 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOST-Bench: Evaluating the Capabilities of MLLMs in Online Spatio-temporal Scene Understanding
Jul 10, 2025



Recent advances in multimodal large language models (MLLMs) have shown remarkable capabilities in integrating vision and language for complex reasoning. While most existing benchmarks evaluate models under offline settings with a fixed set of pre-recorded inputs, we introduce OST-Bench, a benchmark designed to evaluate Online Spatio-Temporal understanding from the perspective of an agent actively exploring a scene. The Online aspect emphasizes the need to process and reason over incrementally acquired observations, while the Spatio-Temporal component requires integrating current visual inputs with historical memory to support dynamic spatial reasoning. OST-Bench better reflects the challenges of real-world embodied perception. Built on an efficient data collection pipeline, OST-Bench consists of 1.4k scenes and 10k question-answer pairs collected from ScanNet, Matterport3D, and ARKitScenes. We evaluate several leading MLLMs on OST-Bench and observe that they fall short on tasks requiring complex spatio-temporal reasoning. Under the online setting, their accuracy declines as the exploration horizon extends and the memory grows. Through further experimental analysis, we identify common error patterns across models and find that both complex clue-based spatial reasoning demands and long-term memory retrieval requirements significantly drop model performance along two separate axes, highlighting the core challenges that must be addressed to improve online embodied reasoning. To foster further research and development in the field, our codes, dataset, and benchmark are available. Our project page is: https://rbler1234.github.io/OSTBench.github.io/
MMScan: A Multi-Modal 3D Scene Dataset with Hierarchical Grounded Language Annotations
Jun 13, 2024



With the emergence of LLMs and their integration with other data modalities, multi-modal 3D perception attracts more attention due to its connectivity to the physical world and makes rapid progress. However, limited by existing datasets, previous works mainly focus on understanding object properties or inter-object spatial relationships in a 3D scene. To tackle this problem, this paper builds the first largest ever multi-modal 3D scene dataset and benchmark with hierarchical grounded language annotations, MMScan. It is constructed based on a top-down logic, from region to object level, from a single target to inter-target relationships, covering holistic aspects of spatial and attribute understanding. The overall pipeline incorporates powerful VLMs via carefully designed prompts to initialize the annotations efficiently and further involve humans' correction in the loop to ensure the annotations are natural, correct, and comprehensive. Built upon existing 3D scanning data, the resulting multi-modal 3D dataset encompasses 1.4M meta-annotated captions on 109k objects and 7.7k regions as well as over 3.04M diverse samples for 3D visual grounding and question-answering benchmarks. We evaluate representative baselines on our benchmarks, analyze their capabilities in different aspects, and showcase the key problems to be addressed in the future. Furthermore, we use this high-quality dataset to train state-of-the-art 3D visual grounding and LLMs and obtain remarkable performance improvement both on existing benchmarks and in-the-wild evaluation. Codes, datasets, and benchmarks will be available at https://github.com/OpenRobotLab/EmbodiedScan.
EmbodiedScan: A Holistic Multi-Modal 3D Perception Suite Towards Embodied AI
Dec 26, 2023In the realm of computer vision and robotics, embodied agents are expected to explore their environment and carry out human instructions. This necessitates the ability to fully understand 3D scenes given their first-person observations and contextualize them into language for interaction. However, traditional research focuses more on scene-level input and output setups from a global view. To address the gap, we introduce EmbodiedScan, a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. It encompasses over 5k scans encapsulating 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning over 760 categories, some of which partially align with LVIS, and dense semantic occupancy with 80 common categories. Building upon this database, we introduce a baseline framework named Embodied Perceptron. It is capable of processing an arbitrary number of multi-modal inputs and demonstrates remarkable 3D perception capabilities, both within the two series of benchmarks we set up, i.e., fundamental 3D perception tasks and language-grounded tasks, and in the wild. Codes, datasets, and benchmarks will be available at https://github.com/OpenRobotLab/EmbodiedScan.
