 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround Reaction Inertial Poser: Physics-based Human Motion Capture from Sparse IMUs and Insole Pressure Sensors
Mar 17, 2026We propose Ground Reaction Inertial Poser (GRIP), a method that reconstructs physically plausible human motion using four wearable devices. Unlike conventional IMU-only approaches, GRIP combines IMU signals with foot pressure data to capture both body dynamics and ground interactions. Furthermore, rather than relying solely on kinematic estimation, GRIP uses a digital twin of a person, in the form of a synthetic humanoid in a physics simulator, to reconstruct realistic and physically plausible motion. At its core, GRIP consists of two modules: KinematicsNet, which estimates body poses and velocities from sensor data, and DynamicsNet, which controls the humanoid in the simulator using the residual between the KinematicsNet prediction and the simulated humanoid state. To enable robust training and fair evaluation, we introduce a large-scale dataset, Pressure and Inertial Sensing for Human Motion and Interaction (PRISM), that captures diverse human motions with synchronized IMUs and insole pressure sensors. Experimental results show that GRIP outperforms existing IMU-only and IMU-pressure fusion methods across all evaluated datasets, achieving higher global pose accuracy and improved physical consistency.
SAM 3D Body: Robust Full-Body Human Mesh Recovery
Feb 17, 2026We introduce SAM 3D Body (3DB), a promptable model for single-image full-body 3D human mesh recovery (HMR) that demonstrates state-of-the-art performance, with strong generalization and consistent accuracy in diverse in-the-wild conditions. 3DB estimates the human pose of the body, feet, and hands. It is the first model to use a new parametric mesh representation, Momentum Human Rig (MHR), which decouples skeletal structure and surface shape. 3DB employs an encoder-decoder architecture and supports auxiliary prompts, including 2D keypoints and masks, enabling user-guided inference similar to the SAM family of models. We derive high-quality annotations from a multi-stage annotation pipeline that uses various combinations of manual keypoint annotation, differentiable optimization, multi-view geometry, and dense keypoint detection. Our data engine efficiently selects and processes data to ensure data diversity, collecting unusual poses and rare imaging conditions. We present a new evaluation dataset organized by pose and appearance categories, enabling nuanced analysis of model behavior. Our experiments demonstrate superior generalization and substantial improvements over prior methods in both qualitative user preference studies and traditional quantitative analysis. Both 3DB and MHR are open-source.
CacheFlow: Fast Human Motion Prediction by Cached Normalizing Flow
May 19, 2025Many density estimation techniques for 3D human motion prediction require a significant amount of inference time, often exceeding the duration of the predicted time horizon. To address the need for faster density estimation for 3D human motion prediction, we introduce a novel flow-based method for human motion prediction called CacheFlow. Unlike previous conditional generative models that suffer from time efficiency, CacheFlow takes advantage of an unconditional flow-based generative model that transforms a Gaussian mixture into the density of future motions. The results of the computation of the flow-based generative model can be precomputed and cached. Then, for conditional prediction, we seek a mapping from historical trajectories to samples in the Gaussian mixture. This mapping can be done by a much more lightweight model, thus saving significant computation overhead compared to a typical conditional flow model. In such a two-stage fashion and by caching results from the slow flow model computation, we build our CacheFlow without loss of prediction accuracy and model expressiveness. This inference process is completed in approximately one millisecond, making it 4 times faster than previous VAE methods and 30 times faster than previous diffusion-based methods on standard benchmarks such as Human3.6M and AMASS datasets. Furthermore, our method demonstrates improved density estimation accuracy and comparable prediction accuracy to a SOTA method on Human3.6M. Our code and models will be publicly available.
GENMO: A GENeralist Model for Human MOtion
May 02, 2025



Human motion modeling traditionally separates motion generation and estimation into distinct tasks with specialized models. Motion generation models focus on creating diverse, realistic motions from inputs like text, audio, or keyframes, while motion estimation models aim to reconstruct accurate motion trajectories from observations like videos. Despite sharing underlying representations of temporal dynamics and kinematics, this separation limits knowledge transfer between tasks and requires maintaining separate models. We present GENMO, a unified Generalist Model for Human Motion that bridges motion estimation and generation in a single framework. Our key insight is to reformulate motion estimation as constrained motion generation, where the output motion must precisely satisfy observed conditioning signals. Leveraging the synergy between regression and diffusion, GENMO achieves accurate global motion estimation while enabling diverse motion generation. We also introduce an estimation-guided training objective that exploits in-the-wild videos with 2D annotations and text descriptions to enhance generative diversity. Furthermore, our novel architecture handles variable-length motions and mixed multimodal conditions (text, audio, video) at different time intervals, offering flexible control. This unified approach creates synergistic benefits: generative priors improve estimated motions under challenging conditions like occlusions, while diverse video data enhances generation capabilities. Extensive experiments demonstrate GENMO's effectiveness as a generalist framework that successfully handles multiple human motion tasks within a single model.
Harmony4D: A Video Dataset for In-The-Wild Close Human Interactions
Oct 27, 2024



