 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop
May 18, 2026Spatial intelligence unfolds through a perception-action loop: agents act to acquire observations, and reason about how observations vary as a function of action. Rather than passively processing what is seen, they actively uncover what is unseen - occluded structure, dynamics, containment, and functionality that cannot be resolved from passive sensing alone. We move beyond prior formulations of spatial intelligence that assume oracle observations by recasting the observer as an actor. We introduce ESI-BENCH, a comprehensive benchmark for embodied spatial intelligence spanning 10 task categories and 29 subcategories built on OmniGibson, grounded in Spelke's core knowledge systems. Agents must decide what abilities to deploy - perception, locomotion, and manipulation - and how to sequence them to actively accumulate task-relevant evidence. We conduct extensive experiments on state-of-the-art MLLMs and find that active exploration substantially outperforms passive counterparts, with agents spontaneously discovering emergent spatial strategies without explicit instructions, while random multi-view often adds noise rather than signal despite consuming far more images. Most failures stem not from weak perception but from action blindness: poor action choices lead to poor observations, which in turn drive cascading errors. While explicit 3D grounding stabilizes reasoning on depth-sensitive tasks, imperfect 3D representation proves more harmful than 2D baselines by distorting spatial relations. Human studies further reveal that unlike humans who seek falsifying viewpoints and revise beliefs under contradiction, models commit prematurely with high confidence regardless of evidence quality, exposing a metacognitive gap that neither better perception nor more embodied interaction alone can close.
Asymmetric Flow Models
May 13, 2026Flow-based generation in high-dimensional spaces is difficult because velocity prediction requires modeling high-dimensional noise, even when data has strong low-rank structure. We present Asymmetric Flow Modeling (AsymFlow), a rank-asymmetric velocity parameterization that restricts noise prediction to a low-rank subspace while keeping data prediction full-dimensional. From this asymmetric prediction, AsymFlow analytically recovers the full-dimensional velocity without changing the network architecture or training/sampling procedures. On ImageNet 256$\times$256, AsymFlow achieves a leading 1.57 FID, outperforming prior DiT/JiT-like pixel diffusion models by a large margin. AsymFlow also provides the first-ever route for finetuning pretrained latent flow models into pixel-space models: aligning the low-rank pixel subspace to the latent space gives a seamless initialization that preserves the latent model's high-level semantics and structure, so finetuning mainly improves low-level mismatches rather than relearning pixel generation. We show that the pixel AsymFlow model finetuned from FLUX.2 klein 9B establishes a new state of the art for pixel-space text-to-image generation, beating its latent base on HPSv3, DPG-Bench, and GenEval while qualitatively showing substantially improved visual realism.
OCH3R: Object-Centric Holistic 3D Reconstruction
May 13, 2026Object-centric scene understanding is a fundamental challenge in computer vision. Existing approaches often rely on multi-stage pipelines that first apply pre-trained segmentors to extract individual objects, followed by per-object 3D reconstruction. Such methods are computationally expensive, fragile to segmentation errors, and scale poorly with scene complexity. We introduce OCH3R, a unified framework for Object-Centric Holistic 3D Reconstruction from a single RGB image. OCH3R performs one forward pass to simultaneously predict all object instances with their 6D poses and detailed 3D reconstructions. The key idea is a transformer architecture that predicts per-pixel attributes, including CLIP-based category embeddings, metric depth, normalized object coordinates (NOCS), and a fixed number of 3D Gaussians representing each object. To supervise these Gaussian reconstructions, we transform them into canonical space using the predicted 6D poses and align them with pre-rendered canonical ground truth, avoiding costly per-image Gaussian label generation. On standard indoor benchmarks, OCH3R achieves state-of-the-art performance across monocular depth estimation, open-vocabulary semantic segmentation, and RGB-only category-level 6D pose estimation, while producing high-fidelity, editable per-object reconstructions. Crucially, inference is fully feed-forward and scales independently of the number of objects, offering orders-of-magnitude speedups over conventional multi-stage pipelines in cluttered scenes.
The Cartesian Shortcut: Re-evaluate Vision Reasoning in Polar Coordinate Space
May 11, 2026As current Multimodal Large Language Models rapidly saturate canonical visual reasoning benchmarks, a key question emerges: do these strong scores genuinely reflect robust visual understanding? We identify a pervasive vulnerability, the \textbf{Cartesian Shortcut}: visual reasoning benchmarks prevalently build on orthogonal grid-based layouts that can be readily discretized into explicit textual coordinates. Models systematically exploit this property, heavily leveraging text-based deductive reasoning to assist visual problem-solving. To systematically dismantle this shortcut, we introduce \textbf{Polaris-Bench}, which re-formulates 53 visual reasoning tasks in Polar coordinate space with paired Cartesian counterparts as reference, while preserving consistent logical constraints and task semantics -- thus fundamentally breaking the orthogonal prior that models exploit. Comprehensive evaluation across $14$ state-of-the-art MLLMs reveals that frontier models achieving $70$--$83\%$ on Cartesian layouts collapse to $31$--$39\%$ on Polar equivalents, with degradation persisting even under complete logical equivalence. Moreover, reasoning gains observed on Cartesian layouts are severely diminished on Polar equivalents. These findings expose a critical deficiency in current MLLMs: the lack of topology-invariant visual reasoning.
