 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving
May 21, 2026Robust training and validation of Autonomous Driving Systems (ADS) require massive, diverse datasets. Proprietary data collected by Autonomous Vehicle (AV) fleets, while high-fidelity, are limited in scale, diversity of sensor configurations, as well as geographic and long-tail-behavioral coverage. In contrast, in-the-wild data from sources like dashcams offers immense scale and diversity, capturing critical long-tail scenarios and novel environments. However, this unstructured, in-the-wild video data is incompatible with ADS expecting structured, multi-modal sensor inputs for validation and training. To bridge this data gap, we propose Sensor2Sensor, a novel generative modeling paradigm that translates in-the-wild monocular dashcam videos into a high-fidelity, multi-modal sensor suite (AV logs) comprising multi-view camera images and LiDAR point clouds. A core challenge is the lack of paired training data. We address this by converting real AV logs into dashcam-style videos via 4D Gaussian Splatting (4DGS) reconstruction and novel-view rendering. Sensor2Sensor then utilizes a diffusion architecture to perform the generative conversion. We perform comprehensive quantitative evaluations on the fidelity and realism of the generated sensor data. We demonstrate Sensor2Sensor's practical utility by converting challenging in-the-wild internet and dashcam footage into realistic, multi-modal data formats, further unlocking vast external data sources for AV development.
SceneCrafter: Controllable Multi-View Driving Scene Editing
Jun 24, 2025Simulation is crucial for developing and evaluating autonomous vehicle (AV) systems. Recent literature builds on a new generation of generative models to synthesize highly realistic images for full-stack simulation. However, purely synthetically generated scenes are not grounded in reality and have difficulty in inspiring confidence in the relevance of its outcomes. Editing models, on the other hand, leverage source scenes from real driving logs, and enable the simulation of different traffic layouts, behaviors, and operating conditions such as weather and time of day. While image editing is an established topic in computer vision, it presents fresh sets of challenges in driving simulation: (1) the need for cross-camera 3D consistency, (2) learning ``empty street" priors from driving data with foreground occlusions, and (3) obtaining paired image tuples of varied editing conditions while preserving consistent layout and geometry. To address these challenges, we propose SceneCrafter, a versatile editor for realistic 3D-consistent manipulation of driving scenes captured from multiple cameras. We build on recent advancements in multi-view diffusion models, using a fully controllable framework that scales seamlessly to multi-modality conditions like weather, time of day, agent boxes and high-definition maps. To generate paired data for supervising the editing model, we propose a novel framework on top of Prompt-to-Prompt to generate geometrically consistent synthetic paired data with global edits. We also introduce an alpha-blending framework to synthesize data with local edits, leveraging a model trained on empty street priors through novel masked training and multi-view repaint paradigm. SceneCrafter demonstrates powerful editing capabilities and achieves state-of-the-art realism, controllability, 3D consistency, and scene editing quality compared to existing baselines.
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Jan 04, 2024



3D panoptic segmentation is a challenging perception task, which aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing to novel categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not achieve good performance due to poor per-mask classification quality on novel categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms strong baselines by a large margin.
