 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSapiens2
Apr 23, 2026We present Sapiens2, a model family of high-resolution transformers for human-centric vision focused on generalization, versatility, and high-fidelity outputs. Our model sizes range from 0.4 to 5 billion parameters, with native 1K resolution and hierarchical variants that support 4K. Sapiens2 substantially improves over its predecessor in both pretraining and post-training. First, to learn features that capture low-level details (for dense prediction) and high-level semantics (for zero-shot or few-label settings), we combine masked image reconstruction with self-distilled contrastive objectives. Our evaluations show that this unified pretraining objective is better suited for a wider range of downstream tasks. Second, along the data axis, we pretrain on a curated dataset of 1 billion high-quality human images and improve the quality and quantity of task annotations. Third, architecturally, we incorporate advances from frontier models that enable longer training schedules with improved stability. Our 4K models adopt windowed attention to reason over longer spatial context and are pretrained with 2K output resolution. Sapiens2 sets a new state-of-the-art and improves over the first generation on pose (+4 mAP), body-part segmentation (+24.3 mIoU), normal estimation (45.6% lower angular error) and extends to new tasks such as pointmap and albedo estimation. Code: https://github.com/facebookresearch/sapiens2
GenLCA: 3D Diffusion for Full-Body Avatars from In-the-Wild Videos
Apr 09, 2026We present GenLCA, a diffusion-based generative model for generating and editing photorealistic full-body avatars from text and image inputs. The generated avatars are faithful to the inputs, while supporting high-fidelity facial and full-body animations. The core idea is a novel paradigm that enables training a full-body 3D diffusion model from partially observable 2D data, allowing the training dataset to scale to millions of real-world videos. This scalability contributes to the superior photorealism and generalizability of GenLCA. Specifically, we scale up the dataset by repurposing a pretrained feed-forward avatar reconstruction model as an animatable 3D tokenizer, which encodes unstructured video frames into structured 3D tokens. However, most real-world videos only provide partial observations of body parts, resulting in excessive blurring or transparency artifacts in the 3D tokens. To address this, we propose a novel visibility-aware diffusion training strategy that replaces invalid regions with learnable tokens and computes losses only over valid regions. We then train a flow-based diffusion model on the token dataset, inherently maintaining the photorealism and animatability provided by the pretrained avatar reconstruction model. Our approach effectively enables the use of large-scale real-world video data to train a diffusion model natively in 3D. We demonstrate the efficacy of our method through diverse and high-fidelity generation and editing results, outperforming existing solutions by a large margin. The project page is available at https://onethousandwu.com/GenLCA-Page.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
DuoMo: Dual Motion Diffusion for World-Space Human Reconstruction
Mar 03, 2026We present DuoMo, a generative method that recovers human motion in world-space coordinates from unconstrained videos with noisy or incomplete observations. Reconstructing such motion requires solving a fundamental trade-off: generalizing from diverse and noisy video inputs while maintaining global motion consistency. Our approach addresses this problem by factorizing motion learning into two diffusion models. The camera-space model first estimates motion from videos in camera coordinates. The world-space model then lifts this initial estimate into world coordinates and refines it to be globally consistent. Together, the two models can reconstruct motion across diverse scenes and trajectories, even from highly noisy or incomplete observations. Moreover, our formulation is general, generating the motion of mesh vertices directly and bypassing parametric models. DuoMo achieves state-of-the-art performance. On EMDB, our method obtains a 16% reduction in world-space reconstruction error while maintaining low foot skating. On RICH, it obtains a 30% reduction in world-space error. Project page: https://yufu-wang.github.io/duomo/
Capture, Canonicalize, Splat: Zero-Shot 3D Gaussian Avatars from Unstructured Phone Images
Oct 15, 2025We present a novel, zero-shot pipeline for creating hyperrealistic, identity-preserving 3D avatars from a few unstructured phone images. Existing methods face several challenges: single-view approaches suffer from geometric inconsistencies and hallucinations, degrading identity preservation, while models trained on synthetic data fail to capture high-frequency details like skin wrinkles and fine hair, limiting realism. Our method introduces two key contributions: (1) a generative canonicalization module that processes multiple unstructured views into a standardized, consistent representation, and (2) a transformer-based model trained on a new, large-scale dataset of high-fidelity Gaussian splatting avatars derived from dome captures of real people. This "Capture, Canonicalize, Splat" pipeline produces static quarter-body avatars with compelling realism and robust identity preservation from unstructured photos.
