 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLID-MU: Cross-Layer Information Divergence Based Meta Update Strategy for Learning with Noisy Labels
Jul 16, 2025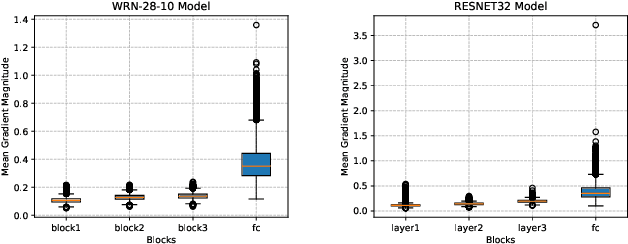
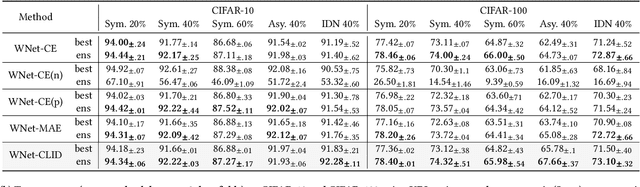
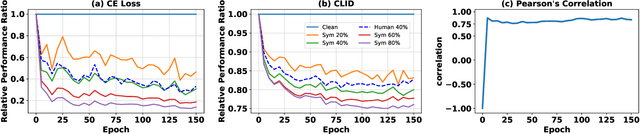
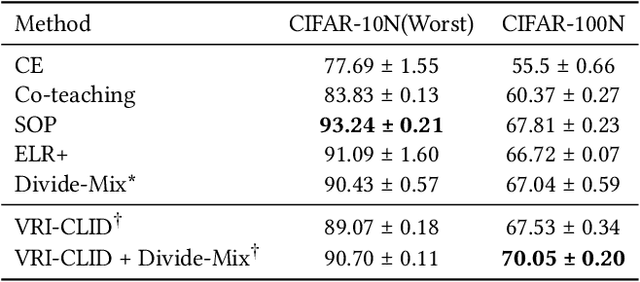
Learning with noisy labels (LNL) is essential for training deep neural networks with imperfect data. Meta-learning approaches have achieved success by using a clean unbiased labeled set to train a robust model. However, this approach heavily depends on the availability of a clean labeled meta-dataset, which is difficult to obtain in practice. In this work, we thus tackle the challenge of meta-learning for noisy label scenarios without relying on a clean labeled dataset. Our approach leverages the data itself while bypassing the need for labels. Building on the insight that clean samples effectively preserve the consistency of related data structures across the last hidden and the final layer, whereas noisy samples disrupt this consistency, we design the Cross-layer Information Divergence-based Meta Update Strategy (CLID-MU). CLID-MU leverages the alignment of data structures across these diverse feature spaces to evaluate model performance and use this alignment to guide training. Experiments on benchmark datasets with varying amounts of labels under both synthetic and real-world noise demonstrate that CLID-MU outperforms state-of-the-art methods. The code is released at https://github.com/ruofanhu/CLID-MU.
Cultural Bias Matters: A Cross-Cultural Benchmark Dataset and Sentiment-Enriched Model for Understanding Multimodal Metaphors
Jun 08, 2025
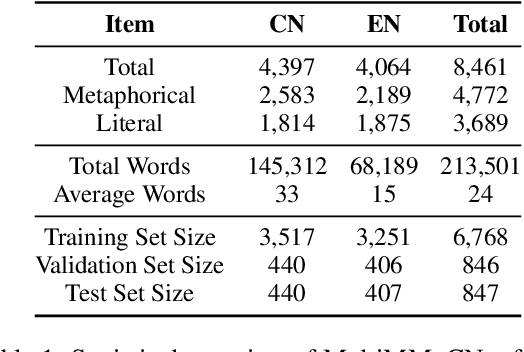

