 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating near-verbatim extraction risk in language models with decoding-constrained beam search
Mar 26, 2026Recent work shows that standard greedy-decoding extraction methods for quantifying memorization in LLMs miss how extraction risk varies across sequences. Probabilistic extraction -- computing the probability of generating a target suffix given a prefix under a decoding scheme -- addresses this, but is tractable only for verbatim memorization, missing near-verbatim instances that pose similar privacy and copyright risks. Quantifying near-verbatim extraction risk is expensive: the set of near-verbatim suffixes is combinatorially large, and reliable Monte Carlo (MC) estimation can require ~100,000 samples per sequence. To mitigate this cost, we introduce decoding-constrained beam search, which yields deterministic lower bounds on near-verbatim extraction risk at a cost comparable to ~20 MC samples per sequence. Across experiments, our approach surfaces information invisible to verbatim methods: many more extractable sequences, substantially larger per-sequence extraction mass, and patterns in how near-verbatim extraction risk manifests across model sizes and types of text.
L$^3$: Large Lookup Layers
Jan 29, 2026Modern sparse language models typically achieve sparsity through Mixture-of-Experts (MoE) layers, which dynamically route tokens to dense MLP "experts." However, dynamic hard routing has a number of drawbacks, such as potentially poor hardware efficiency and needing auxiliary losses for stable training. In contrast, the tokenizer embedding table, which is natively sparse, largely avoids these issues by selecting a single embedding per token at the cost of not having contextual information. In this work, we introduce the Large Lookup Layer (L$^3$), which unlocks a new axis of sparsity by generalizing embedding tables to model decoder layers. L$^3$ layers use static token-based routing to aggregate a set of learned embeddings per token in a context-dependent way, allowing the model to efficiently balance memory and compute by caching information in embeddings. L$^3$ has two main components: (1) a systems-friendly architecture that allows for fast training and CPU-offloaded inference with no overhead, and (2) an information-theoretic embedding allocation algorithm that effectively balances speed and quality. We empirically test L$^3$ by training transformers with up to 2.6B active parameters and find that L$^3$ strongly outperforms both dense models and iso-sparse MoEs in both language modeling and downstream tasks.
Model-Preserving Adaptive Rounding
May 29, 2025


The main goal of post-training quantization (PTQ) is to produced a compressed model whose output distribution is as close to the original model's as possible. To do this tractably, almost all LLM PTQ algorithms quantize linear layers by independently minimizing the immediate activation error. However, this localized objective ignores the effect of subsequent layers, so reducing it does not necessarily give a closer model. In this work, we introduce Yet Another Quantization Algorithm (YAQA), an adaptive rounding algorithm that uses Kronecker-factored approximations of each linear layer's Hessian with respect to the \textit{full model} KL divergence. YAQA consists of two components: Kronecker-factored sketches of the full layerwise Hessian that can be tractably computed for hundred-billion parameter LLMs, and a quantizer-independent rounding algorithm that uses these sketches and comes with theoretical guarantees. Across a wide range of models and quantizers, YAQA empirically reduces the KL divergence to the original model by $\approx 30\%$ while achieving state of the art performance on downstream tasks.
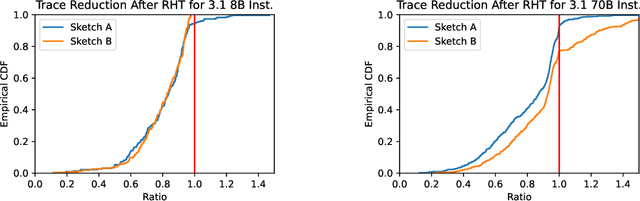
Extracting memorized pieces of (copyrighted) books from open-weight language models
May 18, 2025Plaintiffs and defendants in copyright lawsuits over generative AI often make sweeping, opposing claims about the extent to which large language models (LLMs) have memorized plaintiffs' protected expression. Drawing on adversarial ML and copyright law, we show that these polarized positions dramatically oversimplify the relationship between memorization and copyright. To do so, we leverage a recent probabilistic extraction technique to extract pieces of the Books3 dataset from 13 open-weight LLMs. Through numerous experiments, we show that it's possible to extract substantial parts of at least some books from different LLMs. This is evidence that the LLMs have memorized the extracted text; this memorized content is copied inside the model parameters. But the results are complicated: the extent of memorization varies both by model and by book. With our specific experiments, we find that the largest LLMs don't memorize most books -- either in whole or in part. However, we also find that Llama 3.1 70B memorizes some books, like Harry Potter and 1984, almost entirely. We discuss why our results have significant implications for copyright cases, though not ones that unambiguously favor either side.