Beyond Object Recognition: A New Benchmark towards Object Concept Learning
Dec 06, 2022



Understanding objects is a central building block of artificial intelligence, especially for embodied AI. Even though object recognition excels with deep learning, current machines still struggle to learn higher-level knowledge, e.g., what attributes an object has, and what can we do with an object. In this work, we propose a challenging Object Concept Learning (OCL) task to push the envelope of object understanding. It requires machines to reason out object affordances and simultaneously give the reason: what attributes make an object possesses these affordances. To support OCL, we build a densely annotated knowledge base including extensive labels for three levels of object concept (category, attribute, affordance), and the causal relations of three levels. By analyzing the causal structure of OCL, we present a baseline, Object Concept Reasoning Network (OCRN). It leverages causal intervention and concept instantiation to infer the three levels following their causal relations. In experiments, OCRN effectively infers the object knowledge while following the causalities well. Our data and code are available at https://mvig-rhos.com/ocl.
Learning Single/Multi-Attribute of Object with Symmetry and Group
Oct 09, 2021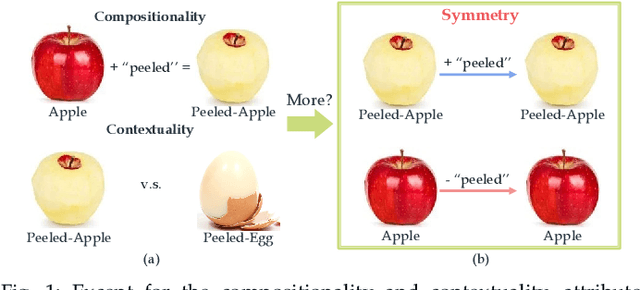
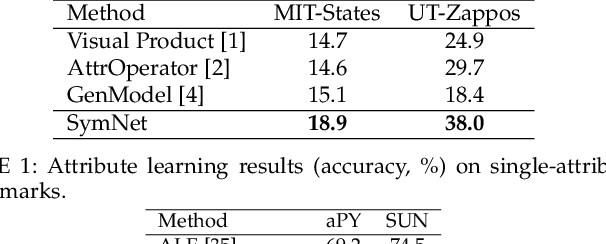
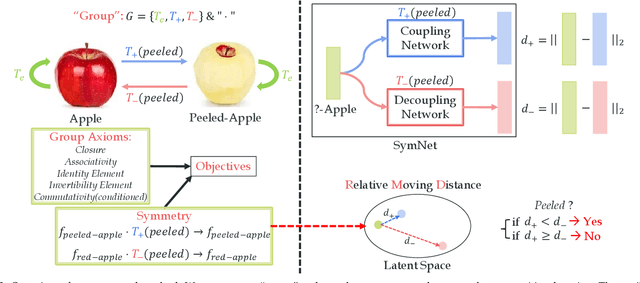
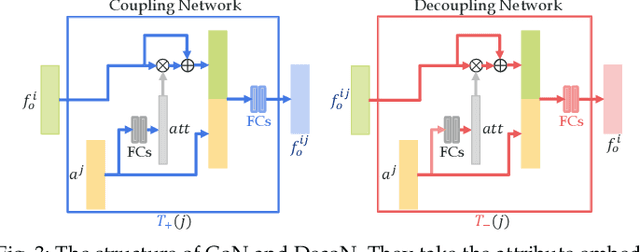
Attributes and objects can compose diverse compositions. To model the compositional nature of these concepts, it is a good choice to learn them as transformations, e.g., coupling and decoupling. However, complex transformations need to satisfy specific principles to guarantee rationality. Here, we first propose a previously ignored principle of attribute-object transformation: Symmetry. For example, coupling peeled-apple with attribute peeled should result in peeled-apple, and decoupling peeled from apple should still output apple. Incorporating the symmetry, we propose a transformation framework inspired by group theory, i.e., SymNet. It consists of two modules: Coupling Network and Decoupling Network. We adopt deep neural networks to implement SymNet and train it in an end-to-end paradigm with the group axioms and symmetry as objectives. Then, we propose a Relative Moving Distance (RMD) based method to utilize the attribute change instead of the attribute pattern itself to classify attributes. Besides the compositions of single-attribute and object, our RMD is also suitable for complex compositions of multiple attributes and objects when incorporating attribute correlations. SymNet can be utilized for attribute learning, compositional zero-shot learning and outperforms the state-of-the-art on four widely-used benchmarks. Code is at https://github.com/DirtyHarryLYL/SymNet.