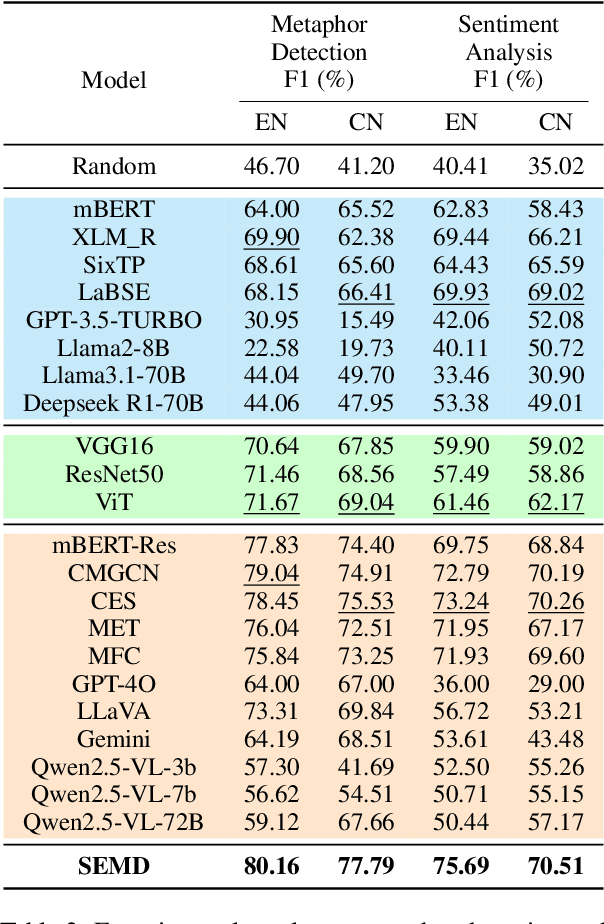
Metaphors are pervasive in communication, making them crucial for natural language processing (NLP). Previous research on automatic metaphor processing predominantly relies on training data consisting of English samples, which often reflect Western European or North American biases. This cultural skew can lead to an overestimation of model performance and contributions to NLP progress. However, the impact of cultural bias on metaphor processing, particularly in multimodal contexts, remains largely unexplored. To address this gap, we introduce MultiMM, a Multicultural Multimodal Metaphor dataset designed for cross-cultural studies of metaphor in Chinese and English. MultiMM consists of 8,461 text-image advertisement pairs, each accompanied by fine-grained annotations, providing a deeper understanding of multimodal metaphors beyond a single cultural domain. Additionally, we propose Sentiment-Enriched Metaphor Detection (SEMD), a baseline model that integrates sentiment embeddings to enhance metaphor comprehension across cultural backgrounds. Experimental results validate the effectiveness of SEMD on metaphor detection and sentiment analysis tasks. We hope this work increases awareness of cultural bias in NLP research and contributes to the development of fairer and more inclusive language models. Our dataset and code are available at https://github.com/DUTIR-YSQ/MultiMM.
Towards Multimodal Metaphor Understanding: A Chinese Dataset and Model for Metaphor Mapping Identification
Jan 05, 2025



Metaphors play a crucial role in human communication, yet their comprehension remains a significant challenge for natural language processing (NLP) due to the cognitive complexity involved. According to Conceptual Metaphor Theory (CMT), metaphors map a target domain onto a source domain, and understanding this mapping is essential for grasping the nature of metaphors. While existing NLP research has focused on tasks like metaphor detection and sentiment analysis of metaphorical expressions, there has been limited attention to the intricate process of identifying the mappings between source and target domains. Moreover, non-English multimodal metaphor resources remain largely neglected in the literature, hindering a deeper understanding of the key elements involved in metaphor interpretation. To address this gap, we developed a Chinese multimodal metaphor advertisement dataset (namely CM3D) that includes annotations of specific target and source domains. This dataset aims to foster further research into metaphor comprehension, particularly in non-English languages. Furthermore, we propose a Chain-of-Thought (CoT) Prompting-based Metaphor Mapping Identification Model (CPMMIM), which simulates the human cognitive process for identifying these mappings. Drawing inspiration from CoT reasoning and Bi-Level Optimization (BLO), we treat the task as a hierarchical identification problem, enabling more accurate and interpretable metaphor mapping. Our experimental results demonstrate the effectiveness of CPMMIM, highlighting its potential for advancing metaphor comprehension in NLP. Our dataset and code are both publicly available to encourage further advancements in this field.
ROSE: A Reward-Oriented Data Selection Framework for LLM Task-Specific Instruction Tuning
Dec 01, 2024