MotionDiffuser: Controllable Multi-Agent Motion Prediction using Diffusion
Jun 05, 2023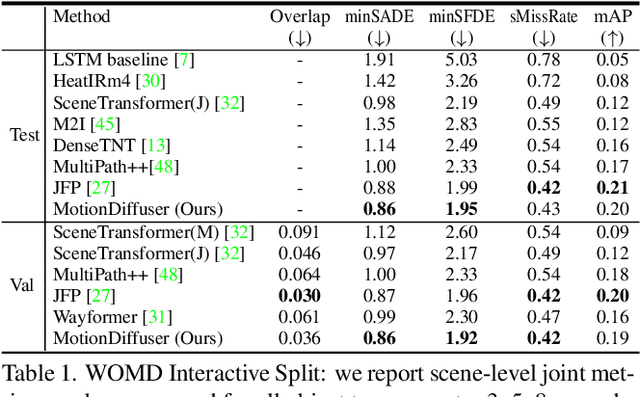
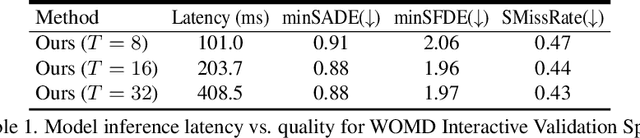
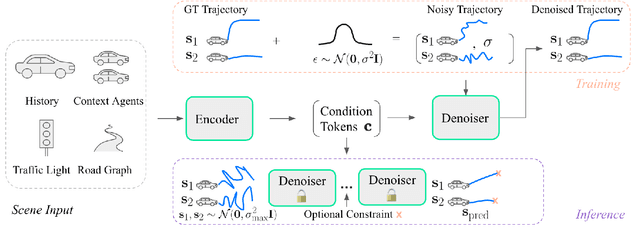
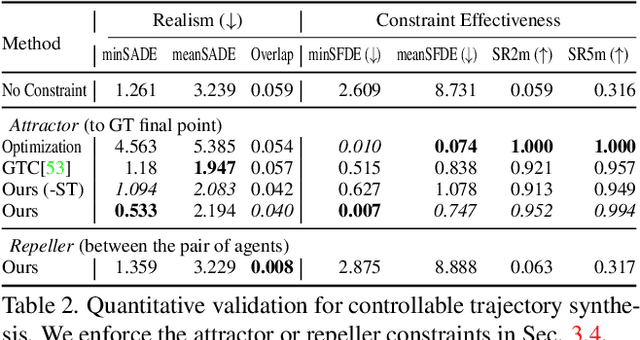
We present MotionDiffuser, a diffusion based representation for the joint distribution of future trajectories over multiple agents. Such representation has several key advantages: first, our model learns a highly multimodal distribution that captures diverse future outcomes. Second, the simple predictor design requires only a single L2 loss training objective, and does not depend on trajectory anchors. Third, our model is capable of learning the joint distribution for the motion of multiple agents in a permutation-invariant manner. Furthermore, we utilize a compressed trajectory representation via PCA, which improves model performance and allows for efficient computation of the exact sample log probability. Subsequently, we propose a general constrained sampling framework that enables controlled trajectory sampling based on differentiable cost functions. This strategy enables a host of applications such as enforcing rules and physical priors, or creating tailored simulation scenarios. MotionDiffuser can be combined with existing backbone architectures to achieve top motion forecasting results. We obtain state-of-the-art results for multi-agent motion prediction on the Waymo Open Motion Dataset.
Improving the Intra-class Long-tail in 3D Detection via Rare Example Mining
Oct 15, 2022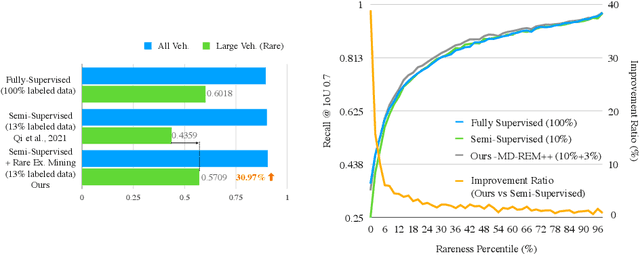
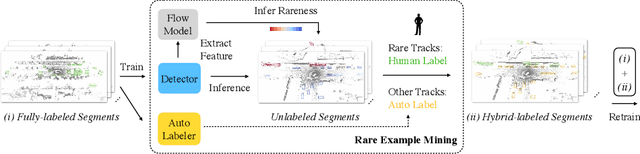
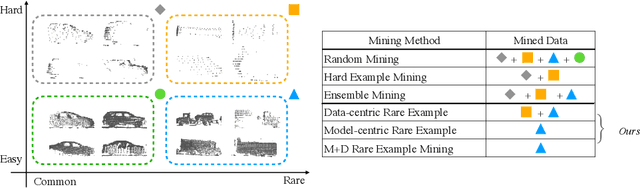
Continued improvements in deep learning architectures have steadily advanced the overall performance of 3D object detectors to levels on par with humans for certain tasks and datasets, where the overall performance is mostly driven by common examples. However, even the best performing models suffer from the most naive mistakes