 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory
May 14, 2026Long-term agent memory is increasingly multimodal, yet existing evaluations rarely test whether agents preserve the visual evidence needed for later reasoning. In prior work, many visually grounded questions can be answered using only captions or textual traces, allowing answers to be inferred without preserving the fine-grained visual evidence. Meanwhile, harder cases that require reasoning over changing visual states are largely absent. Therefore, we introduce MemEye, a framework that evaluates memory capabilities from two dimensions: one measures the granularity of decisive visual evidence (from scene-level to pixel-level evidence), and the other measures how retrieved evidence must be used (from single evidence to evolutionary synthesis). Under this framework, we construct a new benchmark across 8 life-scenario tasks, with ablation-driven validation gates for assessing answerability, shortcut resistance, visual necessity, and reasoning structure. By evaluating 13 memory methods across 4 VLM backbones, we show that current architectures still struggle to preserve fine-grained visual details and reason about state changes over time. Our findings show that long-term multimodal memory depends on evidence routing, temporal tracking, and detail extraction.
TouchAnything: A Dataset and Framework for Bimanual Tactile Estimation from Egocentric Video
May 13, 2026Egocentric human video data, which captures rich human-environment interactions and can be collected at scale, has become a key driver of embodied intelligence research. However, existing egocentric datasets typically lack tactile sensing, a critical modality that provides direct cues about contact, force, and pressure in human-object interaction. Without such signals, models struggle to learn physically grounded representations of real-world interaction dynamics. While tactile sensors provide these cues, deploying high-quality tactile hardware at scale remains expensive and cumbersome. This raises a central question: can tactile feedback be inferred directly from visual observations, enabling scalable tactile supervision for egocentric video data and supporting physically grounded embodied learning? To enable research in this direction, we introduce EgoTouch, a large-scale multi-view egocentric dataset with dense tactile supervision for bimanual hand-object interaction. EgoTouch comprises 208 manipulation tasks spanning 1,891 episodes in diverse indoor and outdoor environments, with synchronized multi-view RGB (head-mounted egocentric and dual wrist-mounted cameras), bimanual 3D hand pose, and continuous pressure maps from wearable tactile sensors. Building on EgoTouch, we introduce TouchAnything, a baseline multi-view vision-to-touch prediction framework that uses the egocentric view as the primary input and flexibly leverages available wrist-mounted views at inference time. Experiments show that incorporating wrist-mounted views generally improves tactile prediction over egocentric-only input, achieving up to 5.0% relative improvement in Contact IoU and 6.1% relative improvement in Volumetric IoU. We will publicly release the dataset, code, and benchmark.
EgoTL: Egocentric Think-Aloud Chains for Long-Horizon Tasks
Apr 10, 2026Large foundation models have made significant advances in embodied intelligence, enabling synthesis and reasoning over egocentric input for household tasks. However, VLM-based auto-labeling is often noisy because the primary data sources lack accurate human action labels, chain-of-thought (CoT), and spatial annotations; these errors are amplified during long-horizon spatial instruction following. These issues stem from insufficient coverage of minute-long, daily household planning tasks and from inaccurate spatial grounding. As a result, VLM reasoning chains and world-model synthesis can hallucinate objects, skip steps, or fail to respect real-world physical attributes. To address these gaps, we introduce EgoTL. EgoTL builds a think-aloud capture pipeline for egocentric data. It uses a say-before-act protocol to record step-by-step goals and spoken reasoning with word-level timestamps, then calibrates physical properties with metric-scale spatial estimators, a memory-bank walkthrough for scene context, and clip-level tags for navigation instructions and detailed manipulation actions. With EgoTL, we are able to benchmark VLMs and World Models on six task dimensions from three layers and long-horizon generation over minute-long sequences across over 100 daily household tasks. We find that foundation models still fall short as egocentric assistants or open-world simulators. Finally, we finetune foundation models with human CoT aligned with metric labels on the training split of EgoTL, which improves long-horizon planning and reasoning, step-wise reasoning, instruction following, and spatial grounding.
