 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCARE: Federated Unlearning with Conflict-Aware Projection and Relearning-Resistant Recovery
Jan 30, 2026Federated learning (FL) enables collaborative model training without centralizing raw data, but privacy regulations such as the right to be forgotten require FL systems to remove the influence of previously used training data upon request. Retraining a federated model from scratch is prohibitively expensive, motivating federated unlearning (FU). However, existing FU methods suffer from high unlearning overhead, utility degradation caused by entangled knowledge, and unintended relearning during post-unlearning recovery. In this paper, we propose FedCARE, a unified and low overhead FU framework that enables conflict-aware unlearning and relearning-resistant recovery. FedCARE leverages gradient ascent for efficient forgetting when target data are locally available and employs data free model inversion to construct class level proxies of shared knowledge. Based on these insights, FedCARE integrates a pseudo-sample generator, conflict-aware projected gradient ascent for utility preserving unlearning, and a recovery strategy that suppresses rollback toward the pre-unlearning model. FedCARE supports client, instance, and class level unlearning with modest overhead. Extensive experiments on multiple datasets and model architectures under both IID and non-IID settings show that FedCARE achieves effective forgetting, improved utility retention, and reduced relearning risk compared to state of the art FU baselines.
When to Invoke: Refining LLM Fairness with Toxicity Assessment
Jan 14, 2026Large Language Models (LLMs) are increasingly used for toxicity assessment in online moderation systems, where fairness across demographic groups is essential for equitable treatment. However, LLMs often produce inconsistent toxicity judgements for subtle expressions, particularly those involving implicit hate speech, revealing underlying biases that are difficult to correct through standard training. This raises a key question that existing approaches often overlook: when should corrective mechanisms be invoked to ensure fair and reliable assessments? To address this, we propose FairToT, an inference-time framework that enhances LLM fairness through prompt-guided toxicity assessment. FairToT identifies cases where demographic-related variation is likely to occur and determines when additional assessment should be applied. In addition, we introduce two interpretable fairness indicators that detect such cases and improve inference consistency without modifying model parameters. Experiments on benchmark datasets show that FairToT reduces group-level disparities while maintaining stable and reliable toxicity predictions, demonstrating that inference-time refinement offers an effective and practical approach for fairness improvement in LLM-based toxicity assessment systems. The source code can be found at https://aisuko.github.io/fair-tot/.
When to Trust: A Causality-Aware Calibration Framework for Accurate Knowledge Graph Retrieval-Augmented Generation
Jan 14, 2026Knowledge Graph Retrieval-Augmented Generation (KG-RAG) extends the RAG paradigm by incorporating structured knowledge from knowledge graphs, enabling Large Language Models (LLMs) to perform more precise and explainable reasoning. While KG-RAG improves factual accuracy in complex tasks, existing KG-RAG models are often severely overconfident, producing high-confidence predictions even when retrieved sub-graphs are incomplete or unreliable, which raises concerns for deployment in high-stakes domains. To address this issue, we propose Ca2KG, a Causality-aware Calibration framework for KG-RAG. Ca2KG integrates counterfactual prompting, which exposes retrieval-dependent uncertainties in knowledge quality and reasoning reliability, with a panel-based re-scoring mechanism that stabilises predictions across interventions. Extensive experiments on two complex QA datasets demonstrate that Ca2KG consistently improves calibration while maintaining or even enhancing predictive accuracy.
FairGU: Fairness-aware Graph Unlearning in Social Network
Jan 14, 2026Graph unlearning has emerged as a critical mechanism for supporting sustainable and privacy-preserving social networks, enabling models to remove the influence of deleted nodes and thereby better safeguard user information. However, we observe that existing graph unlearning techniques insufficiently protect sensitive attributes, often leading to degraded algorithmic fairness compared with traditional graph learning methods. To address this gap, we introduce FairGU, a fairness-aware graph unlearning framework designed to preserve both utility and fairness during the unlearning process. FairGU integrates a dedicated fairness-aware module with effective data protection strategies, ensuring that sensitive attributes are neither inadvertently amplified nor structurally exposed when nodes are removed. Through extensive experiments on multiple real-world datasets, we demonstrate that FairGU consistently outperforms state-of-the-art graph unlearning methods and fairness-enhanced graph learning baselines in terms of both accuracy and fairness metrics. Our findings highlight a previously overlooked risk in current unlearning practices and establish FairGU as a robust and equitable solution for the next generation of socially sustainable networked systems. The codes are available at https://github.com/LuoRenqiang/FairGU.