when it comes to rare examples that do not appear frequently in the training data, such as vehicles with irregular geometries. Most studies in the long-tail literature focus on class-imbalanced classification problems with known imbalanced label counts per class, but they are not directly applicable to the intra-class long-tail examples in problems with large intra-class variations such as 3D object detection, where instances with the same class label can have drastically varied properties such as shapes and sizes. Other works propose to mitigate this problem using active learning based on the criteria of uncertainty, difficulty, or diversity. In this study, we identify a new conceptual dimension - rareness - to mine new data for improving the long-tail performance of models. We show that rareness, as opposed to difficulty, is the key to data-centric improvements for 3D detectors, since rareness is the result of a lack in data support while difficulty is related to the fundamental ambiguity in the problem. We propose a general and effective method to identify the rareness of objects based on density estimation in the feature space using flow models, and propose a principled cost-aware formulation for mining rare object tracks, which improves overall model performance, but more importantly - significantly improves the performance for rare objects (by 30.97\%
MeshfreeFlowNet: A Physics-Constrained Deep Continuous Space-Time Super-Resolution Framework
May 01, 2020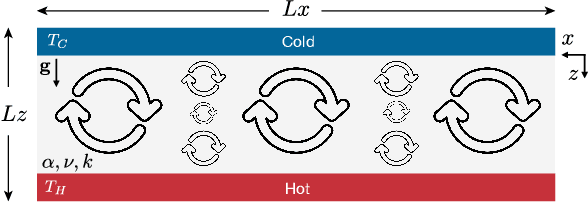
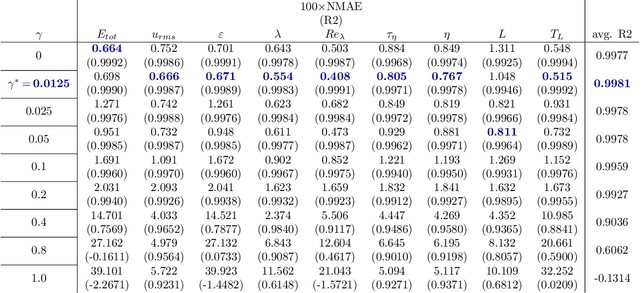
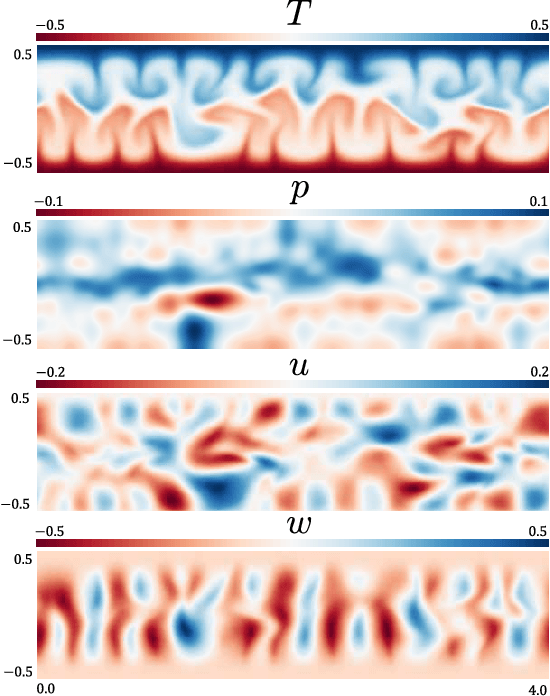
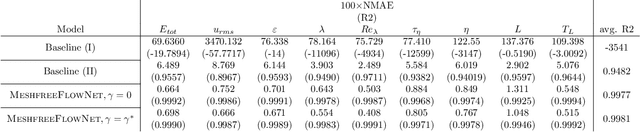
We propose MeshfreeFlowNet, a novel deep learning-based super-resolution framework to generate continuous (grid-free) spatio-temporal solutions from the low-resolution inputs. While being computationally efficient, MeshfreeFlowNet accurately recovers the fine-scale quantities of interest. MeshfreeFlowNet allows for: (i) the output to be sampled at all