 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoNoSplat: You Only Need One Model for Feedforward 3D Gaussian Splatting
Nov 10, 2025Fast and flexible 3D scene reconstruction from unstructured image collections remains a significant challenge. We present YoNoSplat, a feedforward model that reconstructs high-quality 3D Gaussian Splatting representations from an arbitrary number of images. Our model is highly versatile, operating effectively with both posed and unposed, calibrated and uncalibrated inputs. YoNoSplat predicts local Gaussians and camera poses for each view, which are aggregated into a global representation using either predicted or provided poses. To overcome the inherent difficulty of jointly learning 3D Gaussians and camera parameters, we introduce a novel mixing training strategy. This approach mitigates the entanglement between the two tasks by initially using ground-truth poses to aggregate local Gaussians and gradually transitioning to a mix of predicted and ground-truth poses, which prevents both training instability and exposure bias. We further resolve the scale ambiguity problem by a novel pairwise camera-distance normalization scheme and by embedding camera intrinsics into the network. Moreover, YoNoSplat also predicts intrinsic parameters, making it feasible for uncalibrated inputs. YoNoSplat demonstrates exceptional efficiency, reconstructing a scene from 100 views (at 280x518 resolution) in just 2.69 seconds on an NVIDIA GH200 GPU. It achieves state-of-the-art performance on standard benchmarks in both pose-free and pose-dependent settings. Our project page is at https://botaoye.github.io/yonosplat/.
ReSplat: Learning Recurrent Gaussian Splats
Oct 09, 2025While feed-forward Gaussian splatting models provide computational efficiency and effectively handle sparse input settings, their performance is fundamentally limited by the reliance on a single forward pass during inference. We propose ReSplat, a feed-forward recurrent Gaussian splatting model that iteratively refines 3D Gaussians without explicitly computing gradients. Our key insight is that the Gaussian splatting rendering error serves as a rich feedback signal, guiding the recurrent network to learn effective Gaussian updates. This feedback signal naturally adapts to unseen data distributions at test time, enabling robust generalization. To initialize the recurrent process, we introduce a compact reconstruction model that operates in a $16 \times$ subsampled space, producing $16 \times$ fewer Gaussians than previous per-pixel Gaussian models. This substantially reduces computational overhead and allows for efficient Gaussian updates. Extensive experiments across varying of input views (2, 8, 16), resolutions ($256 \times 256$ to $540 \times 960$), and datasets (DL3DV and RealEstate10K) demonstrate that our method achieves state-of-the-art performance while significantly reducing the number of Gaussians and improving the rendering speed. Our project page is at https://haofeixu.github.io/resplat/.
Object-X: Learning to Reconstruct Multi-Modal 3D Object Representations
Jun 05, 2025Learning effective multi-modal 3D representations of objects is essential for numerous applications, such as augmented reality and robotics. Existing methods often rely on task-specific embeddings that are tailored either for semantic understanding or geometric reconstruction. As a result, these embeddings typically cannot be decoded into explicit geometry and simultaneously reused across tasks. In this paper, we propose Object-X, a versatile multi-modal object representation framework capable of encoding rich object embeddings (e.g. images, point cloud, text) and decoding them back into detailed geometric and visual reconstructions. Object-X operates by geometrically grounding the captured modalities in a 3D voxel grid and learning an unstructured embedding fusing the information from the voxels with the object attributes. The learned embedding enables 3D Gaussian Splatting-based object reconstruction, while also supporting a range of downstream tasks, including scene alignment, single-image 3D object reconstruction, and localization. Evaluations on two challenging real-world datasets demonstrate that Object-X produces high-fidelity novel-view synthesis comparable to standard 3D Gaussian Splatting, while significantly improving geometric accuracy. Moreover, Object-X achieves competitive performance with specialized methods in scene alignment and localization. Critically, our object-centric descriptors require 3-4 orders of magnitude less storage compared to traditional image- or point cloud-based approaches, establishing Object-X as a scalable and highly practical solution for multi-modal 3D scene representation.