Pippo: High-Resolution Multi-View Humans from a Single Image
Feb 11, 2025
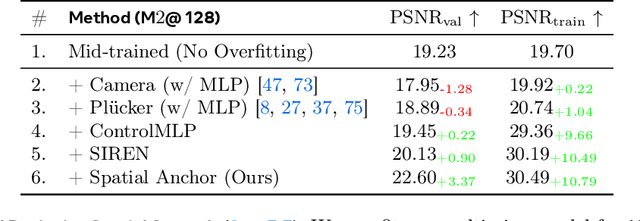
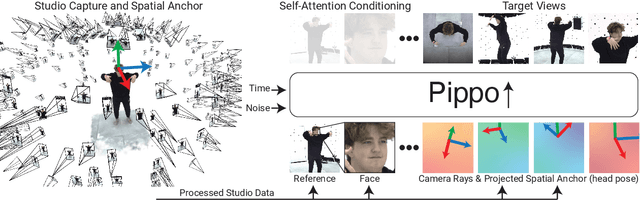

We present Pippo, a generative model capable of producing 1K resolution dense turnaround videos of a person from a single casually clicked photo. Pippo is a multi-view diffusion transformer and does not require any additional inputs - e.g., a fitted parametric model or camera parameters of the input image. We pre-train Pippo on 3B human images without captions, and conduct multi-view mid-training and post-training on studio captured humans. During mid-training, to quickly absorb the studio dataset, we denoise several (up to 48) views at low-resolution, and encode target cameras coarsely using a shallow MLP. During post-training, we denoise fewer views at high-resolution and use pixel-aligned controls (e.g., Spatial anchor and Plucker rays) to enable 3D consistent generations. At inference, we propose an attention biasing technique that allows Pippo to simultaneously generate greater than 5 times as many views as seen during training. Finally, we also introduce an improved metric to evaluate 3D consistency of multi-view generations, and show that Pippo outperforms existing works on multi-view human generation from a single image.
URAvatar: Universal Relightable Gaussian Codec Avatars
Oct 31, 2024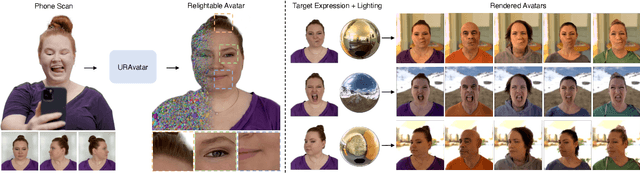

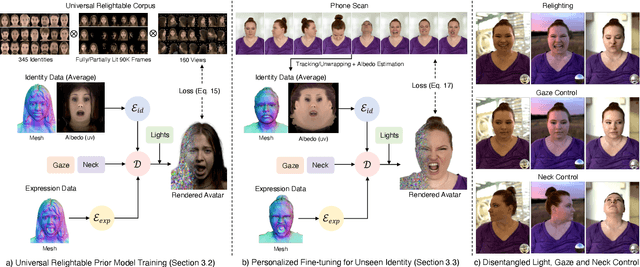
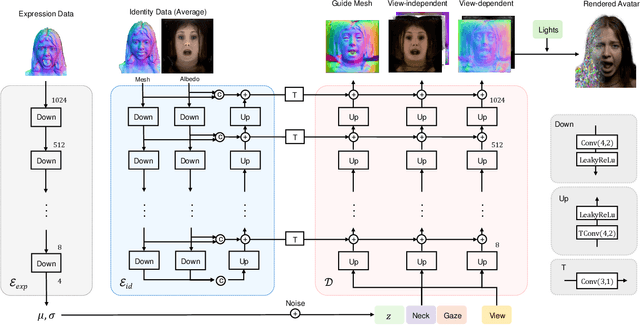
We present a new approach to creating photorealistic and relightable head avatars from a phone scan with unknown illumination. The reconstructed avatars can be animated and relit in real time with the global illumination of diverse environments. Unlike existing approaches that estimate parametric reflectance parameters via inverse rendering, our approach directly models learnable radiance transfer that incorporates global light transport in an efficient manner for real-time rendering. However, learning such a complex light transport that can generalize across identities is non-trivial. A phone scan in a single environment lacks sufficient information to infer how the head would appear in general environments. To address this, we build a universal relightable avatar model represented by 3D Gaussians. We train on hundreds of high-quality multi-view human scans with controllable point lights. High-resolution geometric guidance further enhances the reconstruction accuracy and generalization. Once trained, we finetune the pretrained model on a phone scan using inverse rendering to obtain a personalized relightable avatar. Our experiments establish the efficacy of our design, outperforming existing approaches while retaining real-time rendering capability.