FunRec: Reconstructing Functional 3D Scenes from Egocentric Interaction Videos
Apr 07, 2026We present FunRec, a method for reconstructing functional 3D digital twins of indoor scenes directly from egocentric RGB-D interaction videos. Unlike existing methods on articulated reconstruction, which rely on controlled setups, multi-state captures, or CAD priors, FunRec operates directly on in-the-wild human interaction sequences to recover interactable 3D scenes. It automatically discovers articulated parts, estimates their kinematic parameters, tracks their 3D motion, and reconstructs static and moving geometry in canonical space, yielding simulation-compatible meshes. Across new real and simulated benchmarks, FunRec surpasses prior work by a large margin, achieving up to +50 mIoU improvement in part segmentation, 5-10 times lower articulation and pose errors, and significantly higher reconstruction accuracy. We further demonstrate applications on URDF/USD export for simulation, hand-guided affordance mapping and robot-scene interaction.
SceneTeract: Agentic Functional Affordances and VLM Grounding in 3D Scenes
Mar 31, 2026Embodied AI depends on interactive 3D environments that support meaningful activities for diverse users, yet assessing their functional affordances remains a core challenge. We introduce SceneTeract, a framework that verifies 3D scene functionality under agent-specific constraints. Our core contribution is a grounded verification engine that couples high-level semantic reasoning with low-level geometric checks. SceneTeract decomposes complex activities into sequences of atomic actions and validates each step against accessibility requirements (e.g., reachability, clearance, and navigability) conditioned on an embodied agent profile, using explicit physical and geometric simulations. We deploy SceneTeract to perform an in-depth evaluation of (i) synthetic indoor environments, uncovering frequent functional failures that prevent basic interactions, and (ii) the ability of frontier Vision-Language Models (VLMs) to reason about and predict functional affordances, revealing systematic mismatches between semantic confidence and physical feasibility even for the strongest current models. Finally, we leverage SceneTeract as a reward engine for VLM post-training, enabling scalable distillation of geometric constraints into reasoning models. We release the SceneTeract verification suite and data to bridge perception and physical reality in embodied 3D scene understanding.
RINO: Rotation-Invariant Non-Rigid Correspondences
Mar 29, 2026Dense 3D shape correspondence remains a central challenge in computer vision and graphics as many deep learning approaches still rely on intermediate geometric features or handcrafted descriptors, limiting their effectiveness under non-isometric deformations, partial data, and non-manifold inputs. To overcome these issues, we introduce RINO, an unsupervised, rotation-invariant dense correspondence framework that effectively unifies rigid and non-rigid shape matching. The core of our method is the novel RINONet, a feature extractor that integrates vector-based SO(3)-invariant learning with orientation-aware complex functional maps to extract robust features directly from raw geometry. This allows for a fully end-to-end, data-driven approach that bypasses the need for shape pre-alignment or handcrafted features. Extensive experiments show unprecedented performance of RINO across challenging non-rigid matching tasks, including arbitrary poses, non-isometry, partiality, non-manifoldness, and noise.
* 17 pages, 36 Figures, Computer Vision and Pattern Recognition (CVPR) 2026
Mode Seeking meets Mean Seeking for Fast Long Video Generation
Feb 27, 2026Scaling video generation from seconds to minutes faces a critical bottleneck: while short-video data is abundant and high-fidelity, coherent long-form data is scarce and limited to narrow domains. To address this, we propose a training paradigm where Mode Seeking meets Mean Seeking, decoupling local fidelity from long-term coherence based on a unified representation via a Decoupled Diffusion Transformer. Our approach utilizes a global Flow Matching head trained via supervised learning on long videos to capture narrative structure, while simultaneously employing a local Distribution Matching head that aligns sliding windows to a frozen short-video teacher via a mode-seeking reverse-KL divergence. This strategy enables the synthesis of minute-scale videos that learns long-range coherence and motions from limited long videos via supervised flow matching, while inheriting local realism by aligning every sliding-window segment of the student to a frozen short-video teacher, resulting in a few-step fast long video generator. Evaluations show that our method effectively closes the fidelity-horizon gap by jointly improving local sharpness, motion and long-range consistency. Project website: https://primecai.github.io/mmm/.
