 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LLM Already Knows: Estimating LLM-Perceived Question Difficulty via Hidden Representations
Sep 16, 2025Estimating the difficulty of input questions as perceived by large language models (LLMs) is essential for accurate performance evaluation and adaptive inference. Existing methods typically rely on repeated response sampling, auxiliary models, or fine-tuning the target model itself, which may incur substantial computational costs or compromise generality. In this paper, we propose a novel approach for difficulty estimation that leverages only the hidden representations produced by the target LLM. We model the token-level generation process as a Markov chain and define a value function to estimate the expected output quality given any hidden state. This allows for efficient and accurate difficulty estimation based solely on the initial hidden state, without generating any output tokens. Extensive experiments across both textual and multimodal tasks demonstrate that our method consistently outperforms existing baselines in difficulty estimation. Moreover, we apply our difficulty estimates to guide adaptive reasoning strategies, including Self-Consistency, Best-of-N, and Self-Refine, achieving higher inference efficiency with fewer generated tokens.
On Evaluating the Poisoning Robustness of Federated Learning under Local Differential Privacy
Sep 05, 2025Federated learning (FL) combined with local differential privacy (LDP) enables privacy-preserving model training across decentralized data sources. However, the decentralized data-management paradigm leaves LDPFL vulnerable to participants with malicious intent. The robustness of LDPFL protocols, particularly against model poisoning attacks (MPA), where adversaries inject malicious updates to disrupt global model convergence, remains insufficiently studied. In this paper, we propose a novel and extensible model poisoning attack framework tailored for LDPFL settings. Our approach is driven by the objective of maximizing the global training loss while adhering to local privacy constraints. To counter robust aggregation mechanisms such as Multi-Krum and trimmed mean, we develop adaptive attacks that embed carefully crafted constraints into a reverse training process, enabling evasion of these defenses. We evaluate our framework across three representative LDPFL protocols, three benchmark datasets, and two types of deep neural networks. Additionally, we investigate the influence of data heterogeneity and privacy budgets on attack effectiveness. Experimental results demonstrate that our adaptive attacks can significantly degrade the performance of the global model, revealing critical vulnerabilities and highlighting the need for more robust LDPFL defense strategies against MPA. Our code is available at https://github.com/ZiJW/LDPFL-Attack
Model Developmental Safety: A Safety-Centric Method and Applications in Vision-Language Models
Oct 13, 2024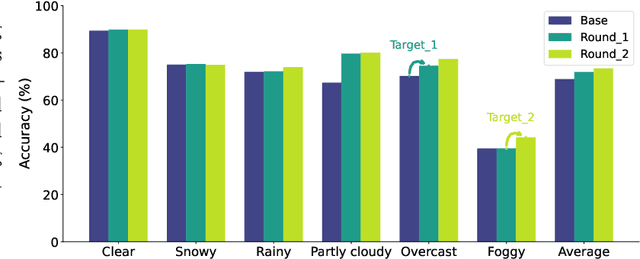
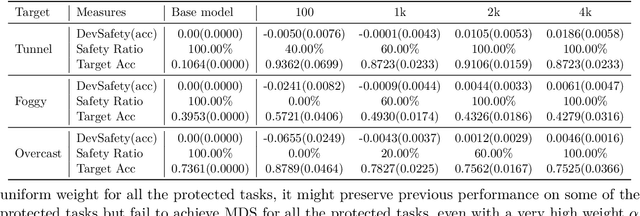
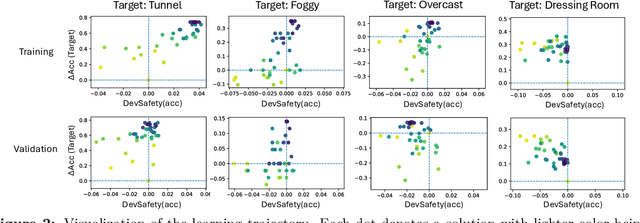
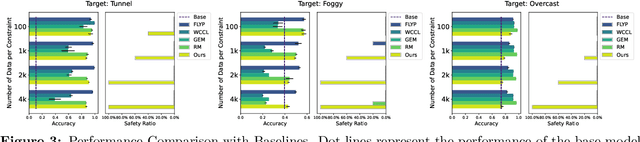
In the real world, a learning-enabled system usually undergoes multiple cycles of model development to enhance the system's ability to handle difficult or emerging tasks. This continual model development process raises a significant issue that the model development for acquiring new or improving existing capabilities may inadvertently lose capabilities of the old model, also known as catastrophic forgetting. Existing continual learning studies focus on mitigating catastrophic forgetting by trading off performance on previous tasks and new tasks to ensure good average performance. However, they are inadequate for many applications especially in safety-critical domains, as failure to strictly preserve the performance of the old model not only introduces safety risks and uncertainties but also imposes substantial expenses in the re-improving and re-validation of existing properties. To address this issue, we introduce model developmental safety as a guarantee of a learning system such that in the model development process the new model should strictly preserve the existing protected capabilities of the old model while improving its performance on target tasks. To ensure the model developmental safety, we present a safety-centric framework by formulating the model developmental safety as data-dependent constraints. Under this framework, we study how to develop a pretrained vision-language model (aka the CLIP model) for acquiring new capabilities or improving existing capabilities of image classification. We propose an efficient constrained optimization algorithm with theoretical guarantee and use its insights to finetune a CLIP model with task-dependent heads for promoting the model developmental safety. Our experiments on improving vision perception capabilities on autonomous driving and scene recognition datasets demonstrate the efficacy of the proposed approach.
