 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving
Dec 22, 2021
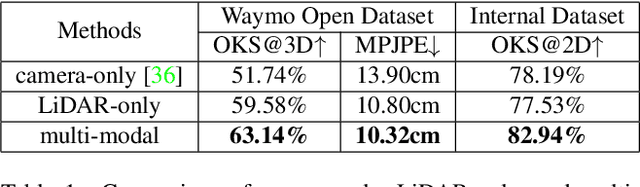
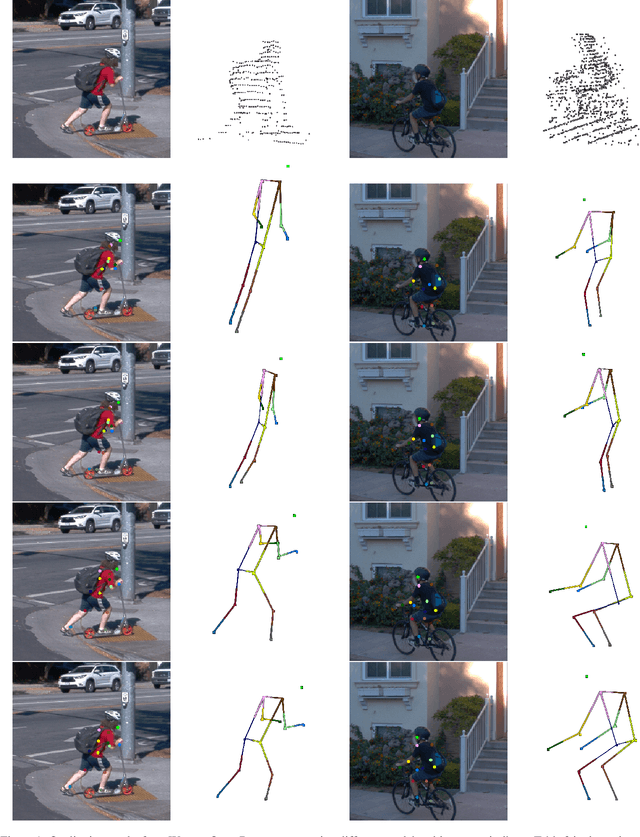
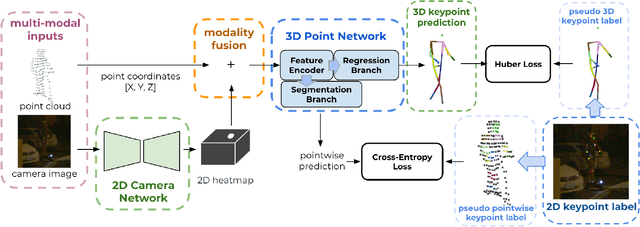
3D human pose estimation (HPE) in autonomous vehicles (AV) differs from other use cases in many factors, including the 3D resolution and range of data, absence of dense depth maps, failure modes for LiDAR, relative location between the camera and LiDAR, and a high bar for estimation accuracy. Data collected for other use cases (such as virtual reality, gaming, and animation) may therefore not be usable for AV applications. This necessitates the collection and annotation of a large amount of 3D data for HPE in AV, which is time-consuming and expensive. In this paper, we propose one of the first approaches to alleviate this problem in the AV setting. Specifically, we propose a multi-modal approach which uses 2D labels on RGB images as weak supervision to perform 3D HPE. The proposed multi-modal architecture incorporates LiDAR and camera inputs with an auxiliary segmentation branch. On the Waymo Open Dataset, our approach achieves a 22% relative improvement over camera-only 2D HPE baseline, and 6% improvement over LiDAR-only model. Finally, careful ablation studies and parts based analysis illustrate the advantages of each of our contributions.