Compute-Optimal LLMs Provably Generalize Better With Scale
Apr 21, 2025



Why do larger language models generalize better? To investigate this question, we develop generalization bounds on the pretraining objective of large language models (LLMs) in the compute-optimal regime, as described by the Chinchilla scaling laws. We introduce a novel, fully empirical Freedman-type martingale concentration inequality that tightens existing bounds by accounting for the variance of the loss function. This generalization bound can be decomposed into three interpretable components: the number of parameters per token, the loss variance, and the quantization error at a fixed bitrate. As compute-optimal language models are scaled up, the number of parameters per data point remains constant; however, both the loss variance and the quantization error decrease, implying that larger models should have smaller generalization gaps. We examine why larger models tend to be more quantizable from an information theoretic perspective, showing that the rate at which they can integrate new information grows more slowly than their capacity on the compute-optimal frontier. From these findings we produce a scaling law for the generalization gap, with bounds that become predictably stronger with scale.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
Searching for Efficient Linear Layers over a Continuous Space of Structured Matrices
Oct 03, 2024



Dense linear layers are the dominant computational bottleneck in large neural networks, presenting a critical need for more efficient alternatives. Previous efforts focused on a small number of hand-crafted structured matrices and neglected to investigate whether these structures can surpass dense layers in terms of compute-optimal scaling laws when both the model size and training examples are optimally allocated. In this work, we present a unifying framework that enables searching among all linear operators expressible via an Einstein summation. This framework encompasses many previously proposed structures, such as low-rank, Kronecker, Tensor-Train, Block Tensor-Train (BTT), and Monarch, along with many novel structures. To analyze the framework, we develop a taxonomy of all such operators based on their computational and algebraic properties and show that differences in the compute-optimal scaling laws are mostly governed by a small number of variables that we introduce. Namely, a small $\omega$ (which measures parameter sharing) and large $\psi$ (which measures the rank) reliably led to better scaling laws. Guided by the insight that full-rank structures that maximize parameters per unit of compute perform the best, we propose BTT-MoE, a novel Mixture-of-Experts (MoE) architecture obtained by sparsifying computation in the BTT structure. In contrast to the standard sparse MoE for each entire feed-forward network, BTT-MoE learns an MoE in every single linear layer of the model, including the projection matrices in the attention blocks. We find BTT-MoE provides a substantial compute-efficiency gain over dense layers and standard MoE.
QTIP: Quantization with Trellises and Incoherence Processing
Jun 17, 2024



Post-training quantization (PTQ) reduces the memory footprint of LLMs by quantizing weights to low-precision datatypes. Since LLM inference is usually memory-bound, PTQ methods can improve inference throughput. Recent state-of-the-art PTQ approaches have converged on using vector quantization (VQ) to quantize multiple weights at once, which improves information utilization through better shaping. However, VQ requires a codebook with size exponential in the dimension. This limits current VQ-based PTQ works to low VQ dimensions ($\le 8$) that in turn limit quantization quality. Here, we introduce QTIP, which instead uses trellis coded quantization (TCQ) to achieve ultra-high-dimensional quantization. TCQ uses a stateful decoder that separates the codebook size from the bitrate and effective dimension. QTIP introduces a spectrum of lookup-only to computed lookup-free trellis codes designed for a hardware-efficient "bitshift" trellis structure; these codes achieve state-of-the-art results in both quantization quality and inference speed.
