 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunRec: Reconstructing Functional 3D Scenes from Egocentric Interaction Videos
Apr 07, 2026We present FunRec, a method for reconstructing functional 3D digital twins of indoor scenes directly from egocentric RGB-D interaction videos. Unlike existing methods on articulated reconstruction, which rely on controlled setups, multi-state captures, or CAD priors, FunRec operates directly on in-the-wild human interaction sequences to recover interactable 3D scenes. It automatically discovers articulated parts, estimates their kinematic parameters, tracks their 3D motion, and reconstructs static and moving geometry in canonical space, yielding simulation-compatible meshes. Across new real and simulated benchmarks, FunRec surpasses prior work by a large margin, achieving up to +50 mIoU improvement in part segmentation, 5-10 times lower articulation and pose errors, and significantly higher reconstruction accuracy. We further demonstrate applications on URDF/USD export for simulation, hand-guided affordance mapping and robot-scene interaction.
Memory Over Maps: 3D Object Localization Without Reconstruction
Mar 20, 2026Target localization is a prerequisite for embodied tasks such as navigation and manipulation. Conventional approaches rely on constructing explicit 3D scene representations to enable target localization, such as point clouds, voxel grids, or scene graphs. While effective, these pipelines incur substantial mapping time, storage overhead, and scalability limitations. Recent advances in vision-language models suggest that rich semantic reasoning can be performed directly on 2D observations, raising a fundamental question: is a complete 3D scene reconstruction necessary for object localization? In this work, we revisit object localization and propose a map-free pipeline that stores only posed RGB-D keyframes as a lightweight visual memory--without constructing any global 3D representation of the scene. At query time, our method retrieves candidate views, re-ranks them with a vision-language model, and constructs a sparse, on-demand 3D estimate of the queried target through depth backprojection and multi-view fusion. Compared to reconstruction-based pipelines, this design drastically reduces preprocessing cost, enabling scene indexing that is over two orders of magnitude faster to build while using substantially less storage. We further validate the localized targets on downstream object-goal navigation tasks. Despite requiring no task-specific training, our approach achieves strong performance across multiple benchmarks, demonstrating that direct reasoning over image-based scene memory can effectively replace dense 3D reconstruction for object-centric robot navigation. Project page: https://ruizhou-cn.github.io/memory-over-maps/
OpenFrontier: General Navigation with Visual-Language Grounded Frontiers
Mar 05, 2026Open-world navigation requires robots to make decisions in complex everyday environments while adapting to flexible task requirements. Conventional navigation approaches often rely on dense 3D reconstruction and hand-crafted goal metrics, which limits their generalization across tasks and environments. Recent advances in vision--language navigation (VLN) and vision--language--action (VLA) models enable end-to-end policies conditioned on natural language, but typically require interactive training, large-scale data collection, or task-specific fine-tuning with a mobile agent. We formulate navigation as a sparse subgoal identification and reaching problem and observe that providing visual anchoring targets for high-level semantic priors enables highly efficient goal-conditioned navigation. Based on this insight, we select navigation frontiers as semantic anchors and propose OpenFrontier, a training-free navigation framework that seamlessly integrates diverse vision--language prior models. OpenFrontier enables efficient navigation with a lightweight system design, without dense 3D mapping, policy training, or model fine-tuning. We evaluate OpenFrontier across multiple navigation benchmarks and demonstrate strong zero-shot performance, as well as effective real-world deployment on a mobile robot.
Unsupervised Synthetic Image Attribution: Alignment and Disentanglement
Jan 30, 2026As the quality of synthetic images improves, identifying the underlying concepts of model-generated images is becoming increasingly crucial for copyright protection and ensuring model transparency. Existing methods achieve this attribution goal by training models using annotated pairs of synthetic images and their original training sources. However, obtaining such paired supervision is challenging, as it requires either well-designed synthetic concepts or precise annotations from millions of training sources. To eliminate the need for costly paired annotations, in this paper, we explore the possibility of unsupervised synthetic image attribution. We propose a simple yet effective unsupervised method called Alignment and Disentanglement. Specifically, we begin by performing basic concept alignment using contrastive self-supervised learning. Next, we enhance the model's attribution ability by promoting representation disentanglement with the Infomax loss. This approach is motivated by an interesting observation: contrastive self-supervised models, such as MoCo and DINO, inherently exhibit the ability to perform simple cross-domain alignment. By formulating this observation as a theoretical assumption on cross-covariance, we provide a theoretical explanation of how alignment and disentanglement can approximate the concept-matching process through a decomposition of the canonical correlation analysis objective. On the real-world benchmarks, AbC, we show that our unsupervised method surprisingly outperforms the supervised methods. As a starting point, we expect our intuitive insights and experimental findings to provide a fresh perspective on this challenging task.