Multi-Hypothesis Pose Networks: Rethinking Top-Down Pose Estimation
Jan 27, 2021
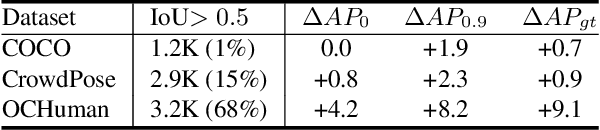
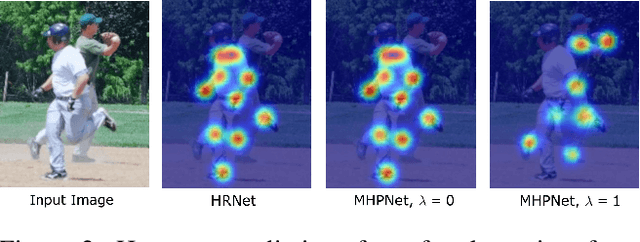
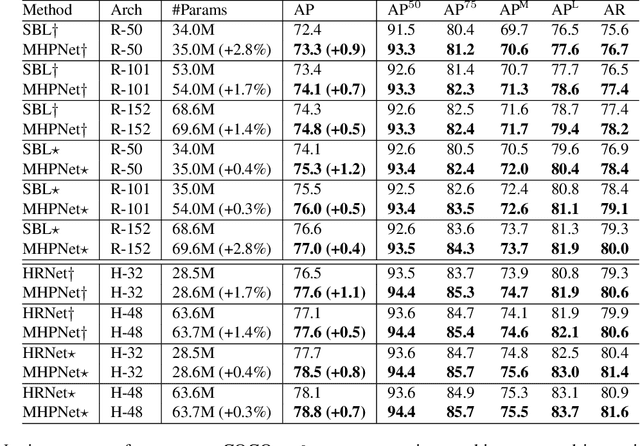
A key assumption of top-down human pose estimation approaches is their expectation of having a single person present in the input bounding box. This often leads to failures in crowded scenes with occlusions. We propose a novel solution to overcome the limitations of this fundamental assumption. Our Multi-Hypothesis Pose Network (MHPNet) allows for predicting multiple 2D poses within a given bounding box. We introduce a Multi-Hypothesis Attention Block (MHAB) that can adaptively modulate channel-wise feature responses for each hypothesis and is parameter efficient. We demonstrate the efficacy of our approach by evaluating on COCO, CrowdPose, and OCHuman datasets. Specifically, we achieve 70.0 AP on CrowdPose and 42.5 AP on OCHuman test sets, a significant improvement of 2.4 AP and 6.5 AP over the prior art, respectively. When using ground truth bounding boxes for inference, MHPNet achieves an improvement of 0.7 AP on COCO, 0.9 AP on CrowdPose, and 9.1 AP on OCHuman validation sets compared to HRNet. Interestingly, when fewer, high confidence bounding boxes are used, HRNet's performance degrades (by 5 AP) on OCHuman, whereas MHPNet maintains a relatively stable performance (a drop of 1 AP) for the same inputs.
Learning to Generate Synthetic Data via Compositing
Apr 10, 2019

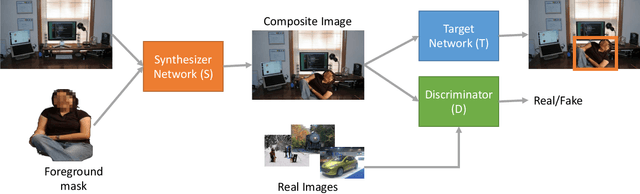
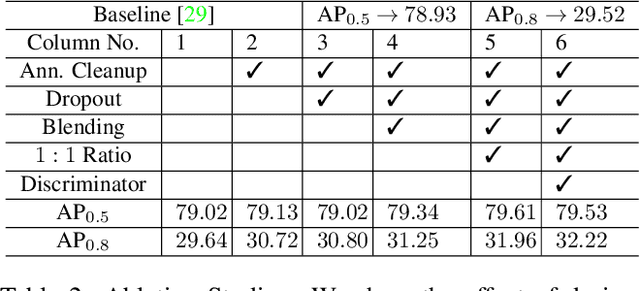
We present a task-aware approach to synthetic data generation. Our framework employs a trainable synthesizer network that is optimized to produce meaningful training samples by assessing the strengths and weaknesses of a `target' network. The synthesizer and target networks are trained in an adversarial manner wherein each network is updated with a goal to outdo the other. Additionally, we ensure the synthesizer generates realistic data by pairing it with a discriminator trained on real-world images. Further, to make the target classifier invariant to blending artefacts, we introduce these artefacts to background regions of the training images so the target does not over-fit to them. We demonstrate the efficacy of our approach by applying it to different target networks including a classification network on AffNIST, and two object detection networks (SSD, Faster-RCNN) on different datasets. On the AffNIST benchmark, our approach is able to surpass the baseline results with just half the training examples. On the VOC person detection benchmark, we show improvements of up to 2.7% as a result of our data augmentation. Similarly on the GMU detection benchmark, we report a performance boost of 3.5% in mAP over the baseline method, outperforming the previous state of the art approaches by up to 7.5% on specific categories.