Gradient Descent on Logistic Regression with Non-Separable Data and Large Step Sizes
Jun 07, 2024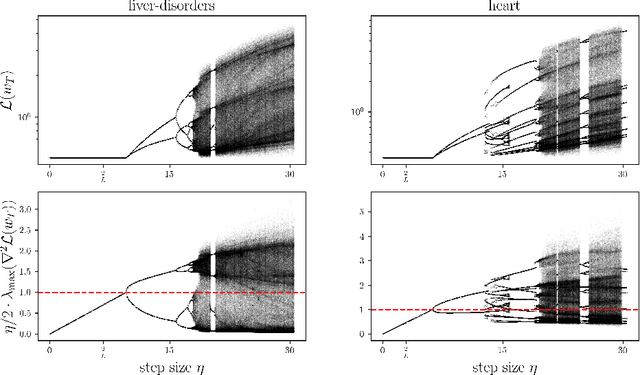
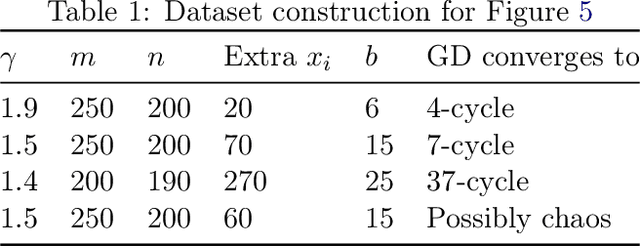
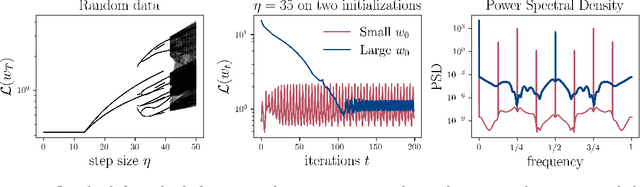
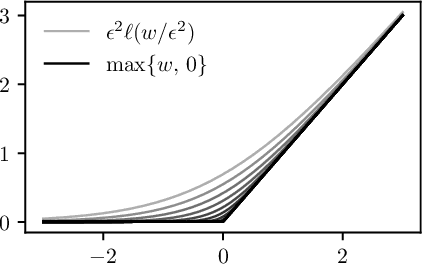
We study gradient descent (GD) dynamics on logistic regression problems with large, constant step sizes. For linearly-separable data, it is known that GD converges to the minimizer with arbitrarily large step sizes, a property which no longer holds when the problem is not separable. In fact, the behaviour can be much more complex -- a sequence of period-doubling bifurcations begins at the critical step size $2/\lambda$, where $\lambda$ is the largest eigenvalue of the Hessian at the solution. Using a smaller-than-critical step size guarantees convergence if initialized nearby the solution: but does this suffice globally? In one dimension, we show that a step size less than $1/\lambda$ suffices for global convergence. However, for all step sizes between $1/\lambda$ and the critical step size $2/\lambda$, one can construct a dataset such that GD converges to a stable cycle. In higher dimensions, this is actually possible even for step sizes less than $1/\lambda$. Our results show that although local convergence is guaranteed for all step sizes less than the critical step size, global convergence is not, and GD may instead converge to a cycle depending on the initialization.