SupeRANSAC: One RANSAC to Rule Them All
Jun 05, 2025Robust estimation is a cornerstone in computer vision, particularly for tasks like Structure-from-Motion and Simultaneous Localization and Mapping. RANSAC and its variants are the gold standard for estimating geometric models (e.g., homographies, relative/absolute poses) from outlier-contaminated data. Despite RANSAC's apparent simplicity, achieving consistently high performance across different problems is challenging. While recent research often focuses on improving specific RANSAC components (e.g., sampling, scoring), overall performance is frequently more influenced by the "bells and whistles" (i.e., the implementation details and problem-specific optimizations) within a given library. Popular frameworks like OpenCV and PoseLib demonstrate varying performance, excelling in some tasks but lagging in others. We introduce SupeRANSAC, a novel unified RANSAC pipeline, and provide a detailed analysis of the techniques that make RANSAC effective for specific vision tasks, including homography, fundamental/essential matrix, and absolute/rigid pose estimation. SupeRANSAC is designed for consistent accuracy across these tasks, improving upon the best existing methods by, for example, 6 AUC points on average for fundamental matrix estimation. We demonstrate significant performance improvements over the state-of-the-art on multiple problems and datasets. Code: https://github.com/danini/superansac
Learning Affine Correspondences by Integrating Geometric Constraints
Apr 10, 2025



Affine correspondences have received significant attention due to their benefits in tasks like image matching and pose estimation. Existing methods for extracting affine correspondences still have many limitations in terms of performance; thus, exploring a new paradigm is crucial. In this paper, we present a new pipeline designed for extracting accurate affine correspondences by integrating dense matching and geometric constraints. Specifically, a novel extraction framework is introduced, with the aid of dense matching and a novel keypoint scale and orientation estimator. For this purpose, we propose loss functions based on geometric constraints, which can effectively improve accuracy by supervising neural networks to learn feature geometry. The experimental show that the accuracy and robustness of our method outperform the existing ones in image matching tasks. To further demonstrate the effectiveness of the proposed method, we applied it to relative pose estimation. Affine correspondences extracted by our method lead to more accurate poses than the baselines on a range of real-world datasets. The code is available at https://github.com/stilcrad/DenseAffine.
Robust Human Registration with Body Part Segmentation on Noisy Point Clouds
Apr 04, 2025



Registering human meshes to 3D point clouds is essential for applications such as augmented reality and human-robot interaction but often yields imprecise results due to noise and background clutter in real-world data. We introduce a hybrid approach that incorporates body-part segmentation into the mesh fitting process, enhancing both human pose estimation and segmentation accuracy. Our method first assigns body part labels to individual points, which then guide a two-step SMPL-X fitting: initial pose and orientation estimation using body part centroids, followed by global refinement of the point cloud alignment. Additionally, we demonstrate that the fitted human mesh can refine body part labels, leading to improved segmentation. Evaluations on the cluttered and noisy real-world datasets InterCap, EgoBody, and BEHAVE show that our approach significantly outperforms prior methods in both pose estimation and segmentation accuracy. Code and results are available on our project website: https://segfit.github.io
CrossOver: 3D Scene Cross-Modal Alignment
Feb 20, 2025Multi-modal 3D object understanding has gained significant attention, yet current approaches often assume complete data availability and rigid alignment across all modalities. We present CrossOver, a novel framework for cross-modal 3D scene understanding via flexible, scene-level modality alignment. Unlike traditional methods that require aligned modality data for every object instance, CrossOver learns a unified, modality-agnostic embedding space for scenes by aligning modalities - RGB images, point clouds, CAD models, floorplans, and text descriptions - with relaxed constraints and without explicit object semantics. Leveraging dimensionality-specific encoders, a multi-stage training pipeline, and emergent cross-modal behaviors, CrossOver supports robust scene retrieval and object localization, even with missing modalities. Evaluations on ScanNet and 3RScan datasets show its superior performance across diverse metrics, highlighting adaptability for real-world applications in 3D scene understanding.
