 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect after Answer: Enhancing Multi-Span Question Answering with Post-Processing Method
Oct 22, 2024



Multi-Span Question Answering (MSQA) requires models to extract one or multiple answer spans from a given context to answer a question. Prior work mainly focuses on designing specific methods or applying heuristic strategies to encourage models to predict more correct predictions. However, these models are trained on gold answers and fail to consider the incorrect predictions. Through a statistical analysis, we observe that models with stronger abilities do not predict less incorrect predictions compared with other models. In this work, we propose Answering-Classifying-Correcting (ACC) framework, which employs a post-processing strategy to handle incorrect predictions. Specifically, the ACC framework first introduces a classifier to classify the predictions into three types and exclude "wrong predictions", then introduces a corrector to modify "partially correct predictions". Experiments on several MSQA datasets show that ACC framework significantly improves the Exact Match (EM) scores, and further analysis demostrates that ACC framework efficiently reduces the number of incorrect predictions, improving the quality of predictions.
A Lightweight Multi Aspect Controlled Text Generation Solution For Large Language Models
Oct 18, 2024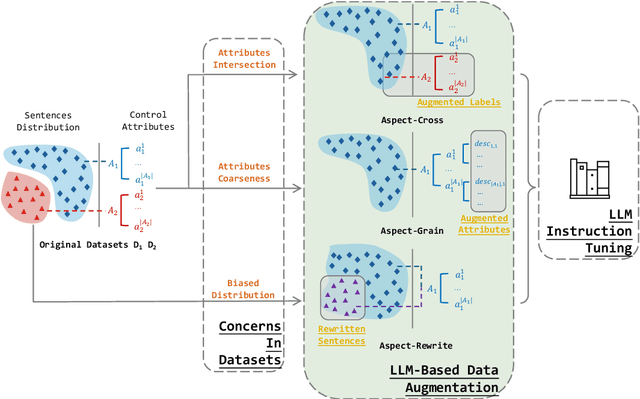
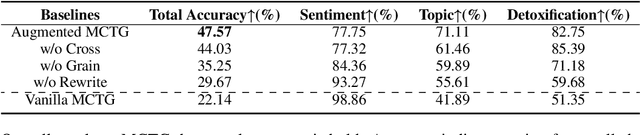


Large language models (LLMs) show remarkable abilities with instruction tuning. However, they fail to achieve ideal tasks when lacking high-quality instruction tuning data on target tasks. Multi-Aspect Controllable Text Generation (MCTG) is a representative task for this dilemma, where aspect datasets are usually biased and correlated. Existing work exploits additional model structures and strategies for solutions, limiting adaptability to LLMs. To activate MCTG ability of LLMs, we propose a lightweight MCTG pipeline based on data augmentation. We analyze bias and correlations in traditional datasets, and address these concerns with augmented control attributes and sentences. Augmented datasets are feasible for instruction tuning. In our experiments, LLMs perform better in MCTG after data augmentation, with a 20% accuracy rise and less aspect correlations.