 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reducible Uncertainty Modeling for Reliable Large Language Model Agents
Feb 04, 2026Uncertainty quantification (UQ) for large language models (LLMs) is a key building block for safety guardrails of daily LLM applications. Yet, even as LLM agents are increasingly deployed in highly complex tasks, most UQ research still centers on single-turn question-answering. We argue that UQ research must shift to realistic settings with interactive agents, and that a new principled framework for agent UQ is needed. This paper presents the first general formulation of agent UQ that subsumes broad classes of existing UQ setups. Under this formulation, we show that prior works implicitly treat LLM UQ as an uncertainty accumulation process, a viewpoint that breaks down for interactive agents in an open world. In contrast, we propose a novel perspective, a conditional uncertainty reduction process, that explicitly models reducible uncertainty over an agent's trajectory by highlighting "interactivity" of actions. From this perspective, we outline a conceptual framework to provide actionable guidance for designing UQ in LLM agent setups. Finally, we conclude with practical implications of the agent UQ in frontier LLM development and domain-specific applications, as well as open remaining problems.
Scaling Reasoning Hop Exposes Weaknesses: Demystifying and Improving Hop Generalization in Large Language Models
Jan 29, 2026Chain-of-thought (CoT) reasoning has become the standard paradigm for enabling Large Language Models (LLMs) to solve complex problems. However, recent studies reveal a sharp performance drop in reasoning hop generalization scenarios, where the required number of reasoning steps exceeds training distributions while the underlying algorithm remains unchanged. The internal mechanisms driving this failure remain poorly understood. In this work, we conduct a systematic study on tasks from multiple domains, and find that errors concentrate at token positions of a few critical error types, rather than being uniformly distributed. Closer inspection reveals that these token-level erroneous predictions stem from internal competition mechanisms: certain attention heads, termed erroneous processing heads (ep heads), tip the balance by amplifying incorrect reasoning trajectories while suppressing correct ones. Notably, removing individual ep heads during inference can often restore the correct predictions. Motivated by these insights, we propose test-time correction of reasoning, a lightweight intervention method that dynamically identifies and deactivates ep heads in the reasoning process. Extensive experiments across different tasks and LLMs show that it consistently improves reasoning hop generalization, highlighting both its effectiveness and potential.
Reasoning Is All You Need for Urban Planning AI
Nov 07, 2025AI has proven highly successful at urban planning analysis -- learning patterns from data to predict future conditions. The next frontier is AI-assisted decision-making: agents that recommend sites, allocate resources, and evaluate trade-offs while reasoning transparently about constraints and stakeholder values. Recent breakthroughs in reasoning AI -- CoT prompting, ReAct, and multi-agent collaboration frameworks -- now make this vision achievable. This position paper presents the Agentic Urban Planning AI Framework for reasoning-capable planning agents that integrates three cognitive layers (Perception, Foundation, Reasoning) with six logic components (Analysis, Generation, Verification, Evaluation, Collaboration, Decision) through a multi-agents collaboration framework. We demonstrate why planning decisions require explicit reasoning capabilities that are value-based (applying normative principles), rule-grounded (guaranteeing constraint satisfaction), and explainable (generating transparent justifications) -- requirements that statistical learning alone cannot fulfill. We compare reasoning agents with statistical learning, present a comprehensive architecture with benchmark evaluation metrics, and outline critical research challenges. This framework shows how AI agents can augment human planners by systematically exploring solution spaces, verifying regulatory compliance, and deliberating over trade-offs transparently -- not replacing human judgment but amplifying it with computational reasoning capabilities.