VisualAD: Language-Free Zero-Shot Anomaly Detection via Vision Transformer
Mar 09, 2026Zero-shot anomaly detection (ZSAD) requires detecting and localizing anomalies without access to target-class anomaly samples. Mainstream methods rely on vision-language models (VLMs) such as CLIP: they build hand-crafted or learned prompt sets for normal and abnormal semantics, then compute image-text similarities for open-set discrimination. While effective, this paradigm depends on a text encoder and cross-modal alignment, which can lead to training instability and parameter redundancy. This work revisits the necessity of the text branch in ZSAD and presents VisualAD, a purely visual framework built on Vision Transformers. We introduce two learnable tokens within a frozen backbone to directly encode normality and abnormality. Through multi-layer self-attention, these tokens interact with patch tokens, gradually acquiring high-level notions of normality and anomaly while guiding patches to highlight anomaly-related cues. Additionally, we incorporate a Spatial-Aware Cross-Attention (SCA) module and a lightweight Self-Alignment Function (SAF): SCA injects fine-grained spatial information into the tokens, and SAF recalibrates patch features before anomaly scoring. VisualAD achieves state-of-the-art performance on 13 zero-shot anomaly detection benchmarks spanning industrial and medical domains, and adapts seamlessly to pretrained vision backbones such as the CLIP image encoder and DINOv2. Code: https://github.com/7HHHHH/VisualAD
A Replicate-and-Quantize Strategy for Plug-and-Play Load Balancing of Sparse Mixture-of-Experts LLMs
Feb 23, 2026Sparse Mixture-of-Experts (SMoE) architectures are increasingly used to scale large language models efficiently, delivering strong accuracy under fixed compute budgets. However, SMoE models often suffer from severe load imbalance across experts, where a small subset of experts receives most tokens while others are underutilized. Prior work has focused mainly on training-time solutions such as routing regularization or auxiliary losses, leaving inference-time behavior, which is critical for deployment, less explored. We present a systematic analysis of expert routing during inference and identify three findings: (i) load imbalance persists and worsens with larger batch sizes, (ii) selection frequency does not reliably reflect expert importance, and (iii) overall expert workload and importance can be estimated using a small calibration set. These insights motivate inference-time mechanisms that rebalance workloads without retraining or router modification. We propose Replicate-and-Quantize (R&Q), a training-free and near-lossless framework for dynamic workload rebalancing. In each layer, heavy-hitter experts are replicated to increase parallel capacity, while less critical experts and replicas are quantized to remain within the original memory budget. We also introduce a Load-Imbalance Score (LIS) to measure routing skew by comparing heavy-hitter load to an equal allocation baseline. Experiments across representative SMoE models and benchmarks show up to 1.4x reduction in imbalance with accuracy maintained within +/-0.6%, enabling more predictable and efficient inference.
FlashSchNet: Fast and Accurate Coarse-Grained Neural Network Molecular Dynamics
Feb 13, 2026Graph neural network (GNN) potentials such as SchNet improve the accuracy and transferability of molecular dynamics (MD) simulation by learning many-body interactions, but remain slower than classical force fields due to fragmented kernels and memory-bound pipelines that underutilize GPUs. We show that a missing principle is making GNN-MD IO-aware, carefully accounting for reads and writes between GPU high-bandwidth memory (HBM) and on-chip SRAM. We present FlashSchNet, an efficient and accurate IO-aware SchNet-style GNN-MD framework built on four techniques: (1) flash radial basis, which fuses pairwise distance computation, Gaussian basis expansion, and cosine envelope into a single tiled pass, computing each distance once and reusing it across all basis functions; (2) flash message passing, which fuses cutoff, neighbor gather, filter multiplication, and reduction to avoid materializing edge tensors in HBM; (3) flash aggregation, which reformulates scatter-add via CSR segment reduce, reducing atomic writes by a factor of feature dimension and enabling contention-free accumulation in both forward and backward passes; (4) channel-wise 16-bit quantization that exploits the low per-channel dynamic range in SchNet MLP weights to further improve throughput with negligible accuracy loss. On a single NVIDIA RTX PRO 6000, FlashSchNet achieves 1000 ns/day aggregate simulation throughput over 64 parallel replicas on coarse-grained (CG) protein containing 269 beads (6.5x faster than CGSchNet baseline with 80% reduction of peak memory), surpassing classical force fields (e.g. MARTINI) while retaining SchNet-level accuracy and transferability.
PaperScout: An Autonomous Agent for Academic Paper Search with Process-Aware Sequence-Level Policy Optimization
Jan 15, 2026Academic paper search is a fundamental task in scientific research, yet most existing approaches rely on rigid, predefined workflows that struggle with complex, conditional queries. To address this limitation, we propose PaperScout, an autonomous agent that reformulates paper search as a sequential decision-making process. Unlike static workflows, PaperScout dynamically decides whether, when, and how to invoke search and expand tools based on accumulated retrieval context. However, training such agents presents a fundamental challenge: standard reinforcement learning methods, typically designed for single-turn tasks, suffer from a granularity mismatch when applied to multi-turn agentic tasks, where token-level optimization diverges from the granularity of sequence-level interactions, leading to noisy credit assignment. We introduce Proximal Sequence Policy Optimization (PSPO), a process-aware, sequence-level policy optimization method that aligns optimization with agent-environment interaction. Comprehensive experiments on both synthetic and real-world benchmarks demonstrate that PaperScout significantly outperforms strong workflow-driven and RL baselines in both recall and relevance, validating the effectiveness of our adaptive agentic framework and optimization strategy.