Harmony4D: A Video Dataset for In-The-Wild Close Human Interactions
Oct 27, 2024



Understanding how humans interact with each other is key to building realistic multi-human virtual reality systems. This area remains relatively unexplored due to the lack of large-scale datasets. Recent datasets focusing on this issue mainly consist of activities captured entirely in controlled indoor environments with choreographed actions, significantly affecting their diversity. To address this, we introduce Harmony4D, a multi-view video dataset for human-human interaction featuring in-the-wild activities such as wrestling, dancing, MMA, and more. We use a flexible multi-view capture system to record these dynamic activities and provide annotations for human detection, tracking, 2D/3D pose estimation, and mesh recovery for closely interacting subjects. We propose a novel markerless algorithm to track 3D human poses in severe occlusion and close interaction to obtain our annotations with minimal manual intervention. Harmony4D consists of 1.66 million images and 3.32 million human instances from more than 20 synchronized cameras with 208 video sequences spanning diverse environments and 24 unique subjects. We rigorously evaluate existing state-of-the-art methods for mesh recovery and highlight their significant limitations in modeling close interaction scenarios. Additionally, we fine-tune a pre-trained HMR2.0 model on Harmony4D and demonstrate an improved performance of 54.8% PVE in scenes with severe occlusion and contact. Code and data are available at https://jyuntins.github.io/harmony4d/.
Sapiens: Foundation for Human Vision Models
Aug 22, 2024



We present Sapiens, a family of models for four fundamental human-centric vision tasks - 2D pose estimation, body-part segmentation, depth estimation, and surface normal prediction. Our models natively support 1K high-resolution inference and are extremely easy to adapt for individual tasks by simply fine-tuning models pretrained on over 300 million in-the-wild human images. We observe that, given the same computational budget, self-supervised pretraining on a curated dataset of human images significantly boosts the performance for a diverse set of human-centric tasks. The resulting models exhibit remarkable generalization to in-the-wild data, even when labeled data is scarce or entirely synthetic. Our simple model design also brings scalability - model performance across tasks improves as we scale the number of parameters from 0.3 to 2 billion. Sapiens consistently surpasses existing baselines across various human-centric benchmarks. We achieve significant improvements over the prior state-of-the-art on Humans-5K (pose) by 7.6 mAP, Humans-2K (part-seg) by 17.1 mIoU, Hi4D (depth) by 22.4% relative RMSE, and THuman2 (normal) by 53.5% relative angular error.
Generalizable Neural Human Renderer
Apr 22, 2024While recent advancements in animatable human rendering have achieved remarkable results, they require test-time optimization for each subject which can be a significant limitation for real-world applications. To address this, we tackle the challenging task of learning a Generalizable Neural Human Renderer (GNH), a novel method for rendering animatable humans from monocular video without any test-time optimization. Our core method focuses on transferring appearance information from the input video to the output image plane by utilizing explicit body priors and multi-view geometry. To render the subject in the intended pose, we utilize a straightforward CNN-based image renderer, foregoing the more common ray-sampling or rasterizing-based rendering modules. Our GNH achieves remarkable generalizable, photorealistic rendering with unseen subjects with a three-stage process. We quantitatively and qualitatively demonstrate that GNH significantly surpasses current state-of-the-art methods, notably achieving a 31.3% improvement in LPIPS.