 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.
ReasonPlan: Unified Scene Prediction and Decision Reasoning for Closed-loop Autonomous Driving
May 26, 2025Due to the powerful vision-language reasoning and generalization abilities, multimodal large language models (MLLMs) have garnered significant attention in the field of end-to-end (E2E) autonomous driving. However, their application to closed-loop systems remains underexplored, and current MLLM-based methods have not shown clear superiority to mainstream E2E imitation learning approaches. In this work, we propose ReasonPlan, a novel MLLM fine-tuning framework designed for closed-loop driving through holistic reasoning with a self-supervised Next Scene Prediction task and supervised Decision Chain-of-Thought process. This dual mechanism encourages the model to align visual representations with actionable driving context, while promoting interpretable and causally grounded decision making. We curate a planning-oriented decision reasoning dataset, namely PDR, comprising 210k diverse and high-quality samples. Our method outperforms the mainstream E2E imitation learning method by a large margin of 19% L2 and 16.1 driving score on Bench2Drive benchmark. Furthermore, ReasonPlan demonstrates strong zero-shot generalization on unseen DOS benchmark, highlighting its adaptability in handling zero-shot corner cases. Code and dataset will be found in https://github.com/Liuxueyi/ReasonPlan.
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis
May 19, 2025Graphical user interface (GUI) grounding, the ability to map natural language instructions to specific actions on graphical user interfaces, remains a critical bottleneck in computer use agent development. Current benchmarks oversimplify grounding tasks as short referring expressions, failing to capture the complexity of real-world interactions that require software commonsense, layout understanding, and fine-grained manipulation capabilities. To address these limitations, we introduce OSWorld-G, a comprehensive benchmark comprising 564 finely annotated samples across diverse task types including text matching, element recognition, layout understanding, and precise manipulation. Additionally, we synthesize and release the largest computer use grounding dataset Jedi, which contains 4 million examples through multi-perspective decoupling of tasks. Our multi-scale models trained on Jedi demonstrate its effectiveness by outperforming existing approaches on ScreenSpot-v2, ScreenSpot-Pro, and our OSWorld-G. Furthermore, we demonstrate that improved grounding with Jedi directly enhances agentic capabilities of general foundation models on complex computer tasks, improving from 5% to 27% on OSWorld. Through detailed ablation studies, we identify key factors contributing to grounding performance and verify that combining specialized data for different interface elements enables compositional generalization to novel interfaces. All benchmark, data, checkpoints, and code are open-sourced and available at https://osworld-grounding.github.io.
AgentTrek: Agent Trajectory Synthesis via Guiding Replay with Web Tutorials
Dec 12, 2024Graphical User Interface (GUI) agents hold great potential for automating complex tasks across diverse digital environments, from web applications to desktop software. However, the development of such agents is hindered by the lack of high-quality, multi-step trajectory data required for effective training. Existing approaches rely on expensive and labor-intensive human annotation, making them unsustainable at scale. To address this challenge, we propose AgentTrek, a scalable data synthesis pipeline that generates high-quality GUI agent trajectories by leveraging web tutorials. Our method automatically gathers tutorial-like texts from the internet, transforms them into task goals with step-by-step instructions, and employs a visual-language model agent to simulate their execution in a real digital environment. A VLM-based evaluator ensures the correctness of the generated trajectories. We demonstrate that training GUI agents with these synthesized trajectories significantly improves their grounding and planning performance over the current models. Moreover, our approach is more cost-efficient compared to traditional human annotation methods. This work underscores the potential of guided replay with web tutorials as a viable strategy for large-scale GUI agent training, paving the way for more capable and autonomous digital agents.
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Dec 05, 2024