spatio-temporal resolutions, (ii) a set of Partial Differential Equation (PDE) constraints to be imposed, and (iii) training on fixed-size inputs on arbitrarily sized spatio-temporal domains owing to its fully convolutional encoder. We empirically study the performance of MeshfreeFlowNet on the task of super-resolution of turbulent flows in the Rayleigh-Benard convection problem. Across a diverse set of evaluation metrics, we show that MeshfreeFlowNet significantly outperforms existing baselines. Furthermore, we provide a large scale implementation of MeshfreeFlowNet and show that it efficiently scales across large clusters, achieving 96.80% scaling efficiency on up to 128 GPUs and a training time of less than 4 minutes.
Local Implicit Grid Representations for 3D Scenes
Mar 19, 2020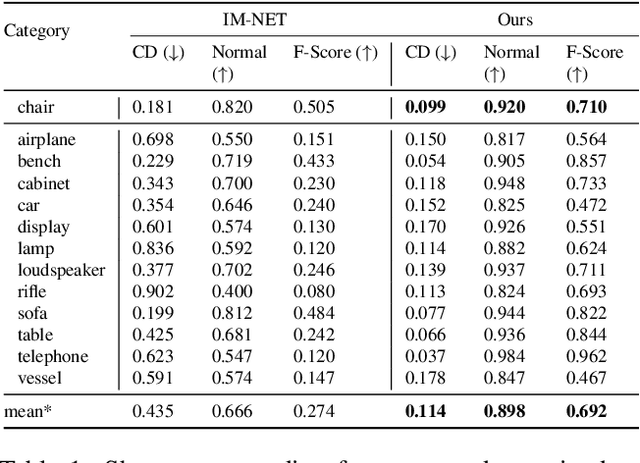
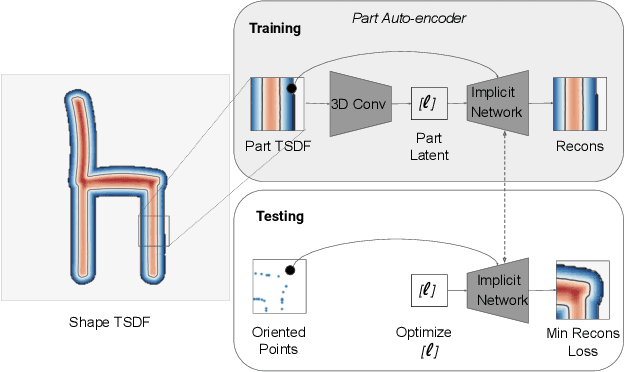
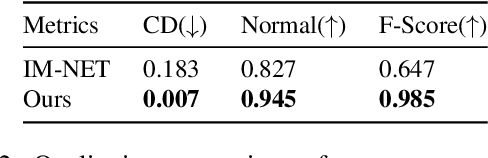
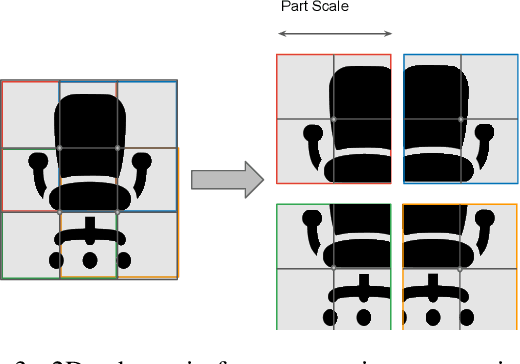
Shape priors learned from data are commonly used to reconstruct 3D objects from partial or noisy data. Yet no such shape priors are available for indoor scenes, since typical 3D autoencoders cannot handle their scale, complexity, or diversity. In this paper, we introduce Local Implicit Grid Representations, a new 3D shape representation designed for scalability and generality. The motivating idea is that most 3D surfaces share geometric details at some scale -- i.e., at a scale smaller than an entire object and larger than a small patch. We train an autoencoder to learn an embedding of local crops of 3D shapes at that size. Then, we use the decoder as a component in a shape optimization that solves for a set of latent codes on a regular grid of overlapping crops such that an interpolation of the decoded local shapes matches a partial or noisy observation. We demonstrate the value of this proposed approach for 3D surface reconstruction from sparse point observations, showing significantly better results than alternative approaches.