Instruction tuning has underscored the significant potential of large language models (LLMs) in producing more human-controllable and effective outputs in various domains. In this work, we focus on the data selection problem for task-specific instruction tuning of LLMs. Prevailing methods primarily rely on the crafted similarity metrics to select training data that aligns with the test data distribution. The goal is to minimize instruction tuning loss on the test data, ultimately improving performance on the target task. However, it has been widely observed that instruction tuning loss (i.e., cross-entropy loss for next token prediction) in LLMs often fails to exhibit a monotonic relationship with actual task performance. This misalignment undermines the effectiveness of current data selection methods for task-specific instruction tuning. To address this issue, we introduce ROSE, a novel Reward-Oriented inStruction data sElection method which leverages pairwise preference loss as a reward signal to optimize data selection for task-specific instruction tuning. Specifically, ROSE adapts an influence formulation to approximate the influence of training data points relative to a few-shot preference validation set to select the most task-related training data points. Experimental results show that by selecting just 5% of the training data using ROSE, our approach can achieve competitive results compared to fine-tuning with the full training dataset, and it surpasses other state-of-the-art data selection methods for task-specific instruction tuning. Our qualitative analysis further confirms the robust generalizability of our method across multiple benchmark datasets and diverse model architectures.
Correct after Answer: Enhancing Multi-Span Question Answering with Post-Processing Method
Oct 22, 2024



Multi-Span Question Answering (MSQA) requires models to extract one or multiple answer spans from a given context to answer a question. Prior work mainly focuses on designing specific methods or applying heuristic strategies to encourage models to predict more correct predictions. However, these models are trained on gold answers and fail to consider the incorrect predictions. Through a statistical analysis, we observe that models with stronger abilities do not predict less incorrect predictions compared with other models. In this work, we propose Answering-Classifying-Correcting (ACC) framework, which employs a post-processing strategy to handle incorrect predictions. Specifically, the ACC framework first introduces a classifier to classify the predictions into three types and exclude "wrong predictions", then introduces a corrector to modify "partially correct predictions". Experiments on several MSQA datasets show that ACC framework significantly improves the Exact Match (EM) scores, and further analysis demostrates that ACC framework efficiently reduces the number of incorrect predictions, improving the quality of predictions.
A Lightweight Multi Aspect Controlled Text Generation Solution For Large Language Models
Oct 18, 2024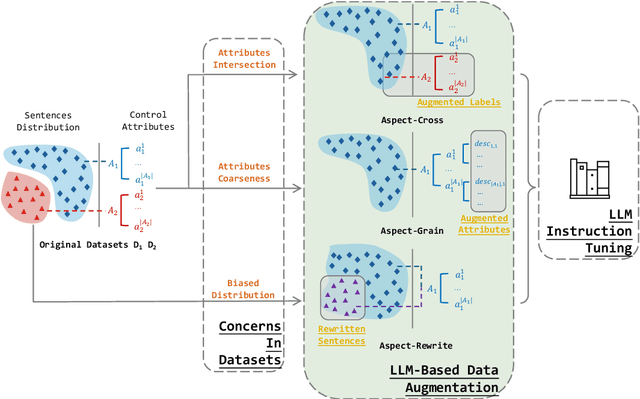
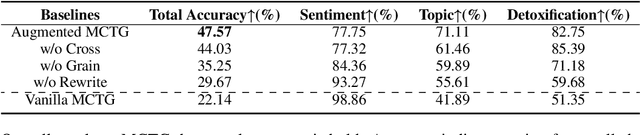


Large language models (LLMs) show remarkable abilities with instruction tuning. However, they fail to achieve ideal tasks when lacking high-quality instruction tuning data on target tasks. Multi-Aspect Controllable Text Generation (MCTG) is a representative task for this dilemma, where aspect datasets are usually biased and correlated. Existing work exploits additional model structures and strategies for solutions, limiting adaptability to LLMs. To activate MCTG ability of LLMs, we propose a lightweight MCTG pipeline based on data augmentation. We analyze bias and correlations in traditional datasets, and address these concerns with augmented control attributes and sentences. Augmented datasets are feasible for instruction tuning. In our experiments, LLMs perform better in MCTG after data augmentation, with a 20% accuracy rise and less aspect correlations.
Towards Comprehensive Detection of Chinese Harmful Memes
Oct 03, 2024