I-DCCRN-VAE: An Improved Deep Representation Learning Framework for Complex VAE-based Single-channel Speech Enhancement
Oct 14, 2025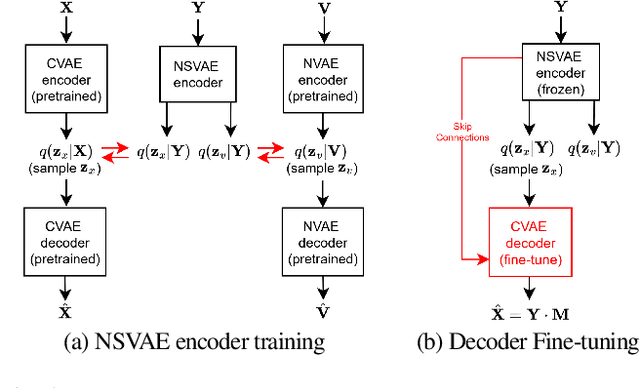
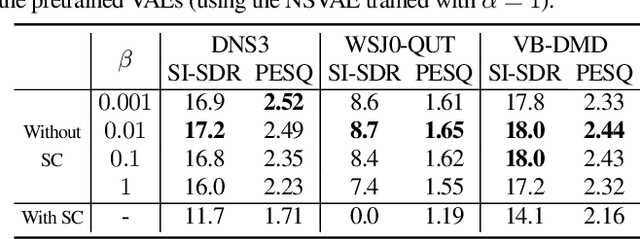

Recently, a complex variational autoencoder (VAE)-based single-channel speech enhancement system based on the DCCRN architecture has been proposed. In this system, a noise suppression VAE (NSVAE) learns to extract clean speech representations from noisy speech using pretrained clean speech and noise VAEs with skip connections. In this paper, we improve DCCRN-VAE by incorporating three key modifications: 1) removing the skip connections in the pretrained VAEs to encourage more informative speech and noise latent representations; 2) using $\beta$-VAE in pretraining to better balance reconstruction and latent space regularization; and 3) a NSVAE generating both speech and noise latent representations. Experiments show that the proposed system achieves comparable performance as the DCCRN and DCCRN-VAE baselines on the matched DNS3 dataset but outperforms the baselines on mismatched datasets (WSJ0-QUT, Voicebank-DEMEND), demonstrating improved generalization ability. In addition, an ablation study shows that a similar performance can be achieved with classical fine-tuning instead of adversarial training, resulting in a simpler training pipeline.
Summarize-Exemplify-Reflect: Data-driven Insight Distillation Empowers LLMs for Few-shot Tabular Classification
Aug 29, 2025Recent studies show the promise of large language models (LLMs) for few-shot tabular classification but highlight challenges due to the variability in structured data. To address this, we propose distilling data into actionable insights to enable robust and effective classification by LLMs. Drawing inspiration from human learning processes, we introduce InsightTab, an insight distillation framework guided by principles of divide-and-conquer, easy-first, and reflective learning. Our approach integrates rule summarization, strategic exemplification, and insight reflection through deep collaboration between LLMs and data modeling techniques. The obtained insights enable LLMs to better align their general knowledge and capabilities with the particular requirements of specific tabular tasks. We extensively evaluate InsightTab on nine datasets. The results demonstrate consistent improvement over state-of-the-art methods. Ablation studies further validate the principle-guided distillation process, while analyses emphasize InsightTab's effectiveness in leveraging labeled data and managing bias.
CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Aug 25, 2025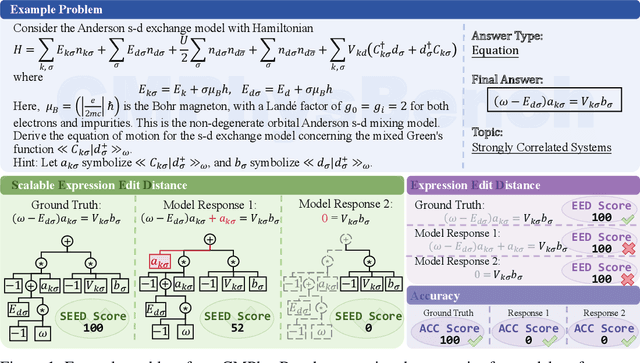
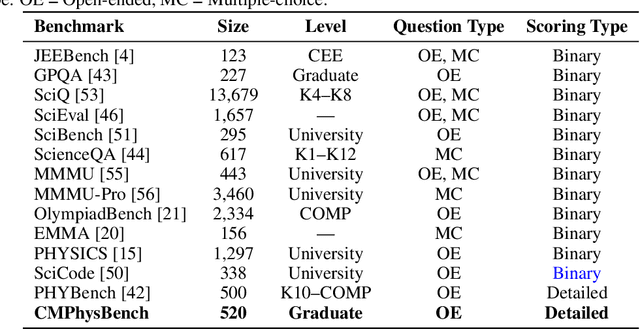
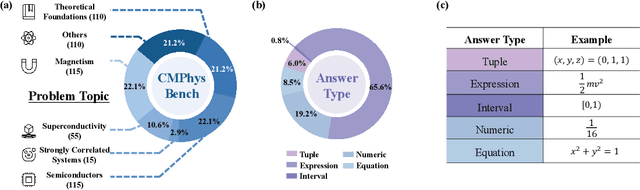

We introduce CMPhysBench, designed to assess the proficiency of Large Language Models (LLMs) in Condensed Matter Physics, as a novel Benchmark. CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions. Meanwhile, leveraging tree-based representations of expressions, we introduce the Scalable Expression Edit Distance (SEED) score, which provides fine-grained (non-binary) partial credit and yields a more accurate assessment of similarity between prediction and ground-truth. Our results show that even the best models, Grok-4, reach only 36 average SEED score and 28% accuracy on CMPhysBench, underscoring a significant capability gap, especially for this practical and frontier domain relative to traditional physics. The code anddataset are publicly available at https://github.com/CMPhysBench/CMPhysBench.
Mol-R1: Towards Explicit Long-CoT Reasoning in Molecule Discovery
Aug 11, 2025Large language models (LLMs), especially Explicit Long Chain-of-Thought (CoT) reasoning models like DeepSeek-R1 and QWQ, have demonstrated powerful reasoning capabilities, achieving impressive performance in commonsense reasoning and mathematical inference. Despite their effectiveness, Long-CoT reasoning models are often criticized for their limited ability and low efficiency in knowledge-intensive domains such as molecule discovery. Success in this field requires a precise understanding of domain knowledge, including molecular structures and chemical principles, which is challenging due to the inherent complexity of molecular data and the scarcity of high-quality expert annotations. To bridge this gap, we introduce Mol-R1, a novel framework designed to improve explainability and reasoning performance of R1-like Explicit Long-CoT reasoning LLMs in text-based molecule generation. Our approach begins with a high-quality reasoning dataset curated through Prior Regulation via In-context Distillation (PRID), a dedicated distillation strategy to effectively generate paired reasoning traces guided by prior regulations. Building upon this, we introduce MoIA, Molecular Iterative Adaptation, a sophisticated training strategy that iteratively combines Supervised Fine-tuning (SFT) with Reinforced Policy Optimization (RPO), tailored to boost the reasoning performance of R1-like reasoning models for molecule discovery. Finally, we examine the performance of Mol-R1 in the text-based molecule reasoning generation task, showing superior performance against existing baselines.
Investigation of Speech and Noise Latent Representations in Single-channel VAE-based Speech Enhancement
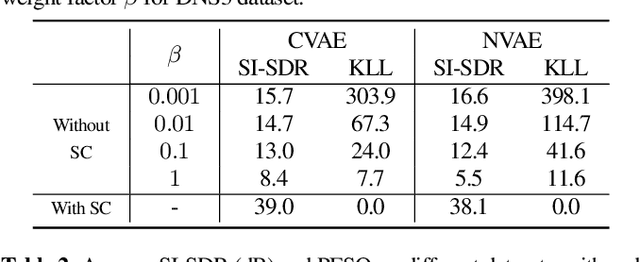
Aug 07, 2025Recently, a variational autoencoder (VAE)-based single-channel speech enhancement system using Bayesian permutation training has been proposed, which uses two pretrained VAEs to obtain latent representations for speech and noise. Based on these pretrained VAEs, a noisy VAE learns to generate speech and noise latent representations from noisy speech for speech enhancement. Modifying the pretrained VAE loss terms affects the pretrained speech and noise latent representations. In this paper, we investigate how these different representations affect speech enhancement performance. Experiments on the DNS3, WSJ0-QUT, and VoiceBank-DEMAND datasets show that a latent space where speech and noise representations are clearly separated significantly improves performance over standard VAEs, which produce overlapping speech and noise representations.