Detecting Dataset Abuse in Fine-Tuning Stable Diffusion Models for Text-to-Image Synthesis
Sep 27, 2024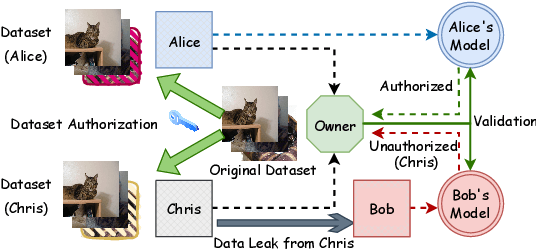
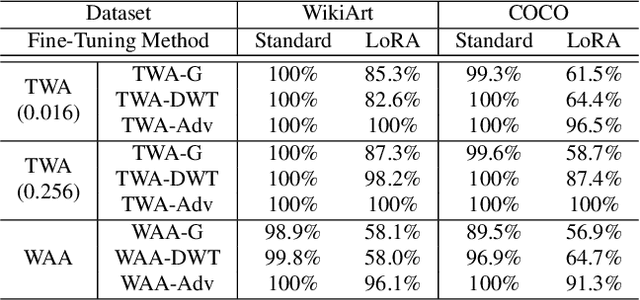
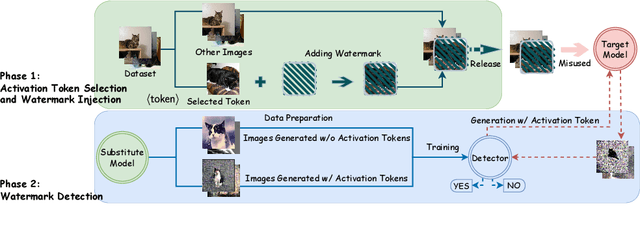
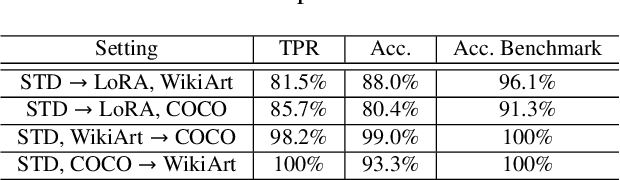
Text-to-image synthesis has become highly popular for generating realistic and stylized images, often requiring fine-tuning generative models with domain-specific datasets for specialized tasks. However, these valuable datasets face risks of unauthorized usage and unapproved sharing, compromising the rights of the owners. In this paper, we address the issue of dataset abuse during the fine-tuning of Stable Diffusion models for text-to-image synthesis. We present a dataset watermarking framework designed to detect unauthorized usage and trace data leaks. The framework employs two key strategies across multiple watermarking schemes and is effective for large-scale dataset authorization. Extensive experiments demonstrate the framework's effectiveness, minimal impact on the dataset (only 2% of the data required to be modified for high detection accuracy), and ability to trace data leaks. Our results also highlight the robustness and transferability of the framework, proving its practical applicability in detecting dataset abuse.
A Survey of Models for Cognitive Diagnosis: New Developments and Future Directions
Jul 07, 2024



Cognitive diagnosis has been developed for decades as an effective measurement tool to evaluate human cognitive status such as ability level and knowledge mastery. It has been applied to a wide range of fields including education, sport, psychological diagnosis, etc. By providing better awareness of cognitive status, it can serve as the basis for personalized services such as well-designed medical treatment, teaching strategy and vocational training. This paper aims to provide a survey of current models for cognitive diagnosis, with more attention on new developments using machine learning-based methods. By comparing the model structures, parameter estimation algorithms, model evaluation methods and applications, we provide a relatively comprehensive review of the recent trends in cognitive diagnosis models. Further, we discuss future directions that are worthy of exploration. In addition, we release two Python libraries: EduData for easy access to some relevant public datasets we have collected, and EduCDM that implements popular CDMs to facilitate both applications and research purposes.