DepthSplat: Connecting Gaussian Splatting and Depth
Oct 17, 2024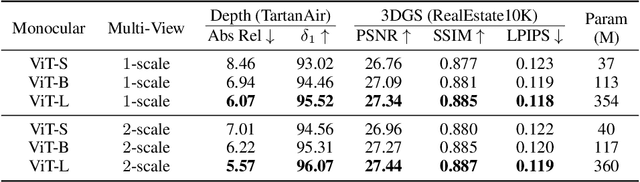
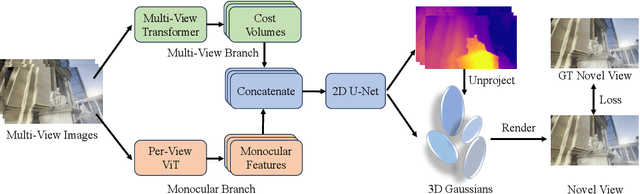
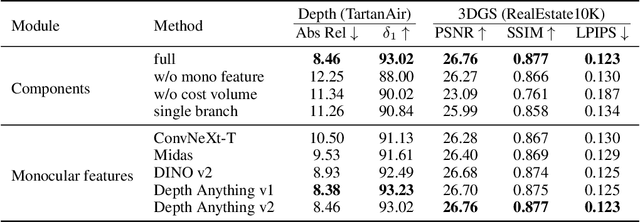

Gaussian splatting and single/multi-view depth estimation are typically studied in isolation. In this paper, we present DepthSplat to connect Gaussian splatting and depth estimation and study their interactions. More specifically, we first contribute a robust multi-view depth model by leveraging pre-trained monocular depth features, leading to high-quality feed-forward 3D Gaussian splatting reconstructions. We also show that Gaussian splatting can serve as an unsupervised pre-training objective for learning powerful depth models from large-scale unlabelled datasets. We validate the synergy between Gaussian splatting and depth estimation through extensive ablation and cross-task transfer experiments. Our DepthSplat achieves state-of-the-art performance on ScanNet, RealEstate10K and DL3DV datasets in terms of both depth estimation and novel view synthesis, demonstrating the mutual benefits of connecting both tasks. Our code, models, and video results are available at https://haofeixu.github.io/depthsplat/.
Learning Where to Look: Self-supervised Viewpoint Selection for Active Localization using Geometrical Information
Jul 22, 2024



Accurate localization in diverse environments is a fundamental challenge in computer vision and robotics. The task involves determining a sensor's precise position and orientation, typically a camera, within a given space. Traditional localization methods often rely on passive sensing, which may struggle in scenarios with limited features or dynamic environments. In response, this paper explores the domain of active localization, emphasizing the importance of viewpoint selection to enhance localization accuracy. Our contributions involve using a data-driven approach with a simple architecture designed for real-time operation, a self-supervised data training method, and the capability to consistently integrate our map into a planning framework tailored for real-world robotics applications. Our results demonstrate that our method performs better than the existing one, targeting similar problems and generalizing on synthetic and real data. We also release an open-source implementation to benefit the community.
Learning to Make Keypoints Sub-Pixel Accurate
Jul 16, 2024This work addresses the challenge of sub-pixel accuracy in detecting 2D local features, a cornerstone problem in computer vision. Despite the advancements brought by neural network-based methods like SuperPoint and ALIKED, these modern approaches lag behind classical ones such as SIFT in keypoint localization accuracy due to their lack of sub-pixel precision. We propose a novel network that enhances any detector with sub-pixel precision by learning an offset vector for detected features, thereby eliminating the need for designing specialized sub-pixel accurate detectors. This optimization directly minimizes test-time evaluation metrics like relative pose error. Through extensive testing with both nearest neighbors matching and the recent LightGlue matcher across various real-world datasets, our method consistently outperforms existing methods in accuracy. Moreover, it adds only around 7 ms to the time of a particular detector. The code is available at https://github.com/KimSinjeong/keypt2subpx .