EntroCoT: Enhancing Chain-of-Thought via Adaptive Entropy-Guided Segmentation
Jan 08, 2026Chain-of-Thought (CoT) prompting has significantly enhanced the mathematical reasoning capabilities of Large Language Models. We find existing fine-tuning datasets frequently suffer from the "answer right but reasoning wrong" probelm, where correct final answers are derived from hallucinated, redundant, or logically invalid intermediate steps. This paper proposes EntroCoT, a unified framework for automatically identifying and refining low-quality CoT supervision traces. EntroCoT first proposes an entropy-based mechanism to segment the reasoning trace into multiple steps at uncertain junctures, and then introduces a Monte Carlo rollout-based mechanism to evaluate the marginal contribution of each step. By accurately filtering deceptive reasoning samples, EntroCoT constructs a high-quality dataset where every intermediate step in each reasoning trace facilitates the final answer. Extensive experiments on mathematical benchmarks demonstrate that fine-tuning on the subset constructed by EntroCoT consistently outperforms the baseslines of full-dataset supervision.
Towards Stable and Structured Time Series Generation with Perturbation-Aware Flow Matching
Nov 18, 2025
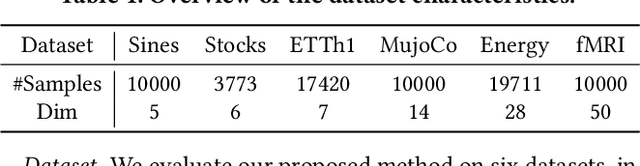
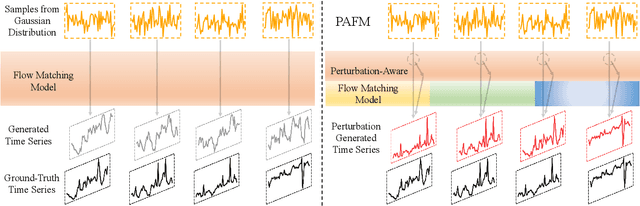
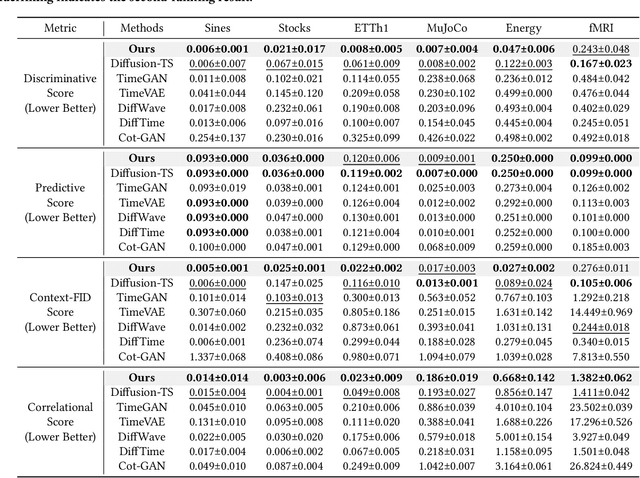
Time series generation is critical for a wide range of applications, which greatly supports downstream analytical and decision-making tasks. However, the inherent temporal heterogeneous induced by localized perturbations present significant challenges for generating structurally consistent time series. While flow matching provides a promising paradigm by modeling temporal dynamics through trajectory-level supervision, it fails to adequately capture abrupt transitions in perturbed time series, as the use of globally shared parameters constrains the velocity field to a unified representation. To address these limitations, we introduce \textbf{PAFM}, a \textbf{P}erturbation-\textbf{A}ware \textbf{F}low \textbf{M}atching framework that models perturbed trajectories to ensure stable and structurally consistent time series generation. The framework incorporates perturbation-guided training to simulate localized disturbances and leverages a dual-path velocity field to capture trajectory deviations under perturbation, enabling refined modeling of perturbed behavior to enhance the structural coherence. In order to further improve sensitivity to trajectory perturbations while enhancing expressiveness, a mixture-of-experts decoder with flow routing dynamically allocates modeling capacity in response to different trajectory dynamics. Extensive experiments on both unconditional and conditional generation tasks demonstrate that PAFM consistently outperforms strong baselines. Code is available at https://anonymous.4open.science/r/PAFM-03B2.
Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning
Nov 18, 2025Large Language Models (LLMs) are increasingly being explored for building Agents capable of active environmental interaction (e.g., via tool use) to solve complex problems. Reinforcement Learning (RL) is considered a key technology with significant potential for training such Agents; however, the effective application of RL to LLM Agents is still in its nascent stages and faces considerable challenges. Currently, this emerging field lacks in-depth exploration into RL approaches specifically tailored for the LLM Agent context, alongside a scarcity of flexible and easily extensible training frameworks designed for this purpose. To help advance this area, this paper first revisits and clarifies Reinforcement Learning methodologies for LLM Agents by systematically extending the Markov Decision Process (MDP) framework to comprehensively define the key components of an LLM Agent. Secondly, we introduce Agent-R1, a modular, flexible, and user-friendly training framework for RL-based LLM Agents, designed for straightforward adaptation across diverse task scenarios and interactive environments. We conducted experiments on Multihop QA benchmark tasks, providing initial validation for the effectiveness of our proposed methods and framework.