 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNimbus: A Unified Embodied Synthetic Data Generation Framework
Jan 29, 2026Scaling data volume and diversity is critical for generalizing embodied intelligence. While synthetic data generation offers a scalable alternative to expensive physical data acquisition, existing pipelines remain fragmented and task-specific. This isolation leads to significant engineering inefficiency and system instability, failing to support the sustained, high-throughput data generation required for foundation model training. To address these challenges, we present Nimbus, a unified synthetic data generation framework designed to integrate heterogeneous navigation and manipulation pipelines. Nimbus introduces a modular four-layer architecture featuring a decoupled execution model that separates trajectory planning, rendering, and storage into asynchronous stages. By implementing dynamic pipeline scheduling, global load balancing, distributed fault tolerance, and backend-specific rendering optimizations, the system maximizes resource utilization across CPU, GPU, and I/O resources. Our evaluation demonstrates that Nimbus achieves a 2-3X improvement in end-to-end throughput compared to unoptimized baselines and ensuring robust, long-term operation in large-scale distributed environments. This framework serves as the production backbone for the InternData suite, enabling seamless cross-domain data synthesis.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
VL-LN Bench: Towards Long-horizon Goal-oriented Navigation with Active Dialogs
Dec 31, 2025In most existing embodied navigation tasks, instructions are well-defined and unambiguous, such as instruction following and object searching. Under this idealized setting, agents are required solely to produce effective navigation outputs conditioned on vision and language inputs. However, real-world navigation instructions are often vague and ambiguous, requiring the agent to resolve uncertainty and infer user intent through active dialog. To address this gap, we propose Interactive Instance Object Navigation (IION), a task that requires agents not only to generate navigation actions but also to produce language outputs via active dialog, thereby aligning more closely with practical settings. IION extends Instance Object Navigation (ION) by allowing agents to freely consult an oracle in natural language while navigating. Building on this task, we present the Vision Language-Language Navigation (VL-LN) benchmark, which provides a large-scale, automatically generated dataset and a comprehensive evaluation protocol for training and assessing dialog-enabled navigation models. VL-LN comprises over 41k long-horizon dialog-augmented trajectories for training and an automatic evaluation protocol with an oracle capable of responding to agent queries. Using this benchmark, we train a navigation model equipped with dialog capabilities and show that it achieves significant improvements over the baselines. Extensive experiments and analyses further demonstrate the effectiveness and reliability of VL-LN for advancing research on dialog-enabled embodied navigation. Code and dataset: https://0309hws.github.io/VL-LN.github.io/
LoGoPlanner: Localization Grounded Navigation Policy with Metric-aware Visual Geometry
Dec 23, 2025Trajectory planning in unstructured environments is a fundamental and challenging capability for mobile robots. Traditional modular pipelines suffer from latency and cascading errors across perception, localization, mapping, and planning modules. Recent end-to-end learning methods map raw visual observations directly to control signals or trajectories, promising greater performance and efficiency in open-world settings. However, most prior end-to-end approaches still rely on separate localization modules that depend on accurate sensor extrinsic calibration for self-state estimation, thereby limiting generalization across embodiments and environments. We introduce LoGoPlanner, a localization-grounded, end-to-end navigation framework that addresses these limitations by: (1) finetuning a long-horizon visual-geometry backbone to ground predictions with absolute metric scale, thereby providing implicit state estimation for accurate localization; (2) reconstructing surrounding scene geometry from historical observations to supply dense, fine-grained environmental awareness for reliable obstacle avoidance; and (3) conditioning the policy on implicit geometry bootstrapped by the aforementioned auxiliary tasks, thereby reducing error propagation. We evaluate LoGoPlanner in both simulation and real-world settings, where its fully end-to-end design reduces cumulative error while metric-aware geometry memory enhances planning consistency and obstacle avoidance, leading to more than a 27.3\% improvement over oracle-localization baselines and strong generalization across embodiments and environments. The code and models have been made publicly available on the https://steinate.github.io/logoplanner.github.io.
MMSI-Video-Bench: A Holistic Benchmark for Video-Based Spatial Intelligence
Dec 11, 2025Spatial understanding over continuous visual input is crucial for MLLMs to evolve into general-purpose assistants in physical environments. Yet there is still no comprehensive benchmark that holistically assesses the progress toward this goal. In this work, we introduce MMSI-Video-Bench, a fully human-annotated benchmark for video-based spatial intelligence in MLLMs. It operationalizes a four-level framework, Perception, Planning, Prediction, and Cross-Video Reasoning, through 1,106 questions grounded in 1,278 clips from 25 datasets and in-house videos. Each item is carefully designed and reviewed by 3DV experts with explanatory rationales to ensure precise, unambiguous grounding. Leveraging its diverse data sources and holistic task coverage, MMSI-Video-Bench also supports three domain-oriented sub-benchmarks (Indoor Scene Perception Bench, Robot Bench and Grounding Bench) for targeted capability assessment. We evaluate 25 strong open-source and proprietary MLLMs, revealing a striking human--AI gap: many models perform near chance, and the best reasoning model lags humans by nearly 60%. We further find that spatially fine-tuned models still fail to generalize effectively on our benchmark. Fine-grained error analysis exposes systematic failures in geometric reasoning, motion grounding, long-horizon prediction, and cross-video correspondence. We also show that typical frame-sampling strategies transfer poorly to our reasoning-intensive benchmark, and that neither 3D spatial cues nor chain-of-thought prompting yields meaningful gains. We expect our benchmark to establish a solid testbed for advancing video-based spatial intelligence.
