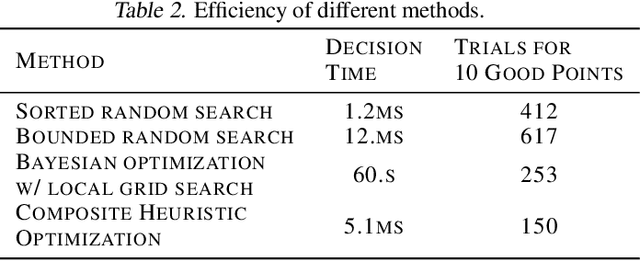
Deep learning for computer vision depends on lossy image compression: it reduces the storage required for training and test data and lowers transfer costs in deployment. Mainstream datasets and imaging pipelines all rely on standard JPEG compression. In JPEG, the degree of quantization of frequency coefficients controls the lossiness: an 8 by 8 quantization table (Q-table) decides both the quality of the encoded image and the compression ratio. While a long history of work has sought better Q-tables, existing work either seeks to minimize image distortion or to optimize for models of the human visual system. This work asks whether JPEG Q-tables exist that are "better" for specific vision networks and can offer better quality--size trade-offs than ones designed for human perception or minimal distortion. We reconstruct an ImageNet test set with higher resolution to explore the effect of JPEG compression under novel Q-tables. We attempt several approaches to tune a Q-table for a vision task. We find that a simple sorted random sampling method can exceed the performance of the standard JPEG Q-table. We also use hyper-parameter tuning techniques including bounded random search, Bayesian optimization, and composite heuristic optimization methods. The new Q-tables we obtained can improve the compression rate by 10% to 200% when the accuracy is fixed, or improve accuracy up to $2\%$ at the same compression rate.