The Fire Thief Is Also the Keeper: Balancing Usability and Privacy in Prompts
Jun 20, 2024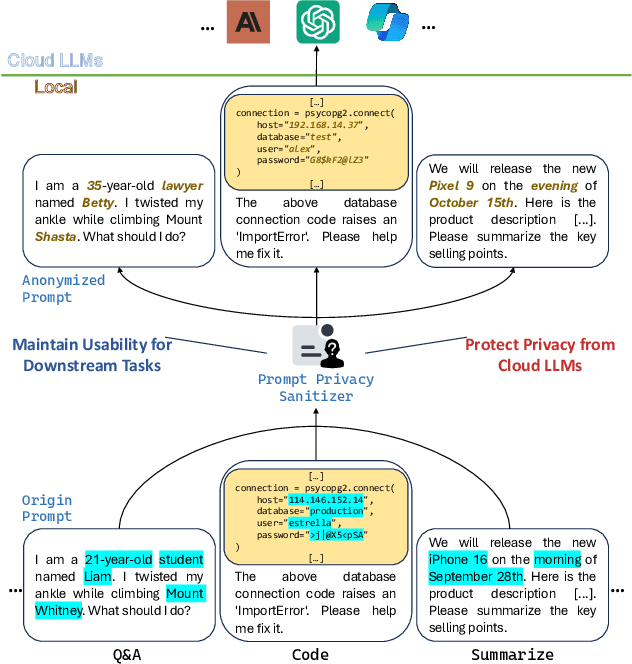
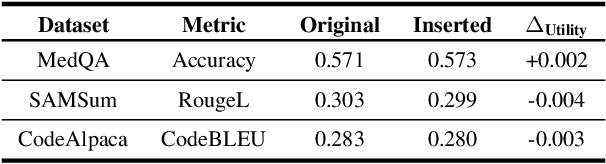
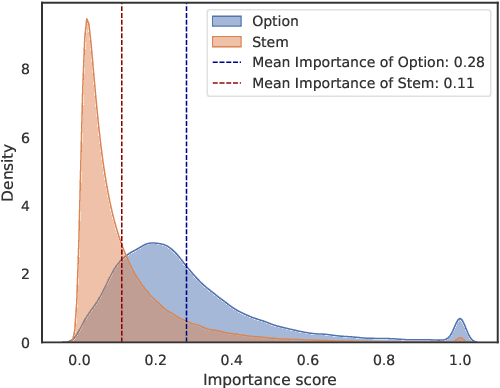
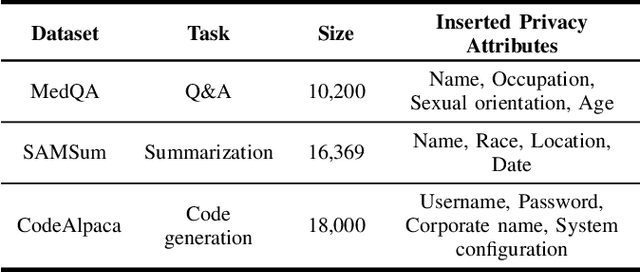
The rapid adoption of online chatbots represents a significant advancement in artificial intelligence. However, this convenience brings considerable privacy concerns, as prompts can inadvertently contain sensitive information exposed to large language models (LLMs). Limited by high computational costs, reduced task usability, and excessive system modifications, previous works based on local deployment, embedding perturbation, and homomorphic encryption are inapplicable to online prompt-based LLM applications. To address these issues, this paper introduces Prompt Privacy Sanitizer (i.e., ProSan), an end-to-end prompt privacy protection framework that can produce anonymized prompts with contextual privacy removed while maintaining task usability and human readability. It can also be seamlessly integrated into the online LLM service pipeline. To achieve high usability and dynamic anonymity, ProSan flexibly adjusts its protection targets and strength based on the importance of the words and the privacy leakage risk of the prompts. Additionally, ProSan is capable of adapting to diverse computational resource conditions, ensuring privacy protection even for mobile devices with limited computing power. Our experiments demonstrate that ProSan effectively removes private information across various tasks, including question answering, text summarization, and code generation, with minimal reduction in task performance.
