 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionDiffuser: Controllable Multi-Agent Motion Prediction using Diffusion
Jun 05, 2023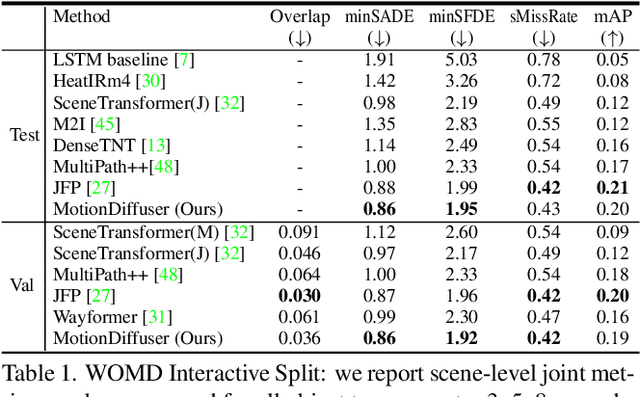
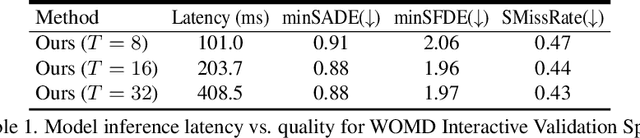
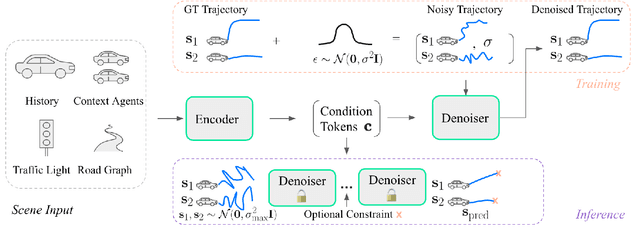
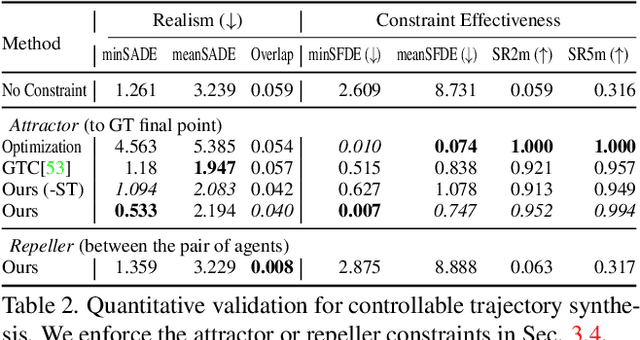
We present MotionDiffuser, a diffusion based representation for the joint distribution of future trajectories over multiple agents. Such representation has several key advantages: first, our model learns a highly multimodal distribution that captures diverse future outcomes. Second, the simple predictor design requires only a single L2 loss training objective, and does not depend on trajectory anchors. Third, our model is capable of learning the joint distribution for the motion of multiple agents in a permutation-invariant manner. Furthermore, we utilize a compressed trajectory representation via PCA, which improves model performance and allows for efficient computation of the exact sample log probability. Subsequently, we propose a general constrained sampling framework that enables controlled trajectory sampling based on differentiable cost functions. This strategy enables a host of applications such as enforcing rules and physical priors, or creating tailored simulation scenarios. MotionDiffuser can be combined with existing backbone architectures to achieve top motion forecasting results. We obtain state-of-the-art results for multi-agent motion prediction on the Waymo Open Motion Dataset.