Understanding how humans interact with each other is key to building realistic multi-human virtual reality systems. This area remains relatively unexplored due to the lack of large-scale datasets. Recent datasets focusing on this issue mainly consist of activities captured entirely in controlled indoor environments with choreographed actions, significantly affecting their diversity. To address this, we introduce Harmony4D, a multi-view video dataset for human-human interaction featuring in-the-wild activities such as wrestling, dancing, MMA, and more. We use a flexible multi-view capture system to record these dynamic activities and provide annotations for human detection, tracking, 2D/3D pose estimation, and mesh recovery for closely interacting subjects. We propose a novel markerless algorithm to track 3D human poses in severe occlusion and close interaction to obtain our annotations with minimal manual intervention. Harmony4D consists of 1.66 million images and 3.32 million human instances from more than 20 synchronized cameras with 208 video sequences spanning diverse environments and 24 unique subjects. We rigorously evaluate existing state-of-the-art methods for mesh recovery and highlight their significant limitations in modeling close interaction scenarios. Additionally, we fine-tune a pre-trained HMR2.0 model on Harmony4D and demonstrate an improved performance of 54.8% PVE in scenes with severe occlusion and contact. Code and data are available at https://jyuntins.github.io/harmony4d/.
Multi-Modal Diffusion for Hand-Object Grasp Generation
Sep 06, 2024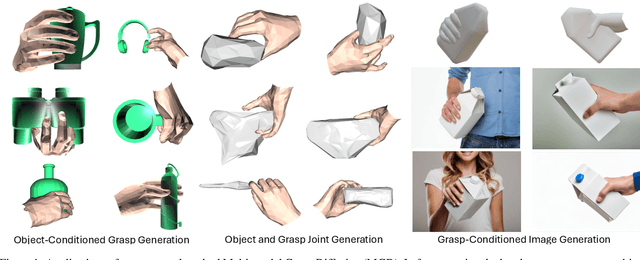
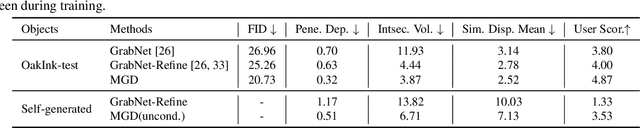


In this work, we focus on generating hand grasp over objects. Compared to previous works of generating hand poses with a given object, we aim to allow the generalization of both hand and object shapes by a single model. Our proposed method Multi-modal Grasp Diffusion (MGD) learns the prior and conditional posterior distribution of both modalities from heterogeneous data sources. Therefore it relieves the limitation of hand-object grasp datasets by leveraging the large-scale 3D object datasets. According to both qualitative and quantitative experiments, both conditional and unconditional generation of hand grasp achieve good visual plausibility and diversity. The proposed method also generalizes well to unseen object shapes. The code and weights will be available at \url{https://github.com/noahcao/mgd}.
Grasping Diverse Objects with Simulated Humanoids
Jul 16, 2024We present a method for controlling a simulated humanoid to grasp an object and move it to follow an object trajectory. Due to the challenges in controlling a humanoid with dexterous hands, prior methods often use a disembodied hand and only consider vertical lifts or short trajectories. This limited scope hampers their applicability for object manipulation required for animation and simulation. To close this gap, we learn a controller that can pick up a large number (>1200) of objects and carry them to follow randomly generated trajectories. Our key insight is to leverage a humanoid motion representation that provides human-like motor skills and significantly speeds up training. Using only simplistic reward, state, and object representations, our method shows favorable scalability on diverse object and trajectories. For training, we do not need dataset of paired full-body motion and object trajectories. At test time, we only require the object mesh and desired trajectories for grasping and transporting. To demonstrate the capabilities of our method, we show state-of-the-art success rates in following object trajectories and generalizing to unseen objects. Code and models will be released.
SMPLOlympics: Sports Environments for Physically Simulated Humanoids
Jun 28, 2024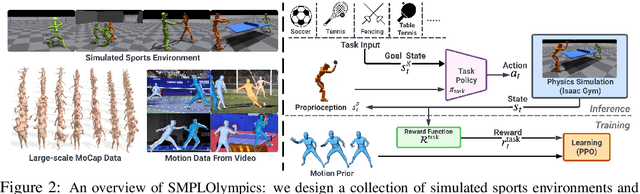
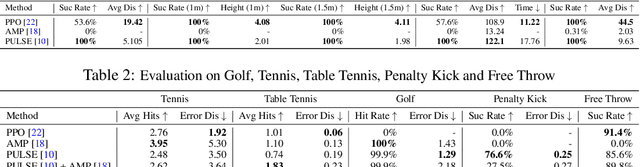

