 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Indoor Occupancy Prediction via Sparse Query-Based Multi-Level Consistent Knowledge Distillation
Feb 02, 2026Occupancy prediction provides critical geometric and semantic understanding for robotics but faces efficiency-accuracy trade-offs. Current dense methods suffer computational waste on empty voxels, while sparse query-based approaches lack robustness in diverse and complex indoor scenes. In this paper, we propose DiScene, a novel sparse query-based framework that leverages multi-level distillation to achieve efficient and robust occupancy prediction. In particular, our method incorporates two key innovations: (1) a Multi-level Consistent Knowledge Distillation strategy, which transfers hierarchical representations from large teacher models to lightweight students through coordinated alignment across four levels, including encoder-level feature alignment, query-level feature matching, prior-level spatial guidance, and anchor-level high-confidence knowledge transfer and (2) a Teacher-Guided Initialization policy, employing optimized parameter warm-up to accelerate model convergence. Validated on the Occ-Scannet benchmark, DiScene achieves 23.2 FPS without depth priors while outperforming our baseline method, OPUS, by 36.1% and even better than the depth-enhanced version, OPUS†. With depth integration, DiScene† attains new SOTA performance, surpassing EmbodiedOcc by 3.7% with 1.62$\times$ faster inference speed. Furthermore, experiments on the Occ3D-nuScenes benchmark and in-the-wild scenarios demonstrate the versatility of our approach in various environments. Code and models can be accessed at https://github.com/getterupper/DiScene.
Nimbus: A Unified Embodied Synthetic Data Generation Framework
Jan 29, 2026Scaling data volume and diversity is critical for generalizing embodied intelligence. While synthetic data generation offers a scalable alternative to expensive physical data acquisition, existing pipelines remain fragmented and task-specific. This isolation leads to significant engineering inefficiency and system instability, failing to support the sustained, high-throughput data generation required for foundation model training. To address these challenges, we present Nimbus, a unified synthetic data generation framework designed to integrate heterogeneous navigation and manipulation pipelines. Nimbus introduces a modular four-layer architecture featuring a decoupled execution model that separates trajectory planning, rendering, and storage into asynchronous stages. By implementing dynamic pipeline scheduling, global load balancing, distributed fault tolerance, and backend-specific rendering optimizations, the system maximizes resource utilization across CPU, GPU, and I/O resources. Our evaluation demonstrates that Nimbus achieves a 2-3X improvement in end-to-end throughput compared to unoptimized baselines and ensuring robust, long-term operation in large-scale distributed environments. This framework serves as the production backbone for the InternData suite, enabling seamless cross-domain data synthesis.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
World In Your Hands: A Large-Scale and Open-source Ecosystem for Learning Human-centric Manipulation in the Wild
Dec 30, 2025Large-scale pre-training is fundamental for generalization in language and vision models, but data for dexterous hand manipulation remains limited in scale and diversity, hindering policy generalization. Limited scenario diversity, misaligned modalities, and insufficient benchmarking constrain current human manipulation datasets. To address these gaps, we introduce World In Your Hands (WiYH), a large-scale open-source ecosystem for human-centric manipulation learning. WiYH includes (1) the Oracle Suite, a wearable data collection kit with an auto-labeling pipeline for accurate motion capture; (2) the WiYH Dataset, featuring over 1,000 hours of multi-modal manipulation data across hundreds of skills in diverse real-world scenarios; and (3) extensive annotations and benchmarks supporting tasks from perception to action. Furthermore, experiments based on the WiYH ecosystem show that integrating WiYH's human-centric data significantly enhances the generalization and robustness of dexterous hand policies in tabletop manipulation tasks. We believe that World In Your Hands will bring new insights into human-centric data collection and policy learning to the community.