JFP: Joint Future Prediction with Interactive Multi-Agent Modeling for Autonomous Driving
Dec 16, 2022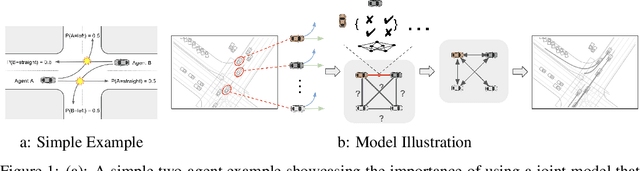
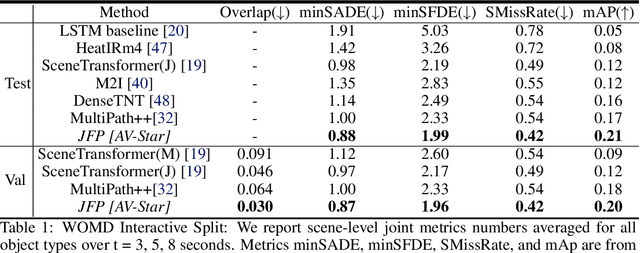
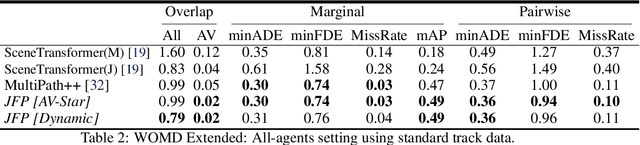
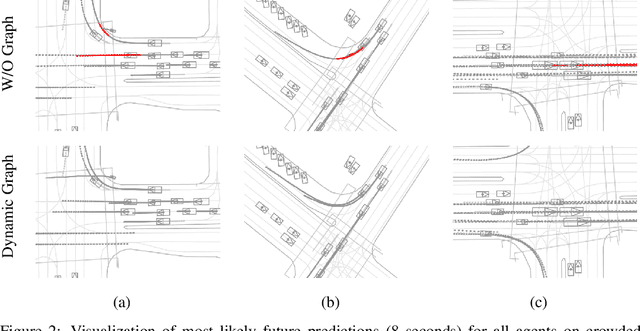
We propose JFP, a Joint Future Prediction model that can learn to generate accurate and consistent multi-agent future trajectories. For this task, many different methods have been proposed to capture social interactions in the encoding part of the model, however, considerably less focus has been placed on representing interactions in the decoder and output stages. As a result, the predicted trajectories are not necessarily consistent with each other, and often result in unrealistic trajectory overlaps. In contrast, we propose an end-to-end trainable model that learns directly the interaction between pairs of agents in a structured, graphical model formulation in order to generate consistent future trajectories. It sets new state-of-the-art results on Waymo Open Motion Dataset (WOMD) for the interactive setting. We also investigate a more complex multi-agent setting for both WOMD and a larger internal dataset, where our approach improves significantly on the trajectory overlap metrics while obtaining on-par or better performance on single-agent trajectory metrics.
Multi-modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving
Dec 22, 2021
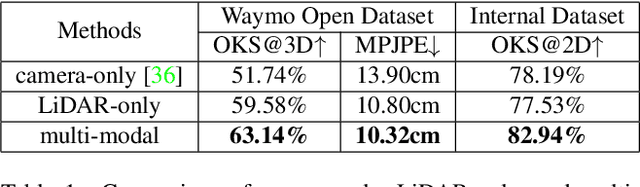
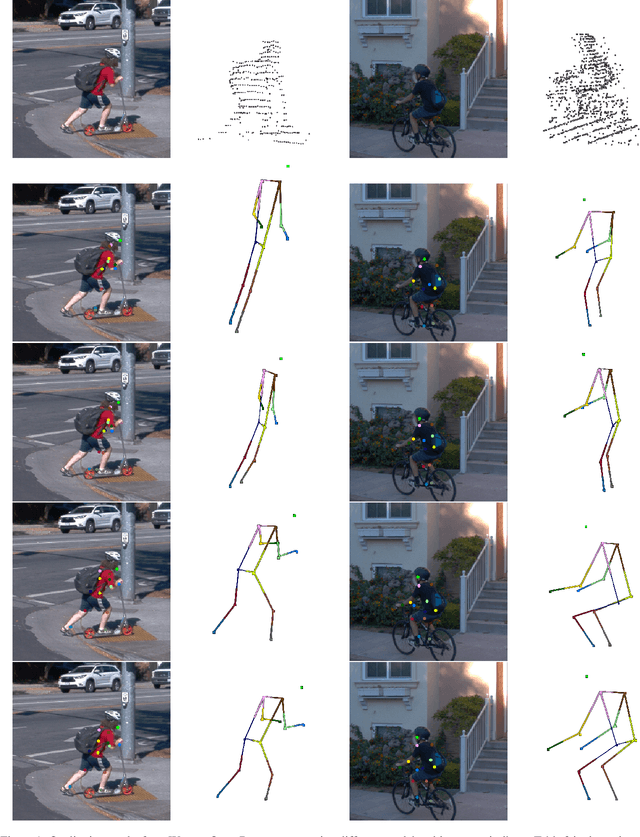
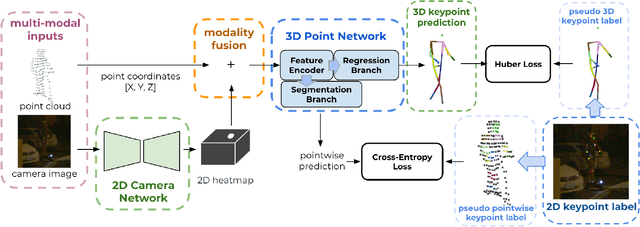
3D human pose estimation (HPE) in autonomous vehicles (AV) differs from other use cases in many factors, including the 3D resolution and range of data, absence of dense depth maps, failure modes for LiDAR, relative location between the camera and LiDAR, and a high bar for estimation accuracy. Data collected for other use cases (such as virtual reality, gaming, and animation) may therefore not be usable for AV applications. This necessitates the collection and annotation of a large amount of 3D data for HPE in AV, which is time-consuming and expensive. In this paper, we propose one of the first approaches to alleviate this problem in the AV setting. Specifically, we propose a multi-modal approach which uses 2D labels on RGB images as weak supervision to perform 3D HPE. The proposed multi-modal architecture incorporates LiDAR and camera inputs with an auxiliary segmentation branch. On the Waymo Open Dataset, our approach achieves a 22% relative improvement over camera-only 2D HPE baseline, and 6% improvement over LiDAR-only model. Finally, careful ablation studies and parts based analysis illustrate the advantages of each of our contributions.
MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction
Dec 22, 2021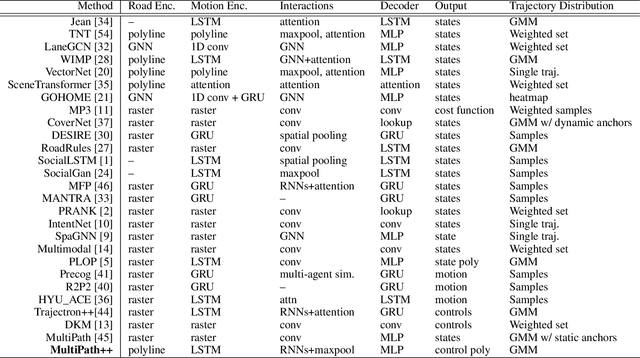
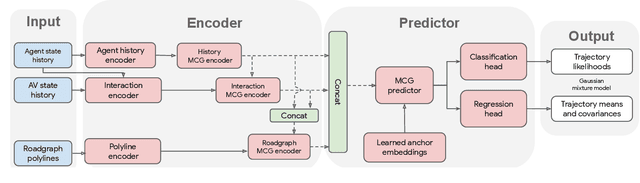
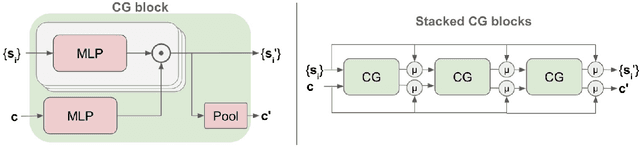
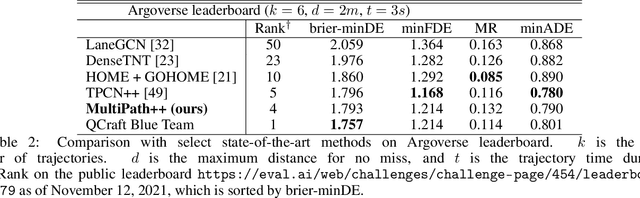
Predicting the future behavior of road users is one of the most challenging and important problems in autonomous driving. Applying deep learning to this problem requires fusing heterogeneous world state in the form of rich perception signals and map information, and inferring highly multi-modal distributions over possible futures. In this paper, we present MultiPath++, a future prediction model that achieves state-of-the-art performance on popular benchmarks. MultiPath++ improves the MultiPath architecture by revisiting many design choices. The first key design difference is a departure from dense image-based encoding of the input world state in favor of a sparse encoding of heterogeneous scene elements: MultiPath++ consumes compact and efficient polylines to describe road features, and raw agent state information directly (e.g., position, velocity, acceleration). We propose a context-aware fusion of these elements and develop a reusable multi-context gating fusion component. Second, we reconsider the choice of pre-defined, static anchors, and develop a way to learn latent anchor embeddings end-to-end in the model. Lastly, we explore ensembling and output aggregation techniques -- common in other ML domains -- and find effective variants for our probabilistic multimodal output representation. We perform an extensive ablation on these design choices, and show that our proposed model achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition and the Waymo Open Dataset Motion Prediction Challenge.