FairGE: Fairness-Aware Graph Encoding in Incomplete Social Networks
Jan 14, 2026Graph Transformers (GTs) are increasingly applied to social network analysis, yet their deployment is often constrained by fairness concerns. This issue is particularly critical in incomplete social networks, where sensitive attributes are frequently missing due to privacy and ethical restrictions. Existing solutions commonly generate these incomplete attributes, which may introduce additional biases and further compromise user privacy. To address this challenge, FairGE (Fair Graph Encoding) is introduced as a fairness-aware framework for GTs in incomplete social networks. Instead of generating sensitive attributes, FairGE encodes fairness directly through spectral graph theory. By leveraging the principal eigenvector to represent structural information and padding incomplete sensitive attributes with zeros to maintain independence, FairGE ensures fairness without data reconstruction. Theoretical analysis demonstrates that the method suppresses the influence of non-principal spectral components, thereby enhancing fairness. Extensive experiments on seven real-world social network datasets confirm that FairGE achieves at least a 16% improvement in both statistical parity and equality of opportunity compared with state-of-the-art baselines. The source code is shown in https://github.com/LuoRenqiang/FairGE.
Debiasing Large Language Models via Adaptive Causal Prompting with Sketch-of-Thought
Jan 13, 2026Despite notable advancements in prompting methods for Large Language Models (LLMs), such as Chain-of-Thought (CoT), existing strategies still suffer from excessive token usage and limited generalisability across diverse reasoning tasks. To address these limitations, we propose an Adaptive Causal Prompting with Sketch-of-Thought (ACPS) framework, which leverages structural causal models to infer the causal effect of a query on its answer and adaptively select an appropriate intervention (i.e., standard front-door and conditional front-door adjustments). This design enables generalisable causal reasoning across heterogeneous tasks without task-specific retraining. By replacing verbose CoT with concise Sketch-of-Thought, ACPS enables efficient reasoning that significantly reduces token usage and inference cost. Extensive experiments on multiple reasoning benchmarks and LLMs demonstrate that ACPS consistently outperforms existing prompting baselines in terms of accuracy, robustness, and computational efficiency.
Synthetic Forgetting without Access: A Few-shot Zero-glance Framework for Machine Unlearning
Nov 17, 2025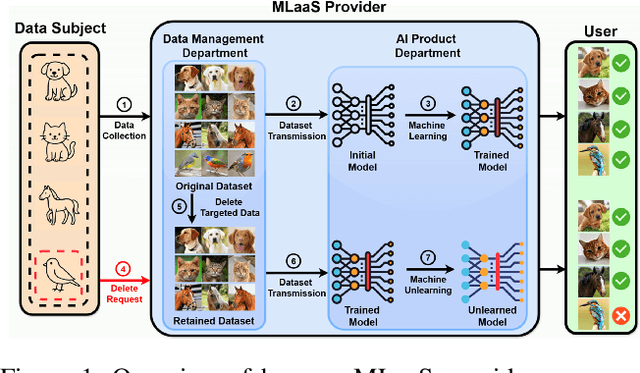
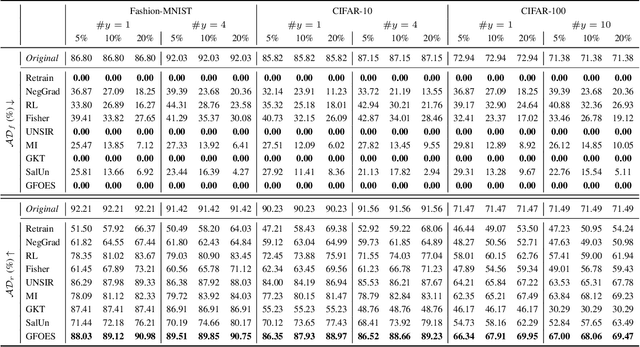
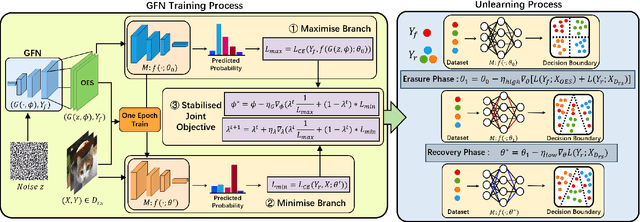
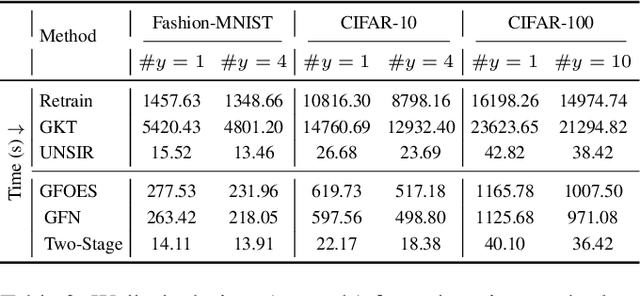