Zeroth-Order Fine-Tuning of LLMs with Extreme Sparsity
Jun 05, 2024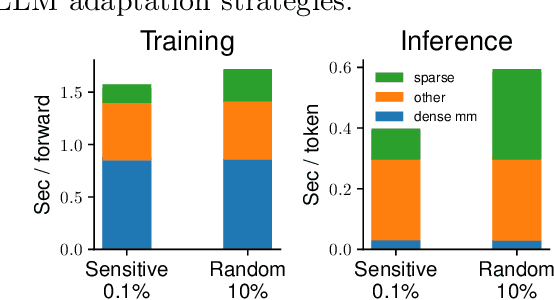
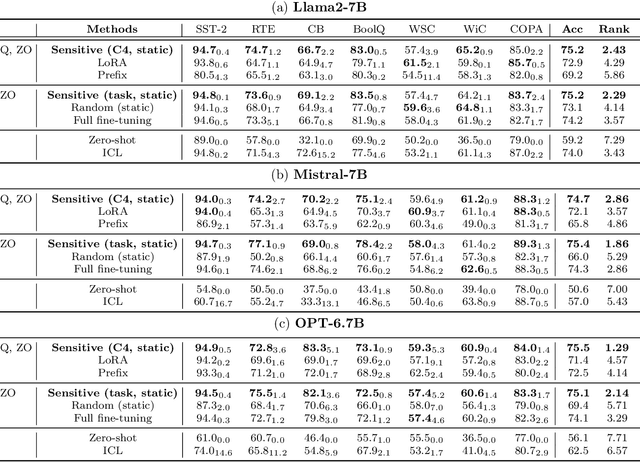
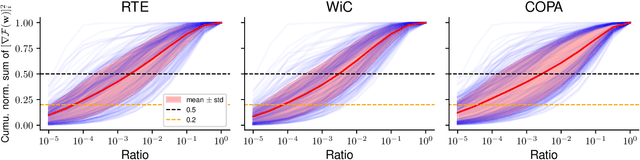
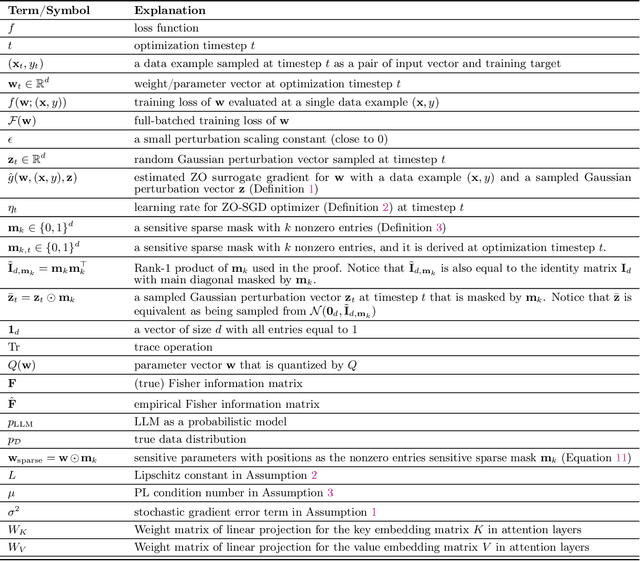
Zeroth-order optimization (ZO) is a memory-efficient strategy for fine-tuning Large Language Models using only forward passes. However, the application of ZO fine-tuning in memory-constrained settings such as mobile phones and laptops is still challenging since full precision forward passes are infeasible. In this study, we address this limitation by integrating sparsity and quantization into ZO fine-tuning of LLMs. Specifically, we investigate the feasibility of fine-tuning an extremely small subset of LLM parameters using ZO. This approach allows the majority of un-tuned parameters to be quantized to accommodate the constraint of limited device memory. Our findings reveal that the pre-training process can identify a set of "sensitive parameters" that can guide the ZO fine-tuning of LLMs on downstream tasks. Our results demonstrate that fine-tuning 0.1% sensitive parameters in the LLM with ZO can outperform the full ZO fine-tuning performance, while offering wall-clock time speedup. Additionally, we show that ZO fine-tuning targeting these 0.1% sensitive parameters, combined with 4 bit quantization, enables efficient ZO fine-tuning of an Llama2-7B model on a GPU device with less than 8 GiB of memory and notably reduced latency.