Symmetry and Group in Attribute-Object Compositions
Apr 01, 2020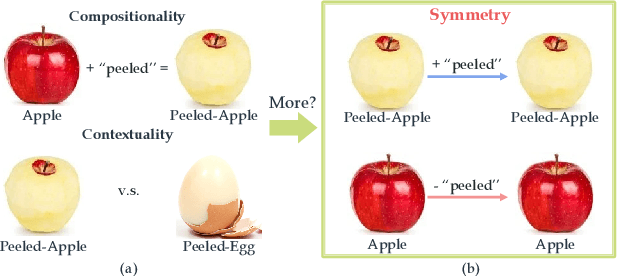
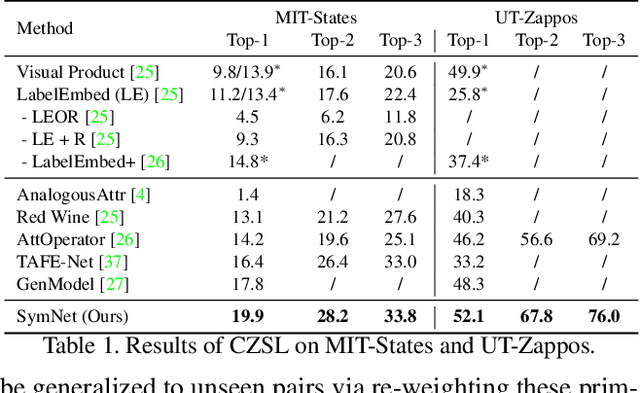
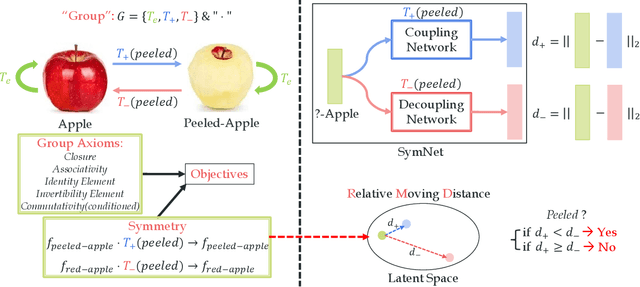

Attributes and objects can compose diverse compositions. To model the compositional nature of these general concepts, it is a good choice to learn them through transformations, such as coupling and decoupling. However, complex transformations need to satisfy specific principles to guarantee the rationality. In this paper, we first propose a previously ignored principle of attribute-object transformation: Symmetry. For example, coupling peeled-apple with attribute peeled should result in peeled-apple, and decoupling peeled from apple should still output apple. Incorporating the symmetry principle, a transformation framework inspired by group theory is built, i.e. SymNet. SymNet consists of two modules, Coupling Network and Decoupling Network. With the group axioms and symmetry property as objectives, we adopt Deep Neural Networks to implement SymNet and train it in an end-to-end paradigm. Moreover, we propose a Relative Moving Distance (RMD) based recognition method to utilize the attribute change instead of the attribute pattern itself to classify attributes. Our symmetry learning can be utilized for the Compositional Zero-Shot Learning task and outperforms the state-of-the-art on widely-used benchmarks. Code is available at https://github.com/DirtyHarryLYL/SymNet.