Machine unlearning aims to eliminate the influence of specific data from trained models to ensure privacy compliance. However, most existing methods assume full access to the original training dataset, which is often impractical. We address a more realistic yet challenging setting: few-shot zero-glance, where only a small subset of the retained data is available and the forget set is entirely inaccessible. We introduce GFOES, a novel framework comprising a Generative Feedback Network (GFN) and a two-phase fine-tuning procedure. GFN synthesises Optimal Erasure Samples (OES), which induce high loss on target classes, enabling the model to forget class-specific knowledge without access to the original forget data, while preserving performance on retained classes. The two-phase fine-tuning procedure enables aggressive forgetting in the first phase, followed by utility restoration in the second. Experiments on three image classification datasets demonstrate that GFOES achieves effective forgetting at both logit and representation levels, while maintaining strong performance using only 5% of the original data. Our framework offers a practical and scalable solution for privacy-preserving machine learning under data-constrained conditions.
Unbiased Reasoning for Knowledge-Intensive Tasks in Large Language Models via Conditional Front-Door Adjustment
Aug 23, 2025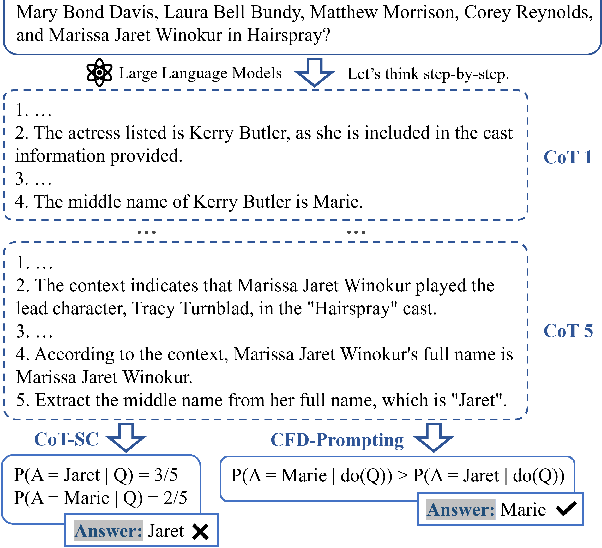
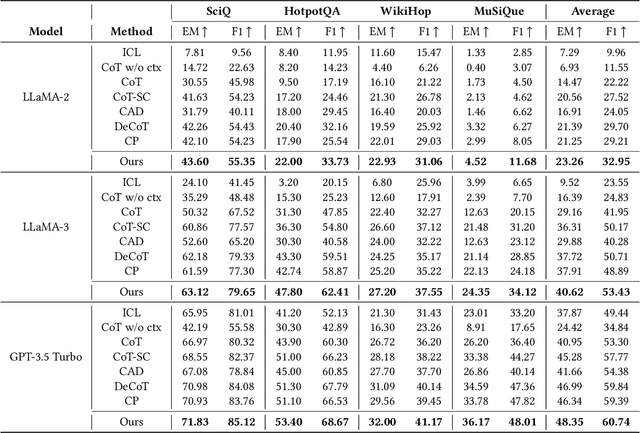
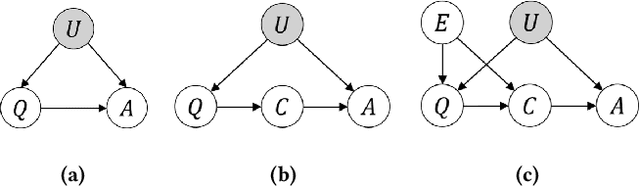
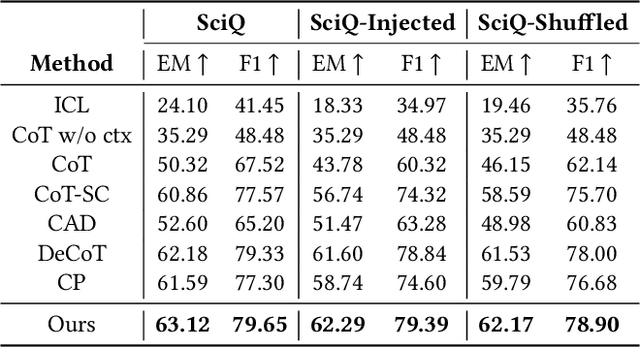
Large Language Models (LLMs) have shown impressive capabilities in natural language processing but still struggle to perform well on knowledge-intensive tasks that require deep reasoning and the integration of external knowledge. Although methods such as Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) have been proposed to enhance LLMs with external knowledge, they still suffer from internal bias in LLMs, which often leads to incorrect answers. In this paper, we propose a novel causal prompting framework, Conditional Front-Door Prompting (CFD-Prompting), which enables the unbiased estimation of the causal effect between the query and the answer, conditional on external knowledge, while mitigating internal bias. By constructing counterfactual external knowledge, our framework simulates how the query behaves under varying contexts, addressing the challenge that the query is fixed and is not amenable to direct causal intervention. Compared to the standard front-door adjustment, the conditional variant operates under weaker assumptions, enhancing both robustness and generalisability of the reasoning process. Extensive experiments across multiple LLMs and benchmark datasets demonstrate that CFD-Prompting significantly outperforms existing baselines in both accuracy and robustness.
Revisiting Pre-processing Group Fairness: A Modular Benchmarking Framework