Learning Primitive Embodied World Models: Towards Scalable Robotic Learning
Aug 28, 2025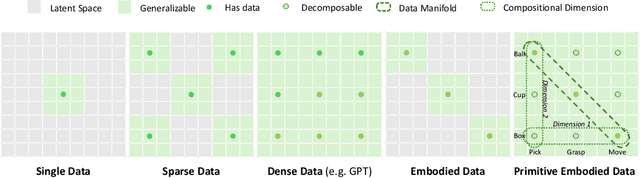



While video-generation-based embodied world models have gained increasing attention, their reliance on large-scale embodied interaction data remains a key bottleneck. The scarcity, difficulty of collection, and high dimensionality of embodied data fundamentally limit the alignment granularity between language and actions and exacerbate the challenge of long-horizon video generation--hindering generative models from achieving a "GPT moment" in the embodied domain. There is a naive observation: the diversity of embodied data far exceeds the relatively small space of possible primitive motions. Based on this insight, we propose a novel paradigm for world modeling--Primitive Embodied World Models (PEWM). By restricting video generation to fixed short horizons, our approach 1) enables fine-grained alignment between linguistic concepts and visual representations of robotic actions, 2) reduces learning complexity, 3) improves data efficiency in embodied data collection, and 4) decreases inference latency. By equipping with a modular Vision-Language Model (VLM) planner and a Start-Goal heatmap Guidance mechanism (SGG), PEWM further enables flexible closed-loop control and supports compositional generalization of primitive-level policies over extended, complex tasks. Our framework leverages the spatiotemporal vision priors in video models and the semantic awareness of VLMs to bridge the gap between fine-grained physical interaction and high-level reasoning, paving the way toward scalable, interpretable, and general-purpose embodied intelligence.
InstructVLA: Vision-Language-Action Instruction Tuning from Understanding to Manipulation
Jul 23, 2025To operate effectively in the real world, robots must integrate multimodal reasoning with precise action generation. However, existing vision-language-action (VLA) models often sacrifice one for the other, narrow their abilities to task-specific manipulation data, and suffer catastrophic forgetting of pre-trained vision-language capabilities. To bridge this gap, we introduce InstructVLA, an end-to-end VLA model that preserves the flexible reasoning of large vision-language models (VLMs) while delivering leading manipulation performance. InstructVLA introduces a novel training paradigm, Vision-Language-Action Instruction Tuning (VLA-IT), which employs multimodal training with mixture-of-experts adaptation to jointly optimize textual reasoning and action generation on both standard VLM corpora and a curated 650K-sample VLA-IT dataset. On in-domain SimplerEnv tasks, InstructVLA achieves 30.5% improvement over SpatialVLA. To evaluate generalization, we introduce SimplerEnv-Instruct, an 80-task benchmark requiring closed-loop control and high-level instruction understanding, where it outperforms a fine-tuned OpenVLA by 92% and an action expert aided by GPT-4o by 29%. Additionally, InstructVLA surpasses baseline VLMs on multimodal tasks and exhibits inference-time scaling by leveraging textual reasoning to boost manipulation performance in both simulated and real-world settings. These results demonstrate InstructVLA's potential for bridging intuitive and steerable human-robot interaction with efficient policy learning.
Rethinking the Embodied Gap in Vision-and-Language Navigation: A Holistic Study of Physical and Visual Disparities