A Unified View-Graph Selection Framework for Structure from Motion
Dec 04, 2017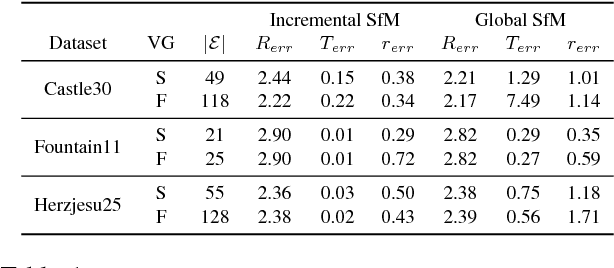

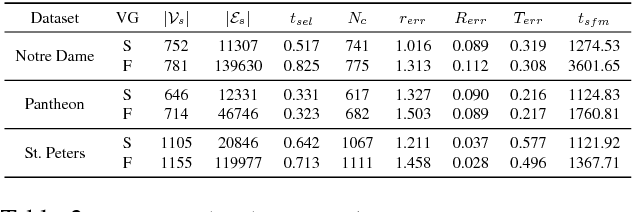
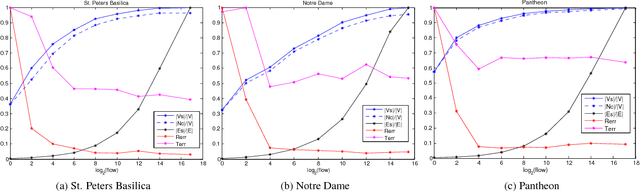
View-graph is an essential input to large-scale structure from motion (SfM) pipelines. Accuracy and efficiency of large-scale SfM is crucially dependent on the input view-graph. Inconsistent or inaccurate edges can lead to inferior or wrong reconstruction. Most SfM methods remove `undesirable' images and pairs using several, fixed heuristic criteria, and propose tailor-made solutions to achieve specific reconstruction objectives such as efficiency, accuracy, or disambiguation. In contrast to these disparate solutions, we propose a single optimization framework that can be used to achieve these different reconstruction objectives with task-specific cost modeling. We also construct a very efficient network-flow based formulation for its approximate solution. The abstraction brought on by this selection mechanism separates the challenges specific to datasets and reconstruction objectives from the standard SfM pipeline and improves its generalization. This paper demonstrates the application of the proposed view-graph framework with standard SfM pipeline for two particular use-cases, (i) accurate and ghost-free reconstructions of highly ambiguous datasets using costs based on disambiguation priors, and (ii) accurate and efficient reconstruction of large-scale Internet datasets using costs based on commonly used priors.
On Pairwise Costs for Network Flow Multi-Object Tracking
May 05, 2015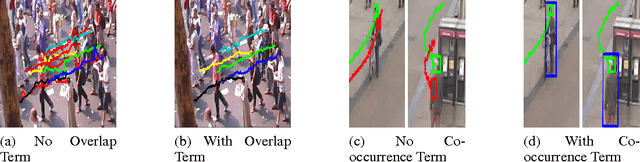
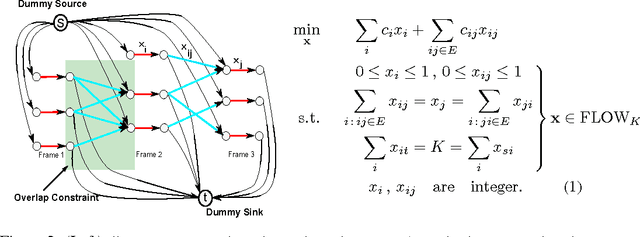
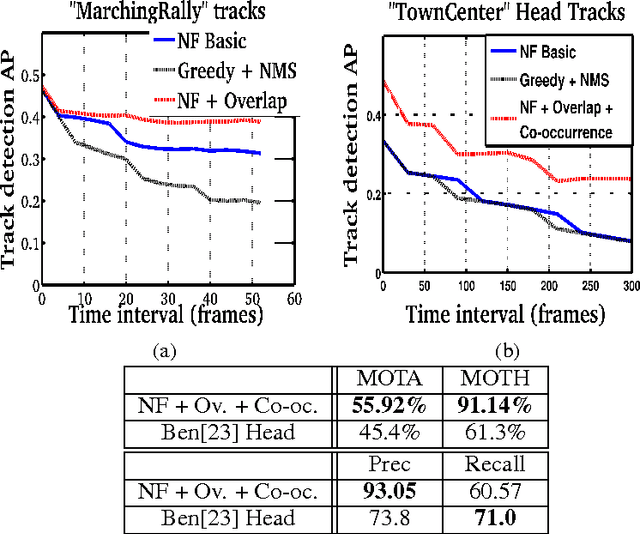
Multi-object tracking has been recently approached with the min-cost network flow optimization techniques. Such methods simultaneously resolve multiple object tracks in a video and enable modeling of dependencies among tracks. Min-cost network flow methods also fit well within the "tracking-by-detection" paradigm where object trajectories are obtained by connecting per-frame outputs of an object detector. Object detectors, however, often fail due to occlusions and clutter in the video. To cope with such situations, we propose to add pairwise costs to the min-cost network flow framework. While integer solutions to such a problem become NP-hard, we design a convex relaxation solution with an efficient rounding heuristic which empirically gives certificates of small suboptimality. We evaluate two particular types of pairwise costs and demonstrate improvements over recent tracking methods in real-world video sequences.