Ground Slow, Move Fast: A Dual-System Foundation Model for Generalizable Vision-and-Language Navigation
Dec 09, 2025While recent large vision-language models (VLMs) have improved generalization in vision-language navigation (VLN), existing methods typically rely on end-to-end pipelines that map vision-language inputs directly to short-horizon discrete actions. Such designs often produce fragmented motions, incur high latency, and struggle with real-world challenges like dynamic obstacle avoidance. We propose DualVLN, the first dual-system VLN foundation model that synergistically integrates high-level reasoning with low-level action execution. System 2, a VLM-based global planner, "grounds slowly" by predicting mid-term waypoint goals via image-grounded reasoning. System 1, a lightweight, multi-modal conditioning Diffusion Transformer policy, "moves fast" by leveraging both explicit pixel goals and latent features from System 2 to generate smooth and accurate trajectories. The dual-system design enables robust real-time control and adaptive local decision-making in complex, dynamic environments. By decoupling training, the VLM retains its generalization, while System 1 achieves interpretable and effective local navigation. DualVLN outperforms prior methods across all VLN benchmarks and real-world experiments demonstrate robust long-horizon planning and real-time adaptability in dynamic environments.
ChangingGrounding: 3D Visual Grounding in Changing Scenes
Oct 16, 2025Real-world robots localize objects from natural-language instructions while scenes around them keep changing. Yet most of the existing 3D visual grounding (3DVG) method still assumes a reconstructed and up-to-date point cloud, an assumption that forces costly re-scans and hinders deployment. We argue that 3DVG should be formulated as an active, memory-driven problem, and we introduce ChangingGrounding, the first benchmark that explicitly measures how well an agent can exploit past observations, explore only where needed, and still deliver precise 3D boxes in changing scenes. To set a strong reference point, we also propose Mem-ChangingGrounder, a zero-shot method for this task that marries cross-modal retrieval with lightweight multi-view fusion: it identifies the object type implied by the query, retrieves relevant memories to guide actions, then explores the target efficiently in the scene, falls back when previous operations are invalid, performs multi-view scanning of the target, and projects the fused evidence from multi-view scans to get accurate object bounding boxes. We evaluate different baselines on ChangingGrounding, and our Mem-ChangingGrounder achieves the highest localization accuracy while greatly reducing exploration cost. We hope this benchmark and method catalyze a shift toward practical, memory-centric 3DVG research for real-world applications. Project page: https://hm123450.github.io/CGB/ .
VFlowOpt: A Token Pruning Framework for LMMs with Visual Information Flow-Guided Optimization
Aug 07, 2025Large Multimodal Models (LMMs) excel in visual-language tasks by leveraging numerous visual tokens for fine-grained visual information, but this token redundancy results in significant computational costs. Previous research aimed at reducing visual tokens during inference typically leverages importance maps derived from attention scores among vision-only tokens or vision-language tokens to prune tokens across one or multiple pruning stages. Despite this progress, pruning frameworks and strategies remain simplistic and insufficiently explored, often resulting in substantial performance degradation. In this paper, we propose VFlowOpt, a token pruning framework that introduces an importance map derivation process and a progressive pruning module with a recycling mechanism. The hyperparameters of its pruning strategy are further optimized by a visual information flow-guided method. Specifically, we compute an importance map for image tokens based on their attention-derived context relevance and patch-level information entropy. We then decide which tokens to retain or prune and aggregate the pruned ones as recycled tokens to avoid potential information loss. Finally, we apply a visual information flow-guided method that regards the last token in the LMM as the most representative signal of text-visual interactions. This method minimizes the discrepancy between token representations in LMMs with and without pruning, thereby enabling superior pruning strategies tailored to different LMMs. Experiments demonstrate that VFlowOpt can prune 90% of visual tokens while maintaining comparable performance, leading to an 89% reduction in KV-Cache memory and 3.8 times faster inference.