Jul 17, 2025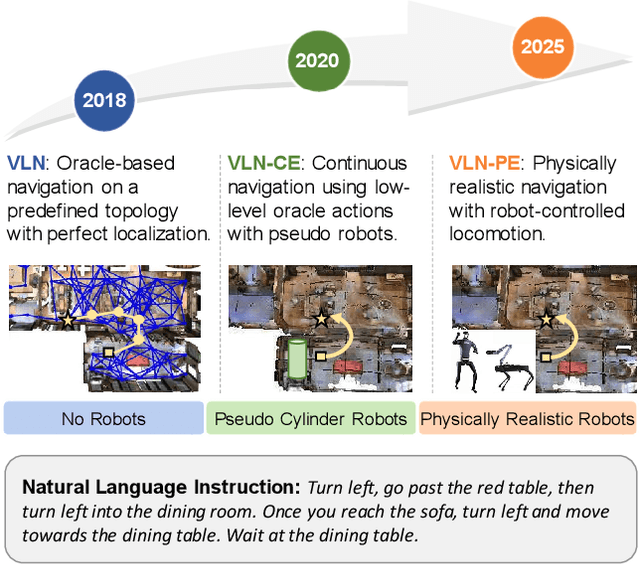
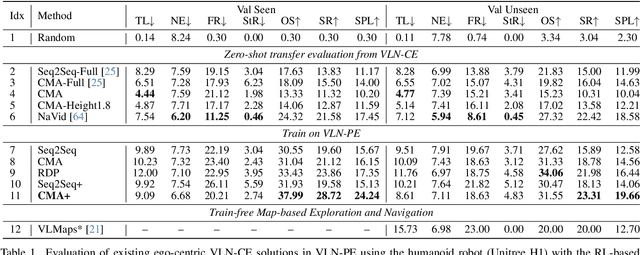
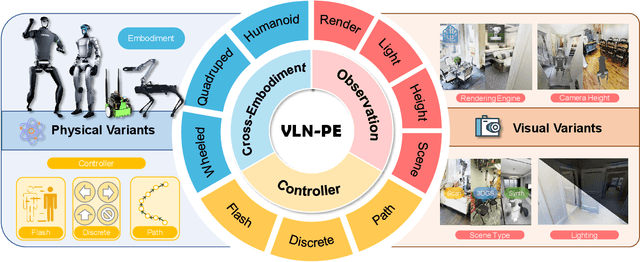

Recent Vision-and-Language Navigation (VLN) advancements are promising, but their idealized assumptions about robot movement and control fail to reflect physically embodied deployment challenges. To bridge this gap, we introduce VLN-PE, a physically realistic VLN platform supporting humanoid, quadruped, and wheeled robots. For the first time, we systematically evaluate several ego-centric VLN methods in physical robotic settings across different technical pipelines, including classification models for single-step discrete action prediction, a diffusion model for dense waypoint prediction, and a train-free, map-based large language model (LLM) integrated with path planning. Our results reveal significant performance degradation due to limited robot observation space, environmental lighting variations, and physical challenges like collisions and falls. This also exposes locomotion constraints for legged robots in complex environments. VLN-PE is highly extensible, allowing seamless integration of new scenes beyond MP3D, thereby enabling more comprehensive VLN evaluation. Despite the weak generalization of current models in physical deployment, VLN-PE provides a new pathway for improving cross-embodiment's overall adaptability. We hope our findings and tools inspire the community to rethink VLN limitations and advance robust, practical VLN models. The code is available at https://crystalsixone.github.io/vln_pe.github.io/.
CronusVLA: Transferring Latent Motion Across Time for Multi-Frame Prediction in Manipulation
Jun 24, 2025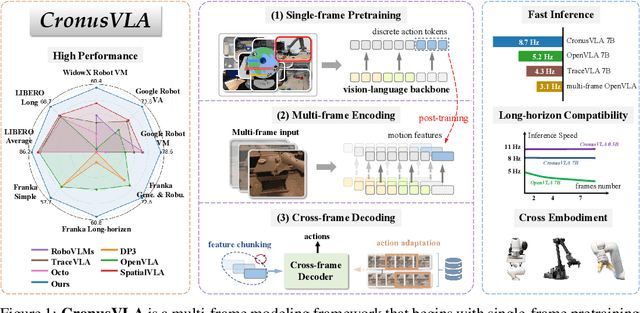
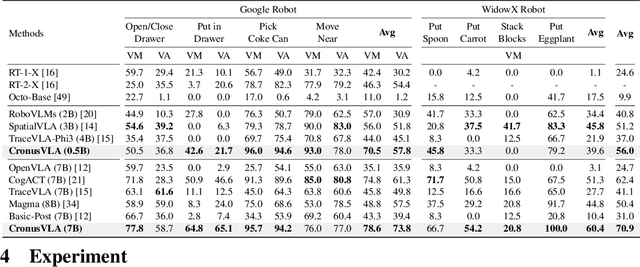
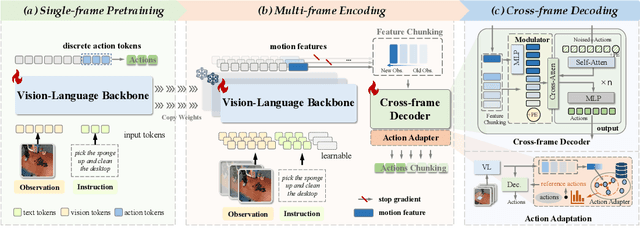
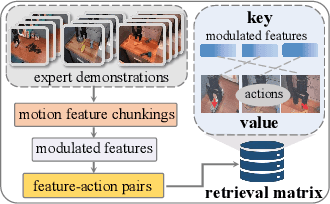
Recent vision-language-action (VLA) models built on pretrained vision-language models (VLMs) have demonstrated strong generalization across manipulation tasks. However, they remain constrained by a single-frame observation paradigm and cannot fully benefit from the motion information offered by aggregated multi-frame historical observations, as the large vision-language backbone introduces substantial computational cost and inference latency. We propose CronusVLA, a unified framework that extends single-frame VLA models to the multi-frame paradigm through an efficient post-training stage. CronusVLA comprises three key components: (1) single-frame pretraining on large-scale embodied datasets with autoregressive action tokens prediction, which establishes an embodied vision-language foundation; (2) multi-frame encoding, adapting the prediction of vision-language backbones from discrete action tokens to motion features during post-training, and aggregating motion features from historical frames into a feature chunking; (3) cross-frame decoding, which maps the feature chunking to accurate actions via a shared decoder with cross-attention. By reducing redundant token computation and caching past motion features, CronusVLA achieves efficient inference. As an application of motion features, we further propose an action adaptation mechanism based on feature-action retrieval to improve model performance during finetuning. CronusVLA achieves state-of-the-art performance on SimplerEnv with 70.9% success rate, and 12.7% improvement over OpenVLA on LIBERO. Real-world Franka experiments also show the strong performance and robustness.