What Matters in RL-Based Methods for Object-Goal Navigation? An Empirical Study and A Unified Framework
Oct 02, 2025
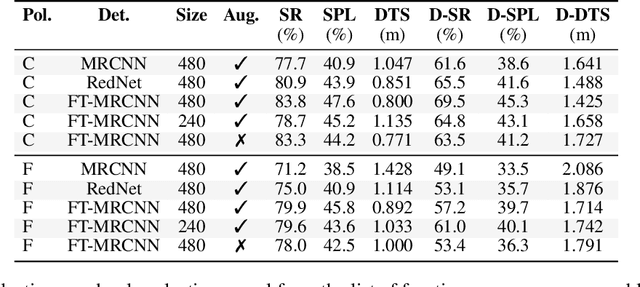
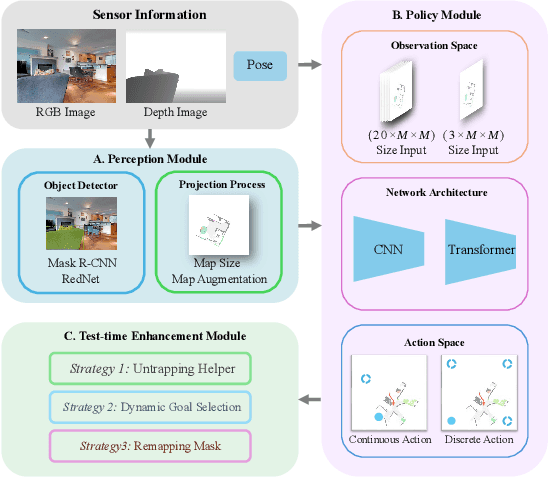
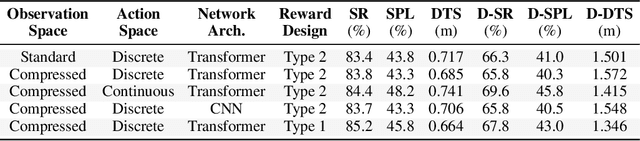
Object-Goal Navigation (ObjectNav) is a critical component toward deploying mobile robots in everyday, uncontrolled environments such as homes, schools, and workplaces. In this context, a robot must locate target objects in previously unseen environments using only its onboard perception. Success requires the integration of semantic understanding, spatial reasoning, and long-horizon planning, which is a combination that remains extremely challenging. While reinforcement learning (RL) has become the dominant paradigm, progress has spanned a wide range of design choices, yet the field still lacks a unifying analysis to determine which components truly drive performance. In this work, we conduct a large-scale empirical study of modular RL-based ObjectNav systems, decomposing them into three key components: perception, policy, and test-time enhancement. Through extensive controlled experiments, we isolate the contribution of each and uncover clear trends: perception quality and test-time strategies are decisive drivers of performance, whereas policy improvements with current methods yield only marginal gains. Building on these insights, we propose practical design guidelines and demonstrate an enhanced modular system that surpasses State-of-the-Art (SotA) methods by 6.6% on SPL and by a 2.7% success rate. We also introduce a human baseline under identical conditions, where experts achieve an average 98% success, underscoring the gap between RL agents and human-level navigation. Our study not only sets the SotA performance but also provides principled guidance for future ObjectNav development and evaluation.
ActLoc: Learning to Localize on the Move via Active Viewpoint Selection
Aug 28, 2025Reliable localization is critical for robot navigation, yet most existing systems implicitly assume that all viewing directions at a location are equally informative. In practice, localization becomes unreliable when the robot observes unmapped, ambiguous, or uninformative regions. To address this, we present ActLoc, an active viewpoint-aware planning framework for enhancing localization accuracy for general robot navigation tasks. At its core, ActLoc employs a largescale trained attention-based model for viewpoint selection. The model encodes a metric map and the camera poses used during map construction, and predicts localization accuracy across yaw and pitch directions at arbitrary 3D locations. These per-point accuracy distributions are incorporated into a path planner, enabling the robot to actively select camera orientations that maximize localization robustness while respecting task and motion constraints. ActLoc achieves stateof-the-art results on single-viewpoint selection and generalizes effectively to fulltrajectory planning. Its modular design makes it readily applicable to diverse robot navigation and inspection tasks.