Learning Physical Principles from Interaction: Self-Evolving Planning via Test-Time Memory
Feb 23, 2026Reliable object manipulation requires understanding physical properties that vary across objects and environments. Vision-language model (VLM) planners can reason about friction and stability in general terms; however, they often cannot predict how a specific ball will roll on a particular surface or which stone will provide a stable foundation without direct experience. We present PhysMem, a memory framework that enables VLM robot planners to learn physical principles from interaction at test time, without updating model parameters. The system records experiences, generates candidate hypotheses, and verifies them through targeted interaction before promoting validated knowledge to guide future decisions. A central design choice is verification before application: the system tests hypotheses against new observations rather than applying retrieved experience directly, reducing rigid reliance on prior experience when physical conditions change. We evaluate PhysMem on three real-world manipulation tasks and simulation benchmarks across four VLM backbones. On a controlled brick insertion task, principled abstraction achieves 76% success compared to 23% for direct experience retrieval, and real-world experiments show consistent improvement over 30-minute deployment sessions.
Mull-Tokens: Modality-Agnostic Latent Thinking
Dec 11, 2025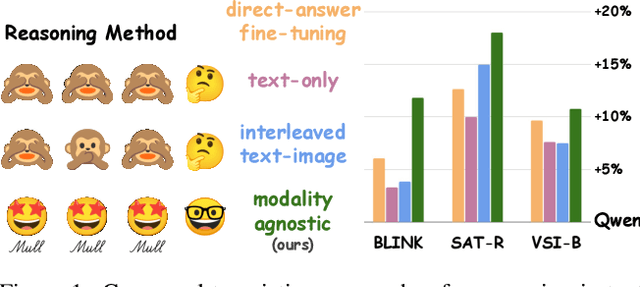
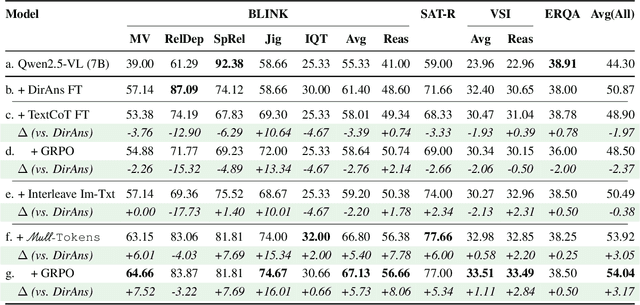
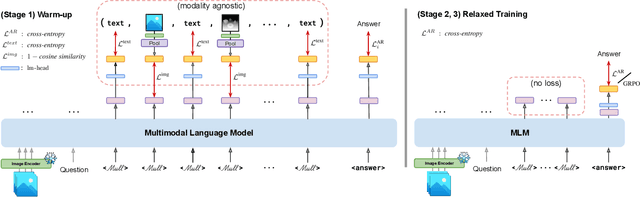
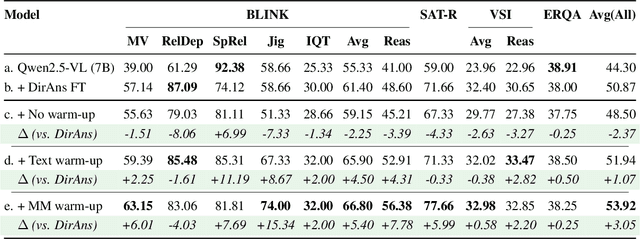
Reasoning goes beyond language; the real world requires reasoning about space, time, affordances, and much more that words alone cannot convey. Existing multimodal models exploring the potential of reasoning with images are brittle and do not scale. They rely on calling specialist tools, costly generation of images, or handcrafted reasoning data to switch between text and image thoughts. Instead, we offer a simpler alternative -- Mull-Tokens -- modality-agnostic latent tokens pre-trained to hold intermediate information in either image or text modalities to let the model think free-form towards the correct answer. We investigate best practices to train Mull-Tokens inspired by latent reasoning frameworks. We first train Mull-Tokens using supervision from interleaved text-image traces, and then fine-tune without any supervision by only using the final answers. Across four challenging spatial reasoning benchmarks involving tasks such as solving puzzles and taking different perspectives, we demonstrate that Mull-Tokens improve upon several baselines utilizing text-only reasoning or interleaved image-text reasoning, achieving a +3% average improvement and up to +16% on a puzzle solving reasoning-heavy split compared to our strongest baseline. Adding to conversations around challenges in grounding textual and visual reasoning, Mull-Tokens offers a simple solution to abstractly think in multiple modalities.