Graphical User Interfaces (GUIs) are critical to human-computer interaction, yet automating GUI tasks remains challenging due to the complexity and variability of visual environments. Existing approaches often rely on textual representations of GUIs, which introduce limitations in generalization, efficiency, and scalability. In this paper, we introduce Aguvis, a unified pure vision-based framework for autonomous GUI agents that operates across various platforms. Our approach leverages image-based observations, and grounding instructions in natural language to visual elements, and employs a consistent action space to ensure cross-platform generalization. To address the limitations of previous work, we integrate explicit planning and reasoning within the model, enhancing its ability to autonomously navigate and interact with complex digital environments. We construct a large-scale dataset of GUI agent trajectories, incorporating multimodal reasoning and grounding, and employ a two-stage training pipeline that first focuses on general GUI grounding, followed by planning and reasoning. Through comprehensive experiments, we demonstrate that Aguvis surpasses previous state-of-the-art methods in both offline and real-world online scenarios, achieving, to our knowledge, the first fully autonomous pure vision GUI agent capable of performing tasks independently without collaboration with external closed-source models. We open-sourced all datasets, models, and training recipes to facilitate future research at https://aguvis-project.github.io/.
Correct after Answer: Enhancing Multi-Span Question Answering with Post-Processing Method
Oct 22, 2024



Multi-Span Question Answering (MSQA) requires models to extract one or multiple answer spans from a given context to answer a question. Prior work mainly focuses on designing specific methods or applying heuristic strategies to encourage models to predict more correct predictions. However, these models are trained on gold answers and fail to consider the incorrect predictions. Through a statistical analysis, we observe that models with stronger abilities do not predict less incorrect predictions compared with other models. In this work, we propose Answering-Classifying-Correcting (ACC) framework, which employs a post-processing strategy to handle incorrect predictions. Specifically, the ACC framework first introduces a classifier to classify the predictions into three types and exclude "wrong predictions", then introduces a corrector to modify "partially correct predictions". Experiments on several MSQA datasets show that ACC framework significantly improves the Exact Match (EM) scores, and further analysis demostrates that ACC framework efficiently reduces the number of incorrect predictions, improving the quality of predictions.
Bench4Merge: A Comprehensive Benchmark for Merging in Realistic Dense Traffic with Micro-Interactive Vehicles
Oct 21, 2024



While the capabilities of autonomous driving have advanced rapidly, merging into dense traffic remains a significant challenge, many motion planning methods for this scenario have been proposed but it is hard to evaluate them. Most existing closed-loop simulators rely on rule-based controls for other vehicles, which results in a lack of diversity and randomness, thus failing to accurately assess the motion planning capabilities in highly interactive scenarios. Moreover, traditional evaluation metrics are insufficient for comprehensively evaluating the performance of merging in dense traffic. In response, we proposed a closed-loop evaluation benchmark for assessing motion planning capabilities in merging scenarios. Our approach involves other vehicles trained in large scale datasets with micro-behavioral characteristics that significantly enhance the complexity and diversity. Additionally, we have restructured the evaluation mechanism by leveraging large language models to assess each autonomous vehicle merging onto the main road. Extensive experiments have demonstrated the advanced nature of this evaluation benchmark. Through this benchmark, we have obtained an evaluation of existing methods and identified common issues. The environment and vehicle motion planning models we have designed can be accessed at https://anonymous.4open.science/r/Bench4Merge-EB5D
A Novel Method to Metigate Demographic and Expert Bias in ICD Coding with Causal Inference
Oct 18, 2024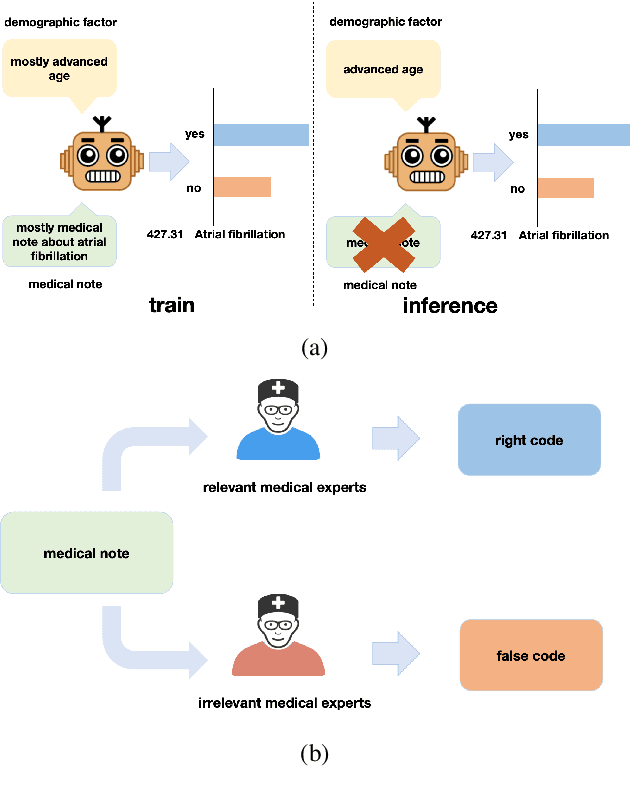