InstructVLA: Vision-Language-Action Instruction Tuning from Understanding to Manipulation
Jul 23, 2025To operate effectively in the real world, robots must integrate multimodal reasoning with precise action generation. However, existing vision-language-action (VLA) models often sacrifice one for the other, narrow their abilities to task-specific manipulation data, and suffer catastrophic forgetting of pre-trained vision-language capabilities. To bridge this gap, we introduce InstructVLA, an end-to-end VLA model that preserves the flexible reasoning of large vision-language models (VLMs) while delivering leading manipulation performance. InstructVLA introduces a novel training paradigm, Vision-Language-Action Instruction Tuning (VLA-IT), which employs multimodal training with mixture-of-experts adaptation to jointly optimize textual reasoning and action generation on both standard VLM corpora and a curated 650K-sample VLA-IT dataset. On in-domain SimplerEnv tasks, InstructVLA achieves 30.5% improvement over SpatialVLA. To evaluate generalization, we introduce SimplerEnv-Instruct, an 80-task benchmark requiring closed-loop control and high-level instruction understanding, where it outperforms a fine-tuned OpenVLA by 92% and an action expert aided by GPT-4o by 29%. Additionally, InstructVLA surpasses baseline VLMs on multimodal tasks and exhibits inference-time scaling by leveraging textual reasoning to boost manipulation performance in both simulated and real-world settings. These results demonstrate InstructVLA's potential for bridging intuitive and steerable human-robot interaction with efficient policy learning.
Rethinking the Embodied Gap in Vision-and-Language Navigation: A Holistic Study of Physical and Visual Disparities
Jul 17, 2025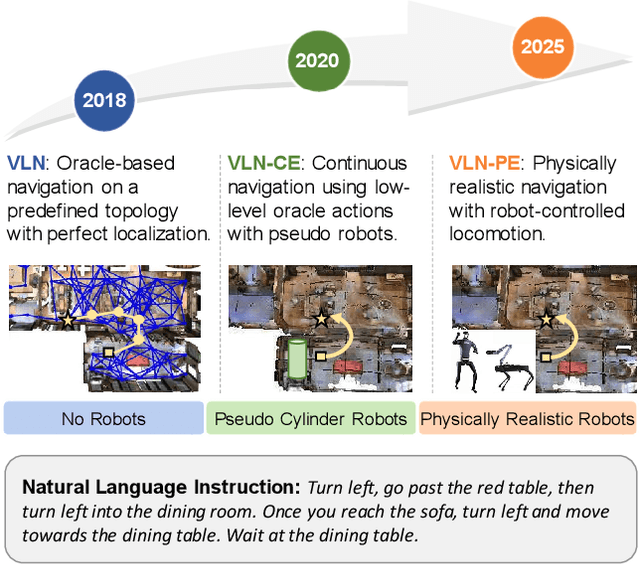
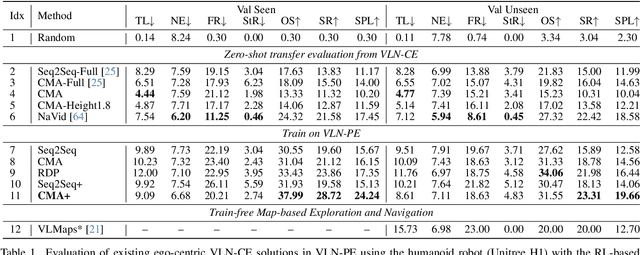
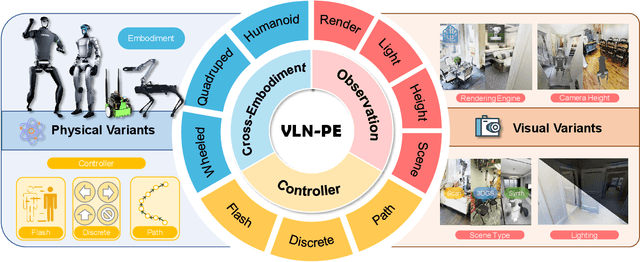

Recent Vision-and-Language Navigation (VLN) advancements are promising, but their idealized assumptions about robot movement and control fail to reflect physically embodied deployment challenges. To bridge this gap, we introduce VLN-PE, a physically realistic VLN platform supporting humanoid, quadruped, and wheeled robots. For the first time, we systematically evaluate several ego-centric VLN methods in physical robotic settings across different technical pipelines, including classification models for single-step discrete action prediction, a diffusion model for dense waypoint prediction, and a train-free, map-based large language model (LLM) integrated with path planning. Our results reveal significant performance degradation due to limited robot observation space, environmental lighting variations, and physical challenges like collisions and falls. This also exposes locomotion constraints for legged robots in complex environments. VLN-PE is highly extensible, allowing seamless integration of new scenes beyond MP3D, thereby enabling more comprehensive VLN evaluation. Despite the weak generalization of current models in physical deployment, VLN-PE provides a new pathway for improving cross-embodiment's overall adaptability. We hope our findings and tools inspire the community to rethink VLN limitations and advance robust, practical VLN models. The code is available at https://crystalsixone.github.io/vln_pe.github.io/.