GENMANIP: LLM-driven Simulation for Generalizable Instruction-Following Manipulation
Jun 12, 2025
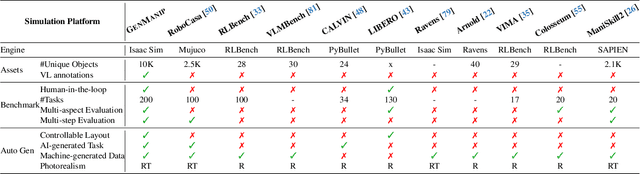

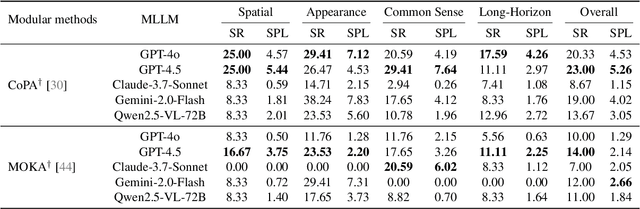
Robotic manipulation in real-world settings remains challenging, especially regarding robust generalization. Existing simulation platforms lack sufficient support for exploring how policies adapt to varied instructions and scenarios. Thus, they lag behind the growing interest in instruction-following foundation models like LLMs, whose adaptability is crucial yet remains underexplored in fair comparisons. To bridge this gap, we introduce GenManip, a realistic tabletop simulation platform tailored for policy generalization studies. It features an automatic pipeline via LLM-driven task-oriented scene graph to synthesize large-scale, diverse tasks using 10K annotated 3D object assets. To systematically assess generalization, we present GenManip-Bench, a benchmark of 200 scenarios refined via human-in-the-loop corrections. We evaluate two policy types: (1) modular manipulation systems integrating foundation models for perception, reasoning, and planning, and (2) end-to-end policies trained through scalable data collection. Results show that while data scaling benefits end-to-end methods, modular systems enhanced with foundation models generalize more effectively across diverse scenarios. We anticipate this platform to facilitate critical insights for advancing policy generalization in realistic conditions. Project Page: https://genmanip.axi404.top/.
LiloDriver: A Lifelong Learning Framework for Closed-loop Motion Planning in Long-tail Autonomous Driving Scenarios
May 22, 2025Recent advances in autonomous driving research towards motion planners that are robust, safe, and adaptive. However, existing rule-based and data-driven planners lack adaptability to long-tail scenarios, while knowledge-driven methods offer strong reasoning but face challenges in representation, control, and real-world evaluation. To address these challenges, we present LiloDriver, a lifelong learning framework for closed-loop motion planning in long-tail autonomous driving scenarios. By integrating large language models (LLMs) with a memory-augmented planner generation system, LiloDriver continuously adapts to new scenarios without retraining. It features a four-stage architecture including perception, scene encoding, memory-based strategy refinement, and LLM-guided reasoning. Evaluated on the nuPlan benchmark, LiloDriver achieves superior performance in both common and rare driving scenarios, outperforming static rule-based and learning-based planners. Our results highlight the effectiveness of combining structured memory and LLM reasoning to enable scalable, human-like motion planning in real-world autonomous driving. Our code is available at https://github.com/Hyan-Yao/LiloDriver.