This paper has been accepted in the NeurIPS 2024 D & B Track. Harmful memes have proliferated on the Chinese Internet, while research on detecting Chinese harmful memes significantly lags behind due to the absence of reliable datasets and effective detectors. To this end, we focus on the comprehensive detection of Chinese harmful memes. We construct ToxiCN MM, the first Chinese harmful meme dataset, which consists of 12,000 samples with fine-grained annotations for various meme types. Additionally, we propose a baseline detector, Multimodal Knowledge Enhancement (MKE), incorporating contextual information of meme content generated by the LLM to enhance the understanding of Chinese memes. During the evaluation phase, we conduct extensive quantitative experiments and qualitative analyses on multiple baselines, including LLMs and our MKE. The experimental results indicate that detecting Chinese harmful memes is challenging for existing models while demonstrating the effectiveness of MKE. The resources for this paper are available at https://github.com/DUT-lujunyu/ToxiCN_MM.
Aggregation of Multi Diffusion Models for Enhancing Learned Representations
Oct 02, 2024Diffusion models have achieved remarkable success in image generation, particularly with the various applications of classifier-free guidance conditional diffusion models. While many diffusion models perform well when controlling for particular aspect among style, character, and interaction, they struggle with fine-grained control due to dataset limitations and intricate model architecture design. This paper introduces a novel algorithm, Aggregation of Multi Diffusion Models (AMDM), which synthesizes features from multiple diffusion models into a specified model, enhancing its learned representations to activate specific features for fine-grained control. AMDM consists of two key components: spherical aggregation and manifold optimization. Spherical aggregation merges intermediate variables from different diffusion models with minimal manifold deviation, while manifold optimization refines these variables to align with the intermediate data manifold, enhancing sampling quality. Experimental results demonstrate that AMDM significantly improves fine-grained control without additional training or inference time, proving its effectiveness. Additionally, it reveals that diffusion models initially focus on features such as position, attributes, and style, with later stages improving generation quality and consistency. AMDM offers a new perspective for tackling the challenges of fine-grained conditional control generation in diffusion models: We can fully utilize existing conditional diffusion models that control specific aspects, or develop new ones, and then aggregate them using the AMDM algorithm. This eliminates the need for constructing complex datasets, designing intricate model architectures, and incurring high training costs. Code is available at: https://github.com/Hammour-steak/AMDM
Enhanced Control for Diffusion Bridge in Image Restoration
Aug 29, 2024



Image restoration refers to the process of restoring a damaged low-quality image back to its corresponding high-quality image. Typically, we use convolutional neural networks to directly learn the mapping from low-quality images to high-quality images achieving image restoration. Recently, a special type of diffusion bridge model has achieved more advanced results in image restoration. It can transform the direct mapping from low-quality to high-quality images into a diffusion process, restoring low-quality images through a reverse process. However, the current diffusion bridge restoration models do not emphasize the idea of conditional control, which may affect performance. This paper introduces the ECDB model enhancing the control of the diffusion bridge with low-quality images as conditions. Moreover, in response to the characteristic of diffusion models having low denoising level at larger values of \(\bm t \), we also propose a Conditional Fusion Schedule, which more effectively handles the conditional feature information of various modules. Experimental results prove that the ECDB model has achieved state-of-the-art results in many image restoration tasks, including deraining, inpainting and super-resolution. Code is avaliable at https://github.com/Hammour-steak/ECDB.
Probing Causality Manipulation of Large Language Models
Aug 26, 2024



Large language models (LLMs) have shown various ability on natural language processing, including problems about causality. It is not intuitive for LLMs to command causality, since pretrained models usually work on statistical associations, and do not focus on causes and effects in sentences. So that probing internal manipulation of causality is necessary for LLMs. This paper proposes a novel approach to probe causality manipulation hierarchically, by providing different shortcuts to models and observe behaviors. We exploit retrieval augmented generation (RAG) and in-context learning (ICL) for models on a designed causality classification task. We conduct experiments on mainstream LLMs, including GPT-4 and some smaller and domain-specific models. Our results suggest that LLMs can detect entities related to causality and recognize direct causal relationships. However, LLMs lack specialized cognition for causality, merely treating them as part of the global semantic of the sentence.