Aug 21, 2025As machine learning systems become increasingly integrated into high-stakes decision-making processes, ensuring fairness in algorithmic outcomes has become a critical concern. Methods to mitigate bias typically fall into three categories: pre-processing, in-processing, and post-processing. While significant attention has been devoted to the latter two, pre-processing methods, which operate at the data level and offer advantages such as model-agnosticism and improved privacy compliance, have received comparatively less focus and lack standardised evaluation tools. In this work, we introduce FairPrep, an extensible and modular benchmarking framework designed to evaluate fairness-aware pre-processing techniques on tabular datasets. Built on the AIF360 platform, FairPrep allows seamless integration of datasets, fairness interventions, and predictive models. It features a batch-processing interface that enables efficient experimentation and automatic reporting of fairness and utility metrics. By offering standardised pipelines and supporting reproducible evaluations, FairPrep fills a critical gap in the fairness benchmarking landscape and provides a practical foundation for advancing data-level fairness research.
FairDRL-ST: Disentangled Representation Learning for Fair Spatio-Temporal Mobility Prediction
Aug 11, 2025As deep spatio-temporal neural networks are increasingly utilised in urban computing contexts, the deployment of such methods can have a direct impact on users of critical urban infrastructure, such as public transport, emergency services, and traffic management systems. While many spatio-temporal methods focus on improving accuracy, fairness has recently gained attention due to growing evidence that biased predictions in spatio-temporal applications can disproportionately disadvantage certain demographic or geographic groups, thereby reinforcing existing socioeconomic inequalities and undermining the ethical deployment of AI in public services. In this paper, we propose a novel framework, FairDRL-ST, based on disentangled representation learning, to address fairness concerns in spatio-temporal prediction, with a particular focus on mobility demand forecasting. By leveraging adversarial learning and disentangled representation learning, our framework learns to separate attributes that contain sensitive information. Unlike existing methods that enforce fairness through supervised learning, which may lead to overcompensation and degraded performance, our framework achieves fairness in an unsupervised manner with minimal performance loss. We apply our framework to real-world urban mobility datasets and demonstrate its ability to close fairness gaps while delivering competitive predictive performance compared to state-of-the-art fairness-aware methods.