ICD(International Classification of Diseases) coding involves assigning ICD codes to patients visit based on their medical notes. Considering ICD coding as a multi-label text classification task, researchers have developed sophisticated methods. Despite progress, these models often suffer from label imbalance and may develop spurious correlations with demographic factors. Additionally, while human coders assign ICD codes, the inclusion of irrelevant information from unrelated experts introduces biases. To combat these issues, we propose a novel method to mitigate Demographic and Expert biases in ICD coding through Causal Inference (DECI). We provide a novel causality-based interpretation in ICD Coding that models make predictions by three distinct pathways. And based counterfactual reasoning, DECI mitigate demographic and expert biases. Experimental results show that DECI outperforms state-of-the-art models, offering a significant advancement in accurate and unbiased ICD coding.
A Lightweight Multi Aspect Controlled Text Generation Solution For Large Language Models
Oct 18, 2024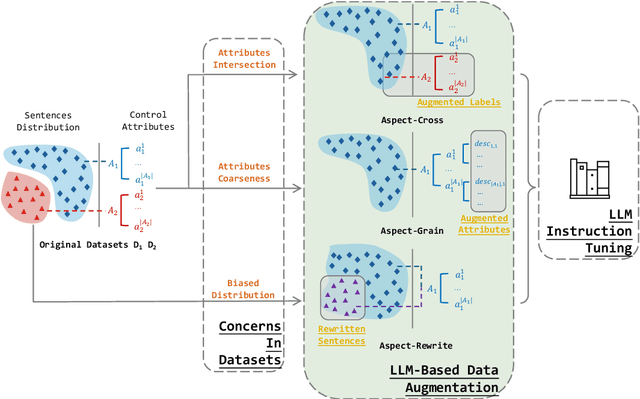
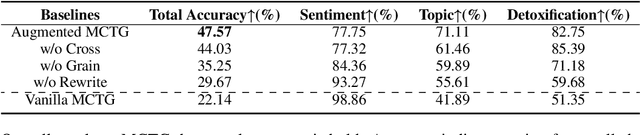


Large language models (LLMs) show remarkable abilities with instruction tuning. However, they fail to achieve ideal tasks when lacking high-quality instruction tuning data on target tasks. Multi-Aspect Controllable Text Generation (MCTG) is a representative task for this dilemma, where aspect datasets are usually biased and correlated. Existing work exploits additional model structures and strategies for solutions, limiting adaptability to LLMs. To activate MCTG ability of LLMs, we propose a lightweight MCTG pipeline based on data augmentation. We analyze bias and correlations in traditional datasets, and address these concerns with augmented control attributes and sentences. Augmented datasets are feasible for instruction tuning. In our experiments, LLMs perform better in MCTG after data augmentation, with a 20% accuracy rise and less aspect correlations.
Dual-AEB: Synergizing Rule-Based and Multimodal Large Language Models for Effective Emergency Braking
Oct 11, 2024



Automatic Emergency Braking (AEB) systems are a crucial component in ensuring the safety of passengers in autonomous vehicles. Conventional AEB systems primarily rely on closed-set perception modules to recognize traffic conditions and assess collision risks. To enhance the adaptability of AEB systems in open scenarios, we propose Dual-AEB, a system combines an advanced multimodal large language model (MLLM) for comprehensive scene understanding and a conventional rule-based rapid AEB to ensure quick response times. To the best of our knowledge, Dual-AEB is the first method to incorporate MLLMs within AEB systems. Through extensive experimentation, we have validated the effectiveness of our method. The source code will be available at https://github.com/ChipsICU/Dual-AEB.