A Sample Efficient Conditional Independence Test in the Presence of Discretization
Jun 10, 2025In many real-world scenarios, interested variables are often represented as discretized values due to measurement limitations. Applying Conditional Independence (CI) tests directly to such discretized data, however, can lead to incorrect conclusions. To address this, recent advancements have sought to infer the correct CI relationship between the latent variables through binarizing observed data. However, this process inevitably results in a loss of information, which degrades the test's performance. Motivated by this, this paper introduces a sample-efficient CI test that does not rely on the binarization process. We find that the independence relationships of latent continuous variables can be established by addressing an over-identifying restriction problem with Generalized Method of Moments (GMM). Based on this insight, we derive an appropriate test statistic and establish its asymptotic distribution correctly reflecting CI by leveraging nodewise regression. Theoretical findings and Empirical results across various datasets demonstrate that the superiority and effectiveness of our proposed test. Our code implementation is provided in https://github.com/boyangaaaaa/DCT
ForesightNav: Learning Scene Imagination for Efficient Exploration
Apr 22, 2025Understanding how humans leverage prior knowledge to navigate unseen environments while making exploratory decisions is essential for developing autonomous robots with similar abilities. In this work, we propose ForesightNav, a novel exploration strategy inspired by human imagination and reasoning. Our approach equips robotic agents with the capability to predict contextual information, such as occupancy and semantic details, for unexplored regions. These predictions enable the robot to efficiently select meaningful long-term navigation goals, significantly enhancing exploration in unseen environments. We validate our imagination-based approach using the Structured3D dataset, demonstrating accurate occupancy prediction and superior performance in anticipating unseen scene geometry. Our experiments show that the imagination module improves exploration efficiency in unseen environments, achieving a 100% completion rate for PointNav and an SPL of 67% for ObjectNav on the Structured3D Validation split. These contributions demonstrate the power of imagination-driven reasoning for autonomous systems to enhance generalizable and efficient exploration.
SuperDec: 3D Scene Decomposition with Superquadric Primitives
Apr 01, 2025

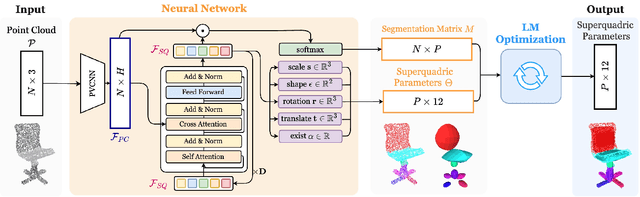

We present SuperDec, an approach for creating compact 3D scene representations via decomposition into superquadric primitives. While most recent works leverage geometric primitives to obtain photorealistic 3D scene representations, we propose to leverage them to obtain a compact yet expressive representation. We propose to solve the problem locally on individual objects and leverage the capabilities of instance segmentation methods to scale our solution to full 3D scenes. In doing that, we design a new architecture which efficiently decompose point clouds of arbitrary objects in a compact set of superquadrics. We train our architecture on ShapeNet and we prove its generalization capabilities on object instances extracted from the ScanNet++ dataset as well as on full Replica scenes. Finally, we show how a compact representation based on superquadrics can be useful for a diverse range of downstream applications, including robotic tasks and controllable visual content generation and editing.
Loop Closure from Two Views: Revisiting PGO for Scalable Trajectory Estimation through Monocular Priors
Mar 20, 2025



(Visual) Simultaneous Localization and Mapping (SLAM) remains a fundamental challenge in enabling autonomous systems to navigate and understand large-scale environments. Traditional SLAM approaches struggle to balance efficiency and accuracy, particularly in large-scale settings where extensive computational resources are required for scene reconstruction and Bundle Adjustment (BA). However, this scene reconstruction, in the form of sparse pointclouds of visual landmarks, is often only used within the SLAM system because navigation and planning methods require different map representations. In this work, we therefore investigate a more scalable Visual SLAM (VSLAM) approach without reconstruction, mainly based on approaches for two-view loop closures. By restricting the map to a sparse keyframed pose graph without dense geometry representations, our '2GO' system achieves efficient optimization with competitive absolute trajectory accuracy. In particular, we find that recent advancements in image matching and monocular depth priors enable very accurate trajectory optimization from two-view edges. We conduct extensive experiments on diverse datasets, including large-scale scenarios, and provide a detailed analysis of the trade-offs between runtime, accuracy, and map size. Our results demonstrate that this streamlined approach supports real-time performance, scales well in map size and trajectory duration, and effectively broadens the capabilities of VSLAM for long-duration deployments to large environments.