Dynamic Body VSLAM with Semantic Constraints
Apr 27, 2015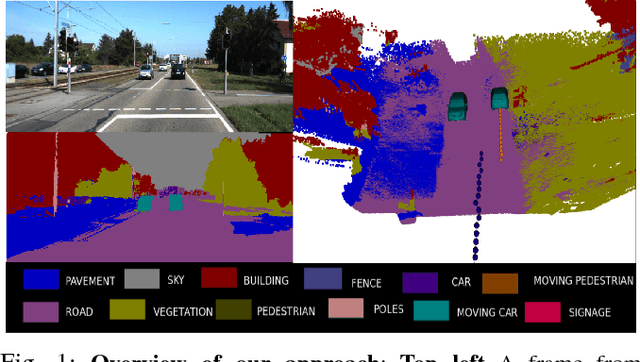

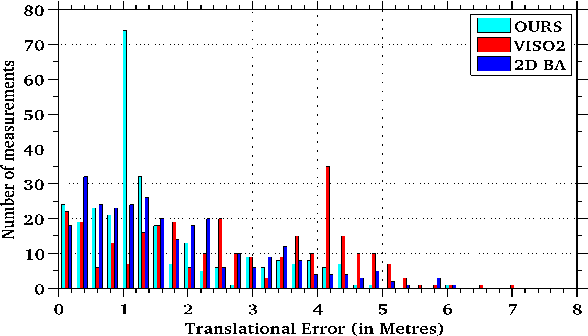
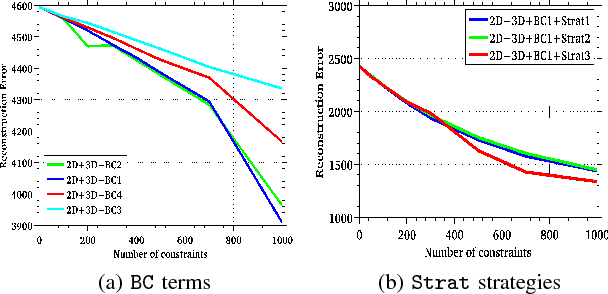
Image based reconstruction of urban environments is a challenging problem that deals with optimization of large number of variables, and has several sources of errors like the presence of dynamic objects. Since most large scale approaches make the assumption of observing static scenes, dynamic objects are relegated to the noise modeling section of such systems. This is an approach of convenience since the RANSAC based framework used to compute most multiview geometric quantities for static scenes naturally confine dynamic objects to the class of outlier measurements. However, reconstructing dynamic objects along with the static environment helps us get a complete picture of an urban environment. Such understanding can then be used for important robotic tasks like path planning for autonomous navigation, obstacle tracking and avoidance, and other areas. In this paper, we propose a system for robust SLAM that works in both static and dynamic environments. To overcome the challenge of dynamic objects in the scene, we propose a new model to incorporate semantic constraints into the reconstruction algorithm. While some of these constraints are based on multi-layered dense CRFs trained over appearance as well as motion cues, other proposed constraints can be expressed as additional terms in the bundle adjustment optimization process that does iterative refinement of 3D structure and camera / object motion trajectories. We show results on the challenging KITTI urban dataset for accuracy of motion segmentation and reconstruction of the trajectory and shape of moving objects relative to ground truth. We are able to show average relative error reduction by a significant amount for moving object trajectory reconstruction relative to state-of-the-art methods like VISO 2, as well as standard bundle adjustment algorithms.