Are LLMs Reliable Translators of Logical Reasoning Across Lexically Diversified Contexts?
Jun 05, 2025Neuro-symbolic approaches combining large language models (LLMs) with solvers excels in logical reasoning problems need long reasoning chains. In this paradigm, LLMs serve as translators, converting natural language reasoning problems into formal logic formulas. Then reliable symbolic solvers return correct solutions. Despite their success, we find that LLMs, as translators, struggle to handle lexical diversification, a common linguistic phenomenon, indicating that LLMs as logic translators are unreliable in real-world scenarios. Moreover, existing logical reasoning benchmarks lack lexical diversity, failing to challenge LLMs' ability to translate such text and thus obscuring this issue. In this work, we propose SCALe, a benchmark designed to address this significant gap through **logic-invariant lexical diversification**. By using LLMs to transform original benchmark datasets into lexically diversified but logically equivalent versions, we evaluate LLMs' ability to consistently map diverse expressions to uniform logical symbols on these new datasets. Experiments using SCALe further confirm that current LLMs exhibit deficiencies in this capability. Building directly on the deficiencies identified through our benchmark, we propose a new method, MenTaL, to address this limitation. This method guides LLMs to first construct a table unifying diverse expressions before performing translation. Applying MenTaL through in-context learning and supervised fine-tuning (SFT) significantly improves the performance of LLM translators on lexically diversified text. Our code is now available at https://github.com/wufeiwuwoshihua/LexicalDiver.
Benchmarking Poisoning Attacks against Retrieval-Augmented Generation
May 24, 2025


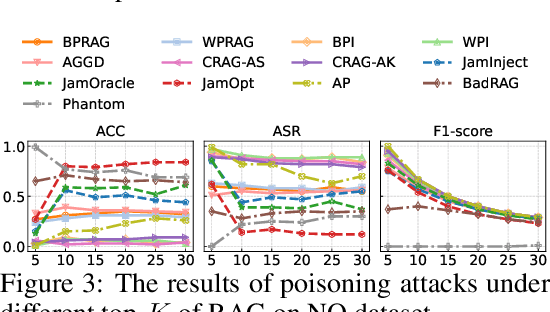
Retrieval-Augmented Generation (RAG) has proven effective in mitigating hallucinations in large language models by incorporating external knowledge during inference. However, this integration introduces new security vulnerabilities, particularly to poisoning attacks. Although prior work has explored various poisoning strategies, a thorough assessment of their practical threat to RAG systems remains missing. To address this gap, we propose the first comprehensive benchmark framework for evaluating poisoning attacks on RAG. Our benchmark covers 5 standard question answering (QA) datasets and 10 expanded variants, along with 13 poisoning attack methods and 7 defense mechanisms, representing a broad spectrum of existing techniques. Using this benchmark, we conduct a comprehensive evaluation of all included attacks and defenses across the full dataset spectrum. Our findings show that while existing attacks perform well on standard QA datasets, their effectiveness drops significantly on the expanded versions. Moreover, our results demonstrate that various advanced RAG architectures, such as sequential, branching, conditional, and loop RAG, as well as multi-turn conversational RAG, multimodal RAG systems, and RAG-based LLM agent systems, remain susceptible to poisoning attacks. Notably, current defense techniques fail to provide robust protection, underscoring the pressing need for more resilient and generalizable defense strategies.