 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Social Identity Bias in Chinese LLMs with Gendered Pronouns and Social Groups
Oct 08, 2025Large language models (LLMs) are increasingly deployed in user-facing applications, raising concerns about their potential to reflect and amplify social biases. We investigate social identity framing in Chinese LLMs using Mandarin-specific prompts across ten representative Chinese LLMs, evaluating responses to ingroup ("We") and outgroup ("They") framings, and extending the setting to 240 social groups salient in the Chinese context. To complement controlled experiments, we further analyze Chinese-language conversations from a corpus of real interactions between users and chatbots. Across models, we observe systematic ingroup-positive and outgroup-negative tendencies, which are not confined to synthetic prompts but also appear in naturalistic dialogue, indicating that bias dynamics might strengthen in real interactions. Our study provides a language-aware evaluation framework for Chinese LLMs, demonstrating that social identity biases documented in English generalize cross-linguistically and intensify in user-facing contexts.
A Survey of Models for Cognitive Diagnosis: New Developments and Future Directions
Jul 07, 2024



Cognitive diagnosis has been developed for decades as an effective measurement tool to evaluate human cognitive status such as ability level and knowledge mastery. It has been applied to a wide range of fields including education, sport, psychological diagnosis, etc. By providing better awareness of cognitive status, it can serve as the basis for personalized services such as well-designed medical treatment, teaching strategy and vocational training. This paper aims to provide a survey of current models for cognitive diagnosis, with more attention on new developments using machine learning-based methods. By comparing the model structures, parameter estimation algorithms, model evaluation methods and applications, we provide a relatively comprehensive review of the recent trends in cognitive diagnosis models. Further, we discuss future directions that are worthy of exploration. In addition, we release two Python libraries: EduData for easy access to some relevant public datasets we have collected, and EduCDM that implements popular CDMs to facilitate both applications and research purposes.
PertEval: Unveiling Real Knowledge Capacity of LLMs with Knowledge-Invariant Perturbations
May 30, 2024
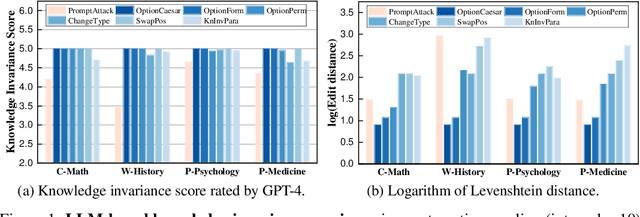

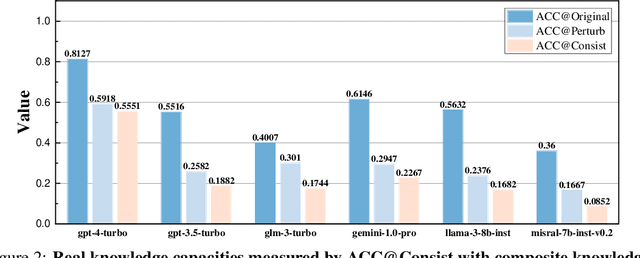
Expert-designed close-ended benchmarks serve as vital tools in assessing the knowledge capacity of large language models (LLMs). Despite their widespread use, concerns have mounted regarding their reliability due to limited test scenarios and an unavoidable risk of data contamination. To rectify this, we present PertEval, a toolkit devised for in-depth probing of LLMs' knowledge capacity through knowledge-invariant perturbations. These perturbations employ human-like restatement techniques to generate on-the-fly test samples from static benchmarks, meticulously retaining knowledge-critical content while altering irrelevant details. Our toolkit further includes a suite of transition analyses that compare performance on raw vs. perturbed test sets to precisely assess LLMs' genuine knowledge capacity. Six state-of-the-art LLMs are re-evaluated using PertEval. Results reveal significantly inflated performance of the LLMs on raw benchmarks, including an absolute 21% overestimation for GPT-4. Additionally, through a nuanced response pattern analysis, we discover that PertEval retains LLMs' uncertainty to specious knowledge, potentially being resolved through rote memorization and leading to inflated performance. We also find that the detailed transition analyses by PertEval could illuminate weaknesses in existing LLMs' knowledge mastery and guide the development of refinement. Given these insights, we posit that PertEval can act as an essential tool that, when applied alongside any close-ended benchmark, unveils the true knowledge capacity of LLMs, marking a significant step toward more trustworthy LLM evaluation.
Survey of Computerized Adaptive Testing: A Machine Learning Perspective
Apr 05, 2024Computerized Adaptive Testing (CAT) provides an efficient and tailored method for assessing the proficiency of examinees, by dynamically adjusting test questions based on their performance. Widely adopted across diverse fields like education, healthcare, sports, and sociology, CAT has revolutionized testing practices. While traditional methods rely on psychometrics and statistics, the increasing complexity of large-scale testing has spurred the integration of machine learning techniques. This paper aims to provide a machine learning-focused survey on CAT, presenting a fresh perspective on this adaptive testing method. By examining the test question selection algorithm at the heart of CAT's adaptivity, we shed light on its functionality. Furthermore, we delve into cognitive diagnosis models, question bank construction, and test control within CAT, exploring how machine learning can optimize these components. Through an analysis of current methods, strengths, limitations, and challenges, we strive to develop robust, fair, and efficient CAT systems. By bridging psychometric-driven CAT research with machine learning, this survey advocates for a more inclusive and interdisciplinary approach to the future of adaptive testing.