Deep MAGSAC++
Nov 28, 2021


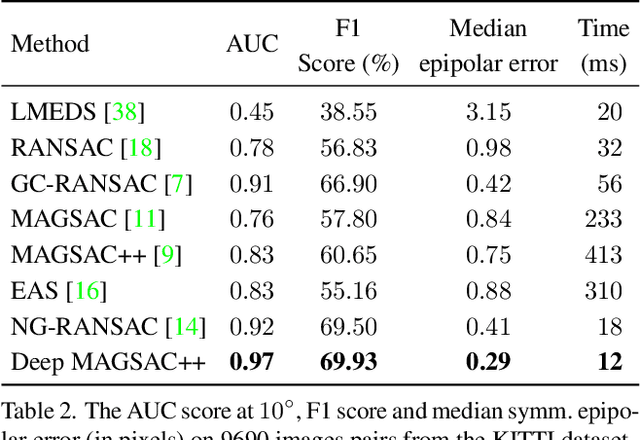
We propose Deep MAGSAC++ combining the advantages of traditional and deep robust estimators. We introduce a novel loss function that exploits the orientation and scale from partially affine covariant features, e.g., SIFT, in a geometrically justifiable manner. The new loss helps in learning higher-order information about the underlying scene geometry. Moreover, we propose a new sampler for RANSAC that always selects the sample with the highest probability of consisting only of inliers. After every unsuccessful iteration, the probabilities are updated in a principled way via a Bayesian approach. The prediction of the deep network is exploited as prior inside the sampler. Benefiting from the new loss, the proposed sampler, and a number of technical advancements, Deep MAGSAC++ is superior to the state-of-the-art both in terms of accuracy and run-time on thousands of image pairs from publicly available datasets for essential and fundamental matrix estimation.
QuesNet: A Unified Representation for Heterogeneous Test Questions
May 27, 2019
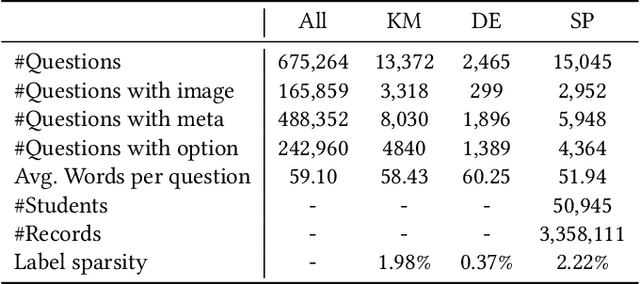
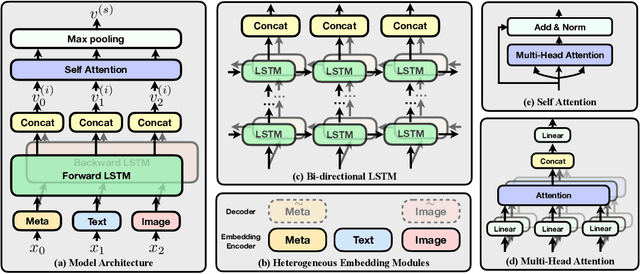
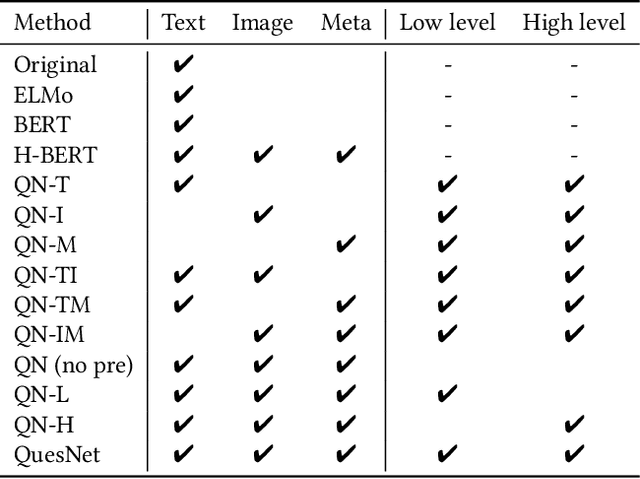
Understanding learning materials (e.g. test questions) is a crucial issue in online learning systems, which can promote many applications in education domain. Unfortunately, many supervised approaches suffer from the problem of scarce human labeled data, whereas abundant unlabeled resources are highly underutilized. To alleviate this problem, an effective solution is to use pre-trained representations for question understanding. However, existing pre-training methods in NLP area are infeasible to learn test question representations due to several domain-specific characteristics in education. First, questions usually comprise of heterogeneous data including content text, images and side information. Second, there exists both basic linguistic information as well as domain logic and knowledge. To this end, in this paper, we propose a novel pre-training method, namely QuesNet, for comprehensively learning question representations. Specifically, we first design a unified framework to aggregate question information with its heterogeneous inputs into a comprehensive vector. Then we propose a two-level hierarchical pre-training algorithm to learn better understanding of test questions in an unsupervised way. Here, a novel holed language model objective is developed to extract low-level linguistic features, and a domain-oriented objective is proposed to learn high-level logic and knowledge. Moreover, we show that QuesNet has good capability of being fine-tuned in many question-based tasks. We conduct extensive experiments on large-scale real-world question data, where the experimental results clearly demonstrate the effectiveness of QuesNet for question understanding as well as its superior applicability.