Adversarial Texture Optimization from RGB-D Scans
Mar 18, 2020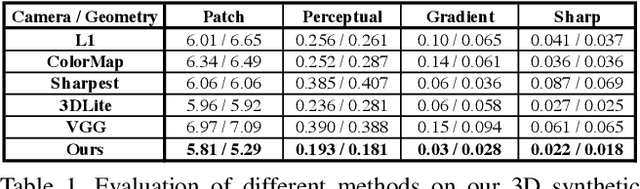
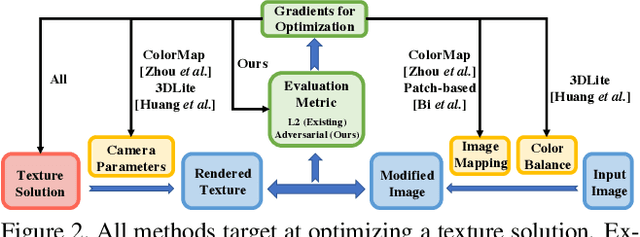
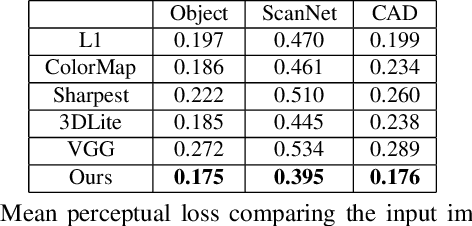
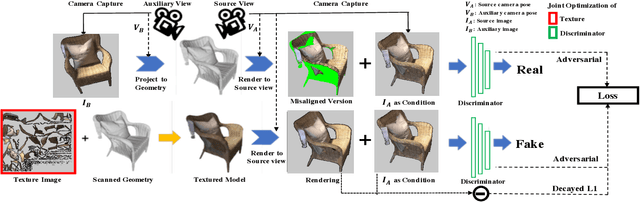
Realistic color texture generation is an important step in RGB-D surface reconstruction, but remains challenging in practice due to inaccuracies in reconstructed geometry, misaligned camera poses, and view-dependent imaging artifacts. In this work, we present a novel approach for color texture generation using a conditional adversarial loss obtained from weakly-supervised views. Specifically, we propose an approach to produce photorealistic textures for approximate surfaces, even from misaligned images, by learning an objective function that is robust to these errors. The key idea of our approach is to learn a patch-based conditional discriminator which guides the texture optimization to be tolerant to misalignments. Our discriminator takes a synthesized view and a real image, and evaluates whether the synthesized one is realistic, under a broadened definition of realism. We train the discriminator by providing as `real' examples pairs of input views and their misaligned versions -- so that the learned adversarial loss will tolerate errors from the scans. Experiments on synthetic and real data under quantitative or qualitative evaluation demonstrate the advantage of our approach in comparison to state of the art. Our code is publicly available with video demonstration.