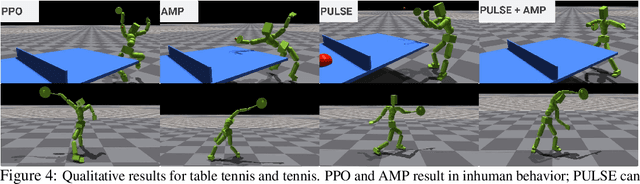
We present SMPLOlympics, a collection of physically simulated environments that allow humanoids to compete in a variety of Olympic sports. Sports simulation offers a rich and standardized testing ground for evaluating and improving the capabilities of learning algorithms due to the diversity and physically demanding nature of athletic activities. As humans have been competing in these sports for many years, there is also a plethora of existing knowledge on the preferred strategy to achieve better performance. To leverage these existing human demonstrations from videos and motion capture, we design our humanoid to be compatible with the widely-used SMPL and SMPL-X human models from the vision and graphics community. We provide a suite of individual sports environments, including golf, javelin throw, high jump, long jump, and hurdling, as well as competitive sports, including both 1v1 and 2v2 games such as table tennis, tennis, fencing, boxing, soccer, and basketball. Our analysis shows that combining strong motion priors with simple rewards can result in human-like behavior in various sports. By providing a unified sports benchmark and baseline implementation of state and reward designs, we hope that SMPLOlympics can help the control and animation communities achieve human-like and performant behaviors.
CooHOI: Learning Cooperative Human-Object Interaction with Manipulated Object Dynamics
Jun 20, 2024
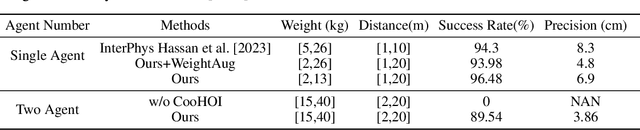
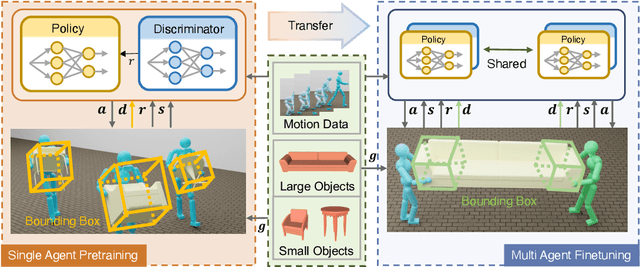
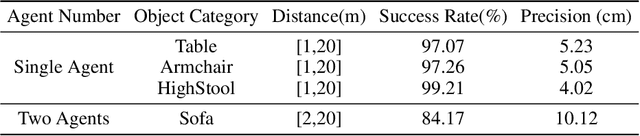
Recent years have seen significant advancements in humanoid control, largely due to the availability of large-scale motion capture data and the application of reinforcement learning methodologies. However, many real-world tasks, such as moving large and heavy furniture, require multi-character collaboration. Given the scarcity of data on multi-character collaboration and the efficiency challenges associated with multi-agent learning, these tasks cannot be straightforwardly addressed using training paradigms designed for single-agent scenarios. In this paper, we introduce Cooperative Human-Object Interaction (CooHOI), a novel framework that addresses multi-character objects transporting through a two-phase learning paradigm: individual skill acquisition and subsequent transfer. Initially, a single agent learns to perform tasks using the Adversarial Motion Priors (AMP) framework. Following this, the agent learns to collaborate with others by considering the shared dynamics of the manipulated object during parallel training using Multi Agent Proximal Policy Optimization (MAPPO). When one agent interacts with the object, resulting in specific object dynamics changes, the other agents learn to respond appropriately, thereby achieving implicit communication and coordination between teammates. Unlike previous approaches that relied on tracking-based methods for multi-character HOI, CooHOI is inherently efficient, does not depend on motion capture data of multi-character interactions, and can be seamlessly extended to include more participants and a wide range of object types
Real-Time Simulated Avatar from Head-Mounted Sensors
Mar 11, 2024



We present SimXR, a method for controlling a simulated avatar from information (headset pose and cameras) obtained from AR / VR headsets. Due to the challenging viewpoint of head-mounted cameras, the human body is often clipped out of view, making traditional image-based egocentric pose estimation challenging. On the other hand, headset poses provide valuable information about overall body motion, but lack fine-grained details about the hands and feet. To synergize headset poses with cameras, we control a humanoid to track headset movement while analyzing input images to decide body movement. When body parts are seen, the movements of hands and feet will be guided by the images; when unseen, the laws of physics guide the controller to generate plausible motion. We design an end-to-end method that does not rely on any intermediate representations and learns to directly map from images and headset poses to humanoid control signals. To train our method, we also propose a large-scale synthetic dataset created using camera configurations compatible with a commercially available VR headset (Quest 2) and show promising results on real-world captures. To demonstrate the applicability of our framework, we also test it